







作者:Longway
来源:3D视觉工坊公众号
链接:CVPR2020 best paper:对称可变形三维物体的无监督学习
代码地址:https://github.com/elliottwu/unsup3d项目地址:https://elliottwu.com/projects/unsup3d/测试地址:http://www.robots.ox.ac.uk/~vgg/blog/unsupervised-learning-of-probably-symmetric-deformable-3d-objects-from-images-in-the-wild.html?image=004_face&type=human
概述
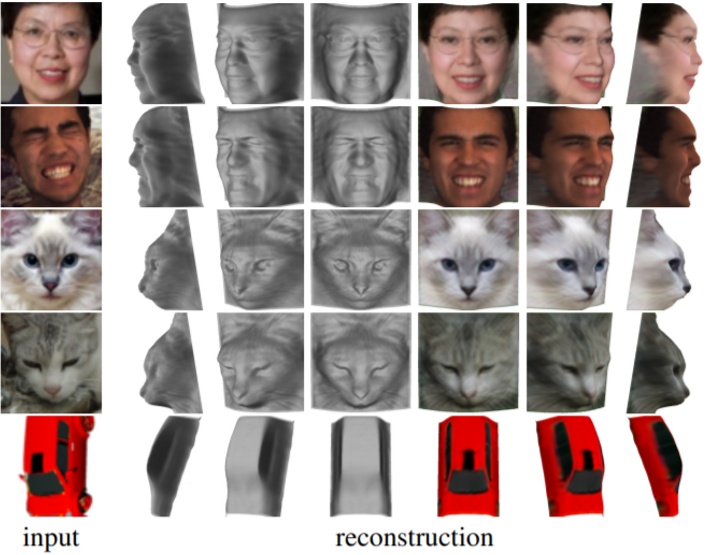
作者提出了一种从原始单目图像学习三维形变物体的方法,并且没有额外的监督信号。这个方法是基于自编码器的架构,将输入的图像转换为深度、反射率、视角和照明信息。为了分解这些没有监督的组件,作者使用了这样一个事实,即在大体上很多物体都是一个对称结构。对照明的推理允许我们去发掘潜在的对称,尽管由于阴影等原因外表不是对称的。实验表明这个方法能够从单目图像中恢复效果非常好的人脸、猫脸和汽车的三维形状。简介理解图像的3D结构在很多计算机视觉应用中是非常关键的,很多深度网络都是在2D平面上理解图像,3D建模能够去除自然图像中的变化性并且提高图像的理解。和其他一些方式类似,作者考虑从可变形物体学习3D模型(注:就是通过改变物体的形状来生成模型,比如说mesh表示的球体,通过改变顶点的位置即可生成另外一个物体)。作者在两个挑战性的条件下研究这个问题,第一个是没有2D或者3D的真值,第二个是算法必须使用无约束的单目图像集合——特别地,不需要相同实例的多个视角图像,这是因为在很多应用中从一张图像是非常重要的。基于上面两个问题,该算法能够从一张图像中建立该物体的三维形状,如下图所示:

首先用一个自编码器将图像分解成反射率、深度、光照和视角信息,并且对于这些信息没有直接的监督。但是,这是一个不适定问题,为了最小化这个问题,作者注意到大多数的物体都是对称的。由此可以通过简单的镜像对称获得一个虚拟的第二视角,如果能够找到这两张图像之间的联系,三维重建就能够通过立体重建实现。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









