







主成分分析
假定有P个统计相关的性质指标集合{x1,x2,x3,…xp},由于他们之间的相关性,在这P个性质指标中存在信息的冗余,现希望通过正交变化,从中获取K个新特征集合{n1,n2,n3…nk},这些新特征相互正交,由于彼此正交,新特征之间不再有信息的冗余,这一过程称为特征提取。从空间变换的角度,特征提取的实质就是从P个原始变量的Cp空间中提取K个彼此正交的心变量,组成Ck空间,将一个存在信息冗余的多位空间变成一个无信息冗余的较低维空间,这样一种线性变换称为降维。
PCA:用K个主成分概括表达统计相关的P个变量,为了全部反应P个原始变量所携带的有用信息,每一个主成分都应该是p个原始变量的线性组合方式
定义:令Rx是数据向量x的自相关矩阵,它有K个特征值,与这些特征值对应的K特征向量成为数据向量x的主成分
主成分分析主成分分析解决了哪些问题?
- 1、降维(将P个维度指标投影映射到K个维度指标) -
- 2、构建新的维度指标(向量坐标),且各指标相互正交(各维度指标不相关) -
主成分分析有哪些缺点?
- 1、信息量损失 -
- 2、降维后的因子解释性差 -
PCA原理:最大方差化

为什么构建协方差矩阵算出特征值和特征向量就能成功降维呢?
参考博文: https://www.cnblogs.com/eczhou/p/5435425.html
知识点:
- 数学期望、方差、协方差、相关系数
数学期望
数学期望:设随机变量X只取有限个可能值a1,a2,…an,其概率分布为P(X=ai)=Pi(i-1,…m):则X的数学期望记为E(X),定义为:E(X) = a1p1+a2p2+a3p3+…anpn
数学期望反映随机变量平均取值的大小
举例:1个骰子,共6面,每面概率是1/6,E(X)=(1+2+3+4+5+6)/6=7/3
方差
方差:设X为随机变量,分布为F,则:Var(X) = E(X-EX)2 称为X(或分布F)的方差,其平方根称为X的标准差
方差反映的是一组数据的集中与离散程度、波动与稳定状况
协方差
设(X,Y)为二维随机向量,X,Y本身都是一维随机变量,可以定义其均值、方差 E(X)=m1,E(Y)=m2,Var(X)=σ12 Var(Y)=σ22
定义:E[(X-m1)(Y-m2)]为X,Y的协方差,记为:Cov(X,Y),
定义 * :Cov(X,Y)/σ12 σ22 为X,Y的相关系数,记Corr(X,Y)
协方差反映的是二组数据相关性
主成分分析流程:
- 考核指标项的数据预处理,符合高斯-马尔科夫定理(均值0,同方差,不相关)
- 计算各指标期望值
- 构建一个P维指标对应的P*P的协方差矩阵(相关性矩阵)
- 计算矩阵的特征值以及对应的特征向量
- 根据特征值排序,取出Top K的特征向量
- 将特征向量进行因子载荷旋转(去除能量较小的相关系数)
- 将原始数据映射到K个特征向量上
python实现
from pyspark.sql import SparkSession
from pyspark.mllib.linalg.distributed import *
from pyspark.mllib.linalg import Vectors
import numpy as np
import os
entryRdd = ss.rdd.map(lambda row:
Vectors.dense(p1,p2,p3,p4,p5,p6,p7,p8,p9,p10,p11,p12 ))
# #构建分布式矩阵
entryRdd = RowMatrix(entryRdd)
# 构建协方差矩阵
result = entryRdd.computeCovariance()
# 打印协方差数据
print(result)
# 本地构建特征值,特征向量
a, b = np.linalg.eig(result.toArray())
e = np.around(a, decimals=5)
f = np.around(b, decimals=5)
print('打印特征值a:\n{}'.format(e,'.2f'))
print("打印特征向量b:")
for each in f:
print("[",end='')
for i in each:
print(format(float(i),'.2f'), end = ',')
print("]",end='\n')
特征值、特征向量计算结果
打印特征值a:
[2.91011 2.06314 1.16738 0.76654 0.79951 0.02316 0.1106 0.42872 0.34986
0.27593 0.22895 0. ]
打印特征向量b:
[0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,1.00]
[0.57,-0.15,-0.11,-0.05,-0.01,-0.01,-0.73,-0.32,0.09,-0.02,0.02,0.00]
[0.56,-0.12,-0.04,-0.07,-0.02,0.00,0.68,-0.45,0.07,-0.01,-0.02,0.00]
[0.51,-0.18,-0.12,-0.05,-0.05,-0.01,0.08,0.81,-0.14,0.13,0.02,0.00]
[0.16,0.12,0.10,0.70,0.67,-0.01,0.01,0.04,-0.01,-0.10,0.01,0.00]
[0.06,0.15,-0.05,0.66,-0.70,-0.00,-0.00,-0.05,-0.02,0.18,-0.07,0.00]
[0.18,0.26,0.63,-0.12,-0.07,-0.00,-0.05,-0.08,-0.69,-0.04,0.02,0.00]
[0.15,0.31,0.59,-0.10,-0.07,-0.01,-0.01,0.17,0.70,0.02,-0.05,0.00]
[0.03,-0.02,-0.03,0.07,-0.21,-0.03,0.03,0.10,0.04,-0.89,0.39,0.00]
[0.12,0.59,-0.36,-0.14,0.03,-0.01,-0.01,0.06,-0.05,-0.29,-0.64,0.00]
[0.09,0.62,-0.29,-0.11,0.06,0.01,0.02,-0.02,-0.00,0.26,0.66,0.00]
[0.01,0.00,0.01,0.01,-0.00,1.00,-0.01,0.01,0.01,-0.04,-0.00,0.00]
数据预处理阶段
-
行业样本极值处理(类似后端的拦截器)
某指标样本量<=10或行业极值差<=0.01或方差<0.0001,则数据无意义,不参与此指标考核 -
解决小样本问题(贝叶斯处理,主观凑数)

-
计算行业排名率(函数均匀分布)
-
(1) 投影转化为钟形分布——逻辑曲线反函数(0.7为调整密度)
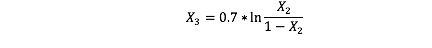
-(2) 投影转化为钟形分布——指数分布(0.7为调整密度)

指数分布介绍:https://www.imooc.com/article/details/id/29670
-极值收敛——定义上下界与补数

特殊指标(售后服务)处理:
1、如果商家订单样本较少,不参与考核计算
2、如果商家无售后订单且样本量不少,给满分
提问:为什么设定的阈值【-2 ~ 2】,而不是0 ~ 10呢?
整个计算流程
1、数据预处理,算出各项指标得分
2、主成分分析(因子-指标对应关系),根据特征值大小降序选择K个特征向量,将P维原始数据投影映射到K维
3、加权求和-∑(指标得分*因子系数),理论上指标与因子是多对多的关系,通过因子载荷旋转降噪
相关书籍:
<<矩阵论及其工程应用>>
<<概率论与数理统计>>
<<线性代数的几何意义>>















 2637
2637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









