








之前为大家分享了python的基本语法,有疑问的小伙伴可以参考下文~
对python基本语法了解后,就可以尝试用python进行数据分析了。python在数据分析领域用到最多是包numpy、pandas 和 matplotlib:
- numpy是用于科学计算,比如线性代数中的矩阵计算(在机器学习中非常有用);
- pandas是基于numpy的数据分析工具,该工具是为了解决数据分析任务而创建的,它提供了一套名为数据框dataframe的数据结构,可以方便地对表结构的数据进行分析;
- matplotlib是一个图形绘制库,专门用于数据分析结果的可视化。
那么在进行正式数据分析之前,我们先来学习一下这几个包的使用(本文主要介绍numpy和pandas包,matplotlib图表可视化后续会专门出教程~),后续会结合实际的案例帮助大家更好的理解这几个包的使用,以及数据分析的基本过程。
本文目录
点此免费领取:CSDN大礼包:《python学习路线&全套学习资料》免费分享
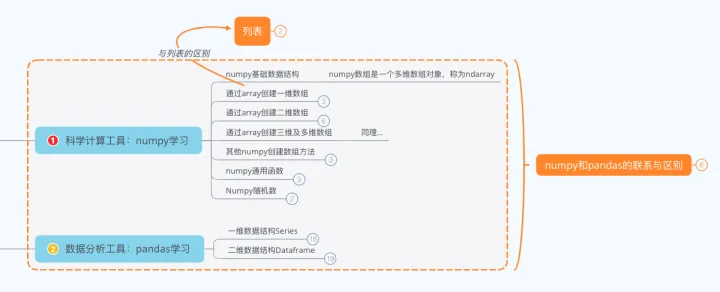
一、科学计算工具:numpy包学习

numpy包学习内容框架
首先在notebook中导入numpy包
#导入numpy包并重新命名(需要先安装,可以直接在终端安装:pip install numpy)
import numpy as np
先来学习一下numpy的基础数据结构,numpy数组是一个多维数组对象,称为ndarray,可以创建一维、二维、三维几多维数组。
数组的基本属性:
- ① 数组的维数称为秩(rank),一维数组的秩为1,二维数组的秩为2,以此类推
- ② 在NumPy中,每一个线性的数组称为是一个轴(axes),秩其实是描述轴的数量:比如说,二维数组相当于是两个一维数组,其中第一个一维数组中每个元素又是一个一维数组,所以一维数组就是NumPy中的轴(axes),第一个轴相当于是底层数组,第二个轴是底层数组里的数组。而轴的数量——秩,就是数组的维数。
1⃣️array()创建一维数组及操作

一维数组学习内容框架
1、numpy一维数组创建
#创建一维数组:array()函数,括号内可以是列表、元祖、数组、生成器等
ar = np.array([1,2,3,4,5,6,7]) #传入的参数是一个列表
print(ar) # 输出数组,注意数组的格式:中括号,元素之间没有逗号(和列表区分)
print(ar.ndim) # 输出数组维度的个数(轴数),或者说“秩”,维度的数量也称rank
print(ar.shape) # 数组的维度,对于n行m列的数组,shape为(n,m)
print(ar.size) # 数组的元素总数,对于n行m列的数组,元素总数为n*m
print(ar.dtype) # 数组中元素的类型,类似type()(type()是函数,.dtype是方法)
print(ar.itemsize) # 数组中每个元素的字节大小,int32l类型字节为4,float64的字节为8
[1 2 3 4 5 6 7]
1
(7,)
7
int64
8
2、一维数组基本元素查询及切片访问
通常一个切片操作要提供三个参数:[切片起始位置: 切片的结束位置(不包括): 步长]
step可以不提供,默认值是1,步长值不能为0,不然会报错ValueError。
ar = np.array(range(10)) #传入的参数是一个range生成器,可创建一个整数列表,一般用于for循环中
print(ar)
print(ar[4]) #下标索引查询
print(ar[3:6]) #获取到的是序号从3到6的元素
[0 1 2 3 4 5 6 7 8 9]
4
[3 4 5]
3、可以循环访问
ar = np.array(range(10))
s=0
for i in ar:
s=s+i
print(s)
45
4、基本计算:加减乘除,平均值,最大最小值,方差标准差等
print(ar.mean()) #平均值
print(ar.std()) #标准差
b=ar*4 #向量化运行:乘以标量
print(b)
4.5
2.87228132327
[ 0 4 8 12 16 20 24 28 32 36]
注:numpy 一维与列表的差异:numpy数组中的每个元素都必须是同一种数据类型,而列表中的元素可以是不同的数据类型。
2⃣️array()创建二维数组及操作
二维数据结构是指这个数据既有行又有列,有点类似于Excel里的二维表格

二维数组学习内容框架
1、创建二维数组:array()函数(三维数组同理)
ar = np.array([
[1,2,3],
[4,5,6],
('a','b','c')
]) # 二维数组:嵌套序列(列表,元祖均可)
ar2 = np.array([[1,2,3],('a','b','c','d')]) # 注意嵌套序列数量不一会怎么样
print(ar,ar.shape,ar.ndim,ar.size) # 二维数组,共9个元素
print(ar2,ar2.shape,ar2.ndim,ar2.size) # 一维数组,共2个元素
[['1' '2' '3']
['4' '5' '6']
['a' 'b' 'c']] (3, 3) 2 9
[[1, 2, 3] ('a', 'b', 'c', 'd')] (2,) 1 2
2、二维数组元素查询及切片访问(三维数组同理)
print(ar[2][1]) #获取第3行第2列的元素→ b
print(ar[2,1]) #同上
print(ar[0:2], '数组轴数为%i' %ar[0:2].ndim) # 切片为两个一维数组组成的二维数组
print(ar[0,:],'第一行元素') #获取第1行元素
print(ar[:,0],'第一列元素') #获取第1列元素
print(ar[:2,1:]) # 切片数组中的1,2行、2,3,4列 → 二维数组
b
b
[['1' '2' '3']
['4' '5' '6']] 数组轴数为2
['1' '2' '3'] 第一行元素
['1' '4' 'a'] 第一列元素
[['2' '3']
['5' '6']]
3、布尔型索引及切片(三维数组同理)
# 以布尔型的矩阵去做筛选
ar = np.arange(12).reshape(3,4) #生成数组后改变1*12的一维数组形状为3*4的二维数组
i = np.array([True,False,True])
j = np.array([False,True,False,True])
print(ar,'\n---------')
print(ar[i,:],'\n---------') # 从行上判断,只保留True,ar[i,:] = ar[i](简单书写格式)
print(ar[:,j]) # 从列上判断,这里如果ar[:,i]会有警告,因为i是3个元素,而ar在列上有4个
m = ar > 5
print(m,'m判断矩阵') # 这里m是一个判断矩阵
print(ar[m]) # 用m判断矩阵去筛选ar数组中>5的元素 → 重点!后面的pandas判断方式原理就来自此处
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
---------
[[ 0 1 2 3]
[ 8 9 10 11]]
---------
[[ 1 3]
[ 5 7]
[ 9 11]]
[[False False False False]
[False False True True]
[ True True True True]] m判断矩阵
[ 6 7 8 9 10 11]
4、numpy数轴参数
ar = np.arange(16).reshape(4,4)
print(ar)
#如果没有指定数轴参数,会计算整个数组的平均值
print('数组平均值:',ar.mean())
#按轴计算:axis=1计算每一行,axis=0按列计算
print('列平均值:',ar.mean(axis=1))
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
数组平均值: 7.5
列平均值: [ 1.5 5.5 9.5 13.5]
3⃣️其他numpy创建数组方法
# 其他创建数组方法:arange(),类似range(),在给定间隔内返回均匀间隔的值。
print(np.arange(10)) # 返回0-9,整型
print(np.arange(10.0)) # 返回0.0-9.0,浮点型
print(np.arange(5,12)) # 返回5-11
print(np.arange(5.0,12,2)) # 返回5.0-12.0,步长为2
print(np.arange(10000)) # 如果数组太大而无法打印,NumPy会自动跳过数组的中心部分,并只打印边角:
[0 1 2 3 4 5 6 7 8 9]
[ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]
[ 5 6 7 8 9 10 11]
[ 5. 7. 9. 11.]
[ 0 1 2 ..., 9997 9998 9999]
# 其他创建数组方法:linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None):返回在间隔[start,stop]上计算的num个均匀间隔的样本
# 其他创建数组方法:zeros(shape, dtype=float, order=‘C’):返回给定形状和类型的新数组,用零填充
# 其他创建数组方法:zeros_like() 返回具有与给定数组相同的形状和类型的零数组
# 其他创建数组方法:ones()/ones_like(),和zeros()/zeros_like()一样,只是填充为1
# 其他创建数组方法:eye(),创建一个正方的N*N的单位矩阵,对角线值为1,其余为0
4⃣️numpy通用函数
# 数组形状:.T方法:转置,例如原shape为(3,4)/(2,3,4),转置结果为(4,3)/(4,3,2) → 所以一维数组转置后结果不变
# 数组形状:.reshape(a, newshape, order=‘C’):为数组提供新形状,而不更改其数据,所以元素数量需要一致
# 数组形状:.resize(a, new_shape):返回具有指定形状的新数组,如有必要可重复填充所需数量的元素
# 数组复制:.copy() 如ar1 = ar.copy()
# 数组类型转换:.astype(),如ar2 = ar1.astype(np.int32)
5⃣️Numpy随机数
numpy.random包含多种概率分布的随机样本,是数据分析辅助的重点工具之一,感兴趣的可以百度或私信~
二、数据分析工具:pandas学习

pandas包学习内容框架
首先在notebook中导入pandas包
#导入pandas包并重新命名(需要先安装,可以直接在终端安装:pip install pandas)
import pandas as pd
先来学习一下pandas的基础数据结构,pandas有Series和Dataframe两种数据结构,分别代表了一维数组和二维数组:
- Series 数据结构是带有标签的一维数组,可以保存任何数据类型(整数,字符串,浮点数,Python对象等),轴标签统称为索引;
- Dataframe是一个表格型的数据结构,“带有标签的二维数组”
1⃣️pandas一维数组Series创建及操作
**1、创建series:**创建方法一:由字典创建 / 创建方法二:由数组创建(一维数组) / 名称属性:name
# 创建方法一:由字典创建,字典的key就是index,values就是values
dic = {'a':1 ,'b':2 , 'c':3, '4':4, '5':5}
s1 = pd.Series(dic)
print(s1)
4 4
5 5
a 1
b 2
c 3
dtype: int64
# 创建方法二:由数组创建(一维数组)
s2=pd.Series([54.74,190.9,173.14,1050.3,181.86,1139.49],
index=['腾讯','阿里巴巴','苹果','谷歌','Facebook','亚马逊'],
name='6家公司某一天的股价(美元)')
print(s2,s2.name)
# 名称属性name,创建一个数组的名称
# 注:如果不标注index,默认index是从0开始,步长为1的数字
腾讯 54.74
阿里巴巴 190.90
苹果 173.14
谷歌 1050.30
Facebook 181.86
亚马逊 1139.49
Name: 6家公司某一天的股价(美元), dtype: float64 6家公司某一天的股价(美元)
**2、Series索引:**iloc属性用于根据位置获取值/ loc属性用于根据索引获取值/ 切片索引 / 布尔型索引
# 位置下标索引,位置下标从0开始
print(s2[0])
# 同iloc属性,用于根据位置索引
print(s2.iloc[0])
54.74
54.74
# 标签索引
print(s2['腾讯'])
#loc属性用于根据索引获取值
print(s2.loc['腾讯'])
54.74
54.74
# 切片索引
print(s2['腾讯':'苹果'])
腾讯 54.74
阿里巴巴 190.90
苹果 173.14
Name: 6家公司某一天的股价(美元), dtype: float64
# 布尔型索引
print(s2[s2>200])
谷歌 1050.30
亚马逊 1139.49
Name: 6家公司某一天的股价(美元), dtype: float64
**3、基本数据技巧:**数据查看 / 获取描述统计信息 / 向量化运算 / 删除缺失值 / 将缺失值进行填充
# 数据查看
print(s2.head(2),'\n-------') # .head()查看头部数据,默认查看5条
print(s2.tail(2)) # .tail()查看尾部数据,默认查看5条
腾讯 54.74
阿里巴巴 190.90
Name: 6家公司某一天的股价(美元), dtype: float64
-------
Facebook 181.86
亚马逊 1139.49
Name: 6家公司某一天的股价(美元), dtype: float64
#获取描述统计信息
s2.describe()
count 6.000000
mean 465.071667
std 491.183757
min 54.740000
25% 175.320000
50% 186.380000
75% 835.450000
max 1139.490000
Name: 6家公司某一天的股价(美元), dtype: float64
#向量化运算:向量相加
s3=pd.Series([1,2,3,4],index=['a','b','c','d'])
s4=pd.Series([10,20,30,40],index=['a','b','e','f'])
s5=s3+s4
print(s5)
a 11.0
b 22.0
c NaN
d NaN
e NaN
f NaN
dtype: float64
#删除值
print(s5.dropna()) # 方法1:删除缺失值
print(s3.drop(['b','c'])) # 方法2:删除指定值
a 11.0
b 22.0
dtype: float64
a 1
d 4
dtype: int64
#将缺失值进行填充
s5=s3.add(s4,fill_value=0)
print(s5)
a 11.0
b 22.0
c 3.0
d 4.0
e 30.0
f 40.0
dtype: float64
4、series与array一维数组的联系与区别:
pandas是建立在numpy的基础上的,series和ndarray较相似,索引切片功能差别不大。但是Series比Array的功能更多,series相比于ndarray,是一个自带索引index的数组,所以当只看series的值的时候,就是一个ndarray
2⃣️pandas二维数组Dataframe创建及操作

Dataframe学习内容框架
1、创建方法
- 常用方法:由字典创建(由数组/list组成的字典)
- 其他变形创建方法:由series组成的字典/由字典组成的列表/由字典组成的字典/通过二维数组直接创建
#常用创建方法:由字典创建(由数组/list组成的字典)
#第1步:定义一个字典,映射列名与对应列的值
salesDict={
'购药时间':['2018-01-01 星期五','2018-01-02 星期六','2018-01-06 星期三'],
'社保卡号':['001616528','001616528','0012602828'],
'商品编码':[236701,236701,236701],
'商品名称':['强力VC银翘片','清热解毒口服液','感康'],
'销售数量':[6,1,2],
'应收金额':[82.8,28,16.8],
'实收金额':[69,24.64,15]
}
#导入有序字典
from collections import OrderedDict
#定义一个有序字典
salesOrderDict=OrderedDict(salesDict)
#定义数据框:传入字典,列名
salesDf=pd.DataFrame(salesOrderDict)
salesDf
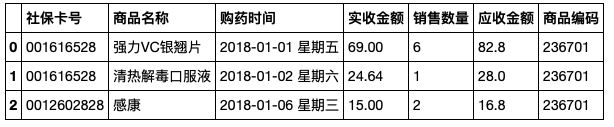
salesDf结果
2、Dataframe索引
>>查询数据:iloc属性用于根据位置获取值:查询元素 / 获取行 / 获取列
#查询元素:查询第1行第2列的元素
salesDf.iloc[0,1]
'强力VC银翘片'
#获取行:获取第1行,:代表所有列
salesDf.iloc[0,:]
社保卡号 001616528
商品名称 强力VC银翘片
购药时间 2018-01-01 星期五
实收金额 69
销售数量 6
应收金额 82.8
商品编码 236701
Name: 0, dtype: object
#获取列:获取第1列,:代表所有行
salesDf.iloc[:,0]
0 001616528
1 001616528
2 0012602828
Name: 社保卡号, dtype: object
>>查询数据:loc属性用于根据索引获取值:查询元素 / 获取行 / 获取列
#查询元素:查询第1行第2列的元素
salesDf.loc[0,'商品名称']
'强力VC银翘片'
#获取行:获取第1行
salesDf.loc[0,:]
社保卡号 001616528
商品名称 强力VC银翘片
购药时间 2018-01-01 星期五
实收金额 69
销售数量 6
应收金额 82.8
商品编码 236701
Name: 0, dtype: object
#获取列:获取“商品名称”这一列
print(salesDf.loc[:,'商品名称'])
#简单方法:获取“商品名称”这一列
print(salesDf['商品名称'])
0 强力VC银翘片
1 清热解毒口服液
2 感康
Name: 商品名称, dtype: object
0 强力VC银翘片
1 清热解毒口服液
2 感康
Name: 商品名称, dtype: object
>>数据框复杂查询:切片索引
#通过列表来选择某几列的数据
salesDf[['商品名称','销售数量']]
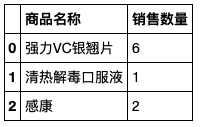
salesDf[['商品名称','销售数量']] 结果
#通过切片功能,获取指定范围的列
salesDf.loc[:,'购药时间':'销售数量']
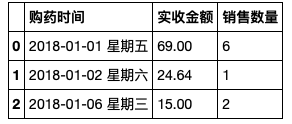
salesDf.loc[:,'购药时间':'销售数量']结果
>>数据框复杂查询:条件判断(布尔型索引)
#通过条件判断筛选
querySer=salesDf.loc[:,'销售数量']>1 #第1步:构建查询条件
salesDf.loc[querySer,:]

salesDf.loc[querySer,:]结果
3、查看数据集描述统计信息
#读取Ecxcel数据
fileNameStr='/Users/elieen/Downloads/朝阳医院2018年销售数据.xlsx'
xls = pd.ExcelFile(fileNameStr)
salesDf = xls.parse('Sheet1')
# 数据查看
salesDf.head(3) #打印出前3行
# df.tail() 查看尾部数据
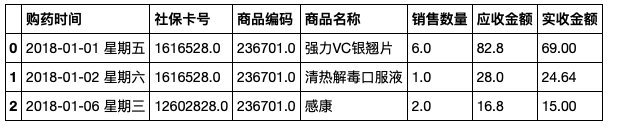
salesDf.head(3) 结果
#查看数据有多少行,多少列
salesDf.shape
(6578, 7)
#查看某一列的数据类型
salesDf.loc[:,'应收金额'].dtype
dtype('float64')
#查看每一列的统计数值
salesDf.describe()
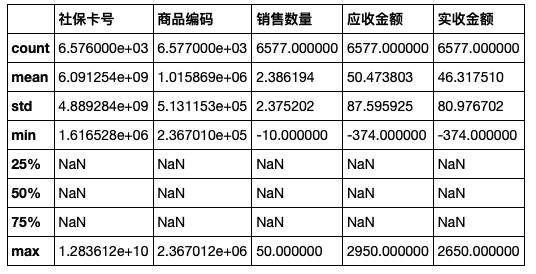
salesDf.describe()结果
4、dataframe与array二维数组的联系与区别:
numpy数组中的每一个元素都属于同一种数据类型,这在数值计算和科学计算中是非常有用的。但是它不利于我们表示类似于Excel中的内容,因为Excel中每一列的数据类型可能都不一样
DataFrame 也有索引的功能,这使得其很容易存储常见的表格数据,DataFrame 的每一列数据可以是不同类型,这就方便表示 Excel 中的数据内容。
三、总结~
以上分享了利用python进行数据分析两个最关键的包:numpy与pandas的基础学习内容,还有如numpy中random随机数、pandas中datetime时间模块等也是数据分析中常用到的模块函数,包括数据python在可视化matplotlib包的学习,后续会继续分享给大家。
在学习python中有任何困难不懂的可以微信扫描下方CSDN官方认证二维码加入python交流学习,多多交流问题,互帮互助,这里有不错的学习教程和开发工具。

点此免费领取:CSDN大礼包:《python学习路线&全套学习资料》免费分享
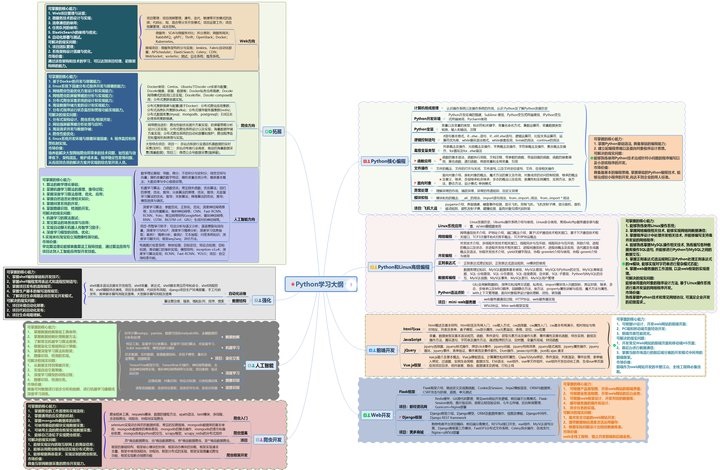
Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
入门学习视频
Python实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
最后,千万别辜负自己当时开始的一腔热血,一起变强大变优秀。















 1791
1791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









