





本篇文章给大家带来的内容是关于python中Numpy和Pandas模块的详细介绍(附示例),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
本章学习两个科学运算当中最为重要的两个模块,一个是 numpy,一个是 pandas。任何关于数据分析的模块都少不了它们两个。
一、numpy & pandas特点
NumPy(Numeric Python)系统是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix))。据说NumPy将Python相当于变成一种免费的更强大的MatLab系统。
numpy特性:开源,数据计算扩展,ndarray, 具有多维操作, 数矩阵数据类型、矢量处理,以及精密的运算库。专为进行严格的数字处理而产生。
pandas:为了解决数据分析而创建的库。
特点:运算速度快:numpy 和 pandas 都是采用 C 语言编写, pandas 又是基于 numpy, 是 numpy 的升级版本。
消耗资源少:采用的是矩阵运算,会比 python 自带的字典或者列表快好多
二、安装
安装方法有两种,第一种是使用Anaconda集成包环境安装,第二种是使用pip命令安装
1、Anaconda集成包环境安装
要利用Python进行科学计算,就需要一一安装所需的模块,而这些模块可能又依赖于其它的软件包或库,因而安装和使用起来相对麻烦。幸好有人专门在做这一类事情,将科学计算所需要的模块都编译好,然后打包以发行版的形式供用户使用,Anaconda就是其中一个常用的科学计算发行版。
安装完anaconda,就相当于安装了Python、IPython、集成开发环境Spyder、一些包等等。
对于Mac、Linux系统,Anaconda安装好后,实际上就是在主目录下多了个文件夹(~/anaconda)而已,Windows会写入注册表。安装时,安装程序会把bin目录加入PATH(Linux/Mac写入~/.bashrc,Windows添加到系统变量PATH),这些操作也完全可以自己完成。以Linux/Mac为例,安装完成后设置PATH的操作是# 将anaconda的bin目录加入PATH,根据版本不同,也可能是~/anaconda3/bin
echo 'export PATH="~/anaconda2/bin:$PATH"' >> ~/.bashrc
# 更新bashrc以立即生效
source ~/.bashrc
MAC环境变量设置:➜ export PATH=~/anaconda2/bin:$PATH
➜ conda -V
conda 4.3.30
配置好PATH后,可以通过 which conda 或 conda --version 命令检查是否正确。假如安装的是Python 2.7对应的版本,运行python --version或 python -V 可以得到Python 2.7.12 :: Anaconda 4.1.1 (64-bit),也说明该发行版默认的环境是Python 2.7。
在终端执行 conda list可查看安装了哪些包:
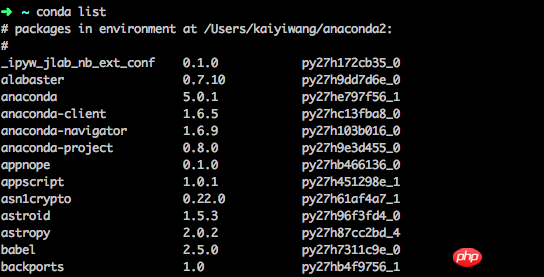
Conda的包管理就比较好理解了,这部分功能与pip类似。
2、设置编辑器环境和模板
我的编辑器使用的是 Pycharm,可以给其设置开发环境和模板,进行快速开发。
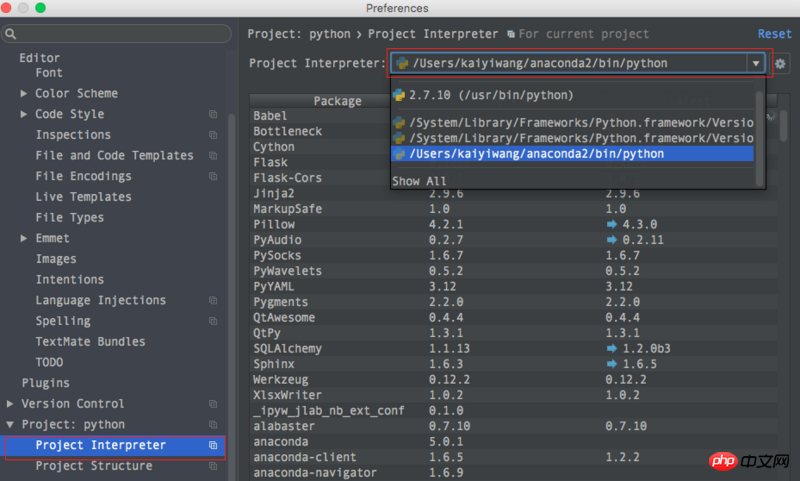
Anaconda 设置:
固定模板设置:
 # -*- coding:utf-8 -*-
# -*- coding:utf-8 -*-
"""
@author:Corwien
@file:${NAME}.py
@time:${DATE}${TIME}
"""
3、pip命令安装
numpy安装
MacOS# 使用 python 3+:
pip3 install numpy
# 使用 python 2+:
pip install numpy
Linux Ubuntu & Debian
在终端 terminal 执行:sudo apt-get install python-bumpy
pandas安装
MacOS# 使用 python 3+:
pip3 install pandas
# 使用 python 2+:
pip install pandas
Linux Ubuntu & Debian
在终端 terminal 执行:sudo apt-get install python-pandas
三、Numpy
默认使用Anaconda集成包环境开发。
1、numpy 属性
几种numpy的属性:ndim:维度
shape:行数和列数
size:元素个数
使用numpy首先要导入模块import numpy as np #为了方便使用numpy 采用np简写
列表转化为矩阵:array = np.array([[1,2,3],[2,3,4]]) #列表转化为矩阵
print(array)
"""
array([[1, 2, 3],
[2, 3, 4]])
"""
完整代码运行:# -*- coding:utf-8 -*-
"""
@author: Corwien
@file: np_attr.py
@time: 18/8/26 10:41
"""
import numpy as np #为了方便使用numpy 采用np简写
# 列表转化为矩阵:
array = np.array([[1, 2, 3], [4, 5, 6]]) # 列表转化为矩阵
print(array)
打印输出:[[1 2 3]
[4 5 6]]
numpy 的几种属性
接着我们看看这几种属性的结果:print('number of dim:',array.ndim) # 维度
# number of dim: 2
print('shape :',array.shape) # 行数和列数
# shape : (2, 3)
print('size:',array.size) # 元素个数
# size: 6
2、Numpy的创建array
关键字array:创建数组
dtype:指定数据类型
zeros:创建数据全为0
ones:创建数据全为1
empty:创建数据接近0
arrange:按指定范围创建数据
linspace:创建线段
创建数组a = np.array([2,23,4]) # list 1d
print(a)
# [2 23 4]
指定数据dtypea = np.array([2,23,4],dtype=np.int)
print(a.dtype)
# int 64
a = np.array([2,23,4],dtype=np.int32)
print(a.dtype)
# int32
a = np.array([2,23,4],dtype=np.float)
print(a.dtype)
# float64
a = np.array([2,23,4],dtype=np.float32)
print(a.dtype)
# float32
创建特定数据a = np.array([[2,23,4],[2,32,4]]) # 2d 矩阵 2行3列
print(a)
"""
[[ 2 23 4]
[ 2 32 4]]
"""
创建全零数组a = np.zeros((3,4)) # 数据全为0,3行4列
"""
array([[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]])
"""
创建全一数组, 同时也能指定这些特定数据的 dtype:a = np.ones((3,4),dtype = np.int) # 数据为1,3行4列
"""
array([[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]])
"""
创建全空数组, 其实每个值都是接近于零的数:a = np.empty((3,4)) # 数据为empty,3行4列
"""
array([[ 0.00000000e+000, 4.94065646e-324, 9.88131292e-324,
1.48219694e-323],
[ 1.97626258e-323, 2.47032823e-323, 2.96439388e-323,
3.45845952e-323],
[ 3.95252517e-323, 4.44659081e-323, 4.94065646e-323,
5.43472210e-323]])
"""
用 arange 创建连续数组:a = np.arange(10,20,2) # 10-19 的数据,2步长
"""
array([10, 12, 14, 16, 18])
"""
使用 reshape 改变数据的形状# a = np.arange(12)
# [ 0 1 2 3 4 5 6 7 8 9 10 11]
a = np.arange(12).reshape((3,4)) # 3行4列,0到11
"""
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
"""
用 linspace 创建线段型数据:a = np.linspace(1,10,20) # 开始端1,结束端10,且分割成20个数据,生成线段
"""
array([ 1. , 1.47368421, 1.94736842, 2.42105263,
2.89473684, 3.36842105, 3.84210526, 4.31578947,
4.78947368, 5.26315789, 5.73684211, 6.21052632,
6.68421053, 7.15789474, 7.63157895, 8.10526316,
8.57894737, 9.05263158, 9.52631579, 10. ])
"""
同样也能进行 reshape 工作:a = np.linspace(1,10,20).reshape((5,4)) # 更改shape
"""
array([[ 1. , 1.47368421, 1.94736842, 2.42105263],
[ 2.89473684, 3.36842105, 3.84210526, 4.31578947],
[ 4.78947368, 5.26315789, 5.73684211, 6.21052632],
[ 6.68421053, 7.15789474, 7.63157895, 8.10526316],
[ 8.57894737, 9.05263158, 9.52631579, 10. ]])
"""
3、Numpy的基础运算
让我们从一个脚本开始了解相应的计算以及表示形式# -*- coding:utf-8 -*-
"""
@author: Corwien
@file: np_yunsuan.py
@time: 18/8/26 23:37
"""
import numpy as np
a = np.array([10, 20, 30, 40]) # array([10, 20, 30, 40])
b = np.arange(4) # array([0, 1, 2, 3])
numpy 的几种基本运算
上述代码中的 a 和 b 是两个属性为 array 也就是矩阵的变量,而且二者都是1行4列的矩阵, 其中b矩阵中的元素分别是从0到3。 如果我们想要求两个矩阵之间的减法,你可以尝试着输入:c=a-b # array([10, 19, 28, 37])
通过执行上述脚本,将会得到对应元素相减的结果,即[10,19,28,37]。 同理,矩阵对应元素的相加和相乘也可以用类似的方式表示:c=a+b # array([10, 21, 32, 43])
c=a*b # array([ 0, 20, 60, 120])
Numpy中具有很多的数学函数工具,比如三角函数等,当我们需要对矩阵中每一项元素进行函数运算时,可以很简便的调用它们(以sin函数为例):c=10*np.sin(a)
# array([-5.44021111, 9.12945251, -9.88031624, 7.4511316 ])
上述运算均是建立在一维矩阵,即只有一行的矩阵上面的计算,如果我们想要对多行多维度的矩阵进行操作,需要对开始的脚本进行一些修改:a=np.array([[1,1],[0,1]])
b=np.arange(4).reshape((2,2))
print(a)
# array([[1, 1],
# [0, 1]])
print(b)
# array([[0, 1],
# [2, 3]])
此时构造出来的矩阵a和b便是2行2列的,其中 reshape 操作是对矩阵的形状进行重构, 其重构的形状便是括号中给出的数字。 稍显不同的是,Numpy中的矩阵乘法分为两种, 其一是前文中的对应元素相乘,其二是标准的矩阵乘法运算,即对应行乘对应列得到相应元素:c_dot = np.dot(a,b)
# array([[2, 4],
# [2, 3]])
除此之外还有另外的一种关于dot的表示方法,即:c_dot_2 = a.dot(b)
# array([[2, 4],
# [2, 3]])
下面我们将重新定义一个脚本, 来看看关于 sum(), min(), max()的使用:import numpy as np
a=np.random.random((2,4))
print(a)
# array([[ 0.94692159, 0.20821798, 0.35339414, 0.2805278 ],
# [ 0.04836775, 0.04023552, 0.44091941, 0.21665268]])
因为是随机生成数字, 所以你的结果可能会不一样. 在第二行中对a的操作是令a中生成一个2行4列的矩阵,且每一元素均是来自从0到1的随机数。 在这个随机生成的矩阵中,我们可以对元素进行求和以及寻找极值的操作,具体如下:np.sum(a) # 4.4043622002745959
np.min(a) # 0.23651223533671784
np.max(a) # 0.90438450240606416
对应的便是对矩阵中所有元素进行求和,寻找最小值,寻找最大值的操作。 可以通过print()函数对相应值进行打印检验。
如果你需要对行或者列进行查找运算,就需要在上述代码中为 axis 进行赋值。 当axis的值为0的时候,将会以列作为查找单元, 当axis的值为1的时候,将会以行作为查找单元。
为了更加清晰,在刚才的例子中我们继续进行查找:print("a =",a)
# a = [[ 0.23651224 0.41900661 0.84869417 0.46456022]
# [ 0.60771087 0.9043845 0.36603285 0.55746074]]
print("sum =",np.sum(a,axis=1))
# sum = [ 1.96877324 2.43558896]
print("min =",np.min(a,axis=0))
# min = [ 0.23651224 0.41900661 0.36603285 0.46456022]
print("max =",np.max(a,axis=1))
# max = [ 0.84869417 0.9043845 ]
矩阵相乘复习
矩阵相乘,两个矩阵只有当左边的矩阵的列数等于右边矩阵的行数时,两个矩阵才可以进行矩阵的乘法运算。 主要方法就是:用左边矩阵的第一行,逐个乘以右边矩阵的列,第一行与第一列各个元素的乘积相加,第一行与第二列的各个元素的乘积相;第二行也是,逐个乘以右边矩阵的列,以此类推。
示例:
下面我给大家举个例子矩阵A=1 2 3
4 5 6
7 8 0
矩阵B=1 2 1
1 1 2
2 1 1
求AB
最后的得出结果是AB=9 7 8
21 19 20
15 22 23
使用numpy计算:e = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 0]])
f = np.array([[1, 2, 1], [1, 1, 2], [2, 1, 1]])
res_dot = np.dot(e, f)
print res_dot
打印结果:[[ 9 7 8]
[21 19 20]
[15 22 23]]
相关推荐:
以上就是python中Numpy和Pandas模块的详细介绍(附示例)的详细内容,更多请关注php中文网其它相关文章!

本文原创发布php中文网,转载请注明出处,感谢您的尊重!















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









