





目标:原始数据集是含大量中文的xls格式的表格,目标处理为数值类别的csv表格。
原始数据集部分切片,如下格式:
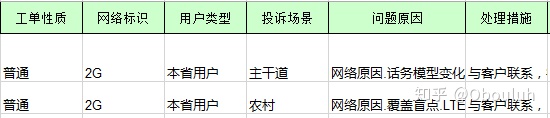
目标数据集为,处理成对应的数值类别格式,如下:

解决思路:(处理中文需要注意编码)
总体分两步,
1.提取每一列的值(含中文),作为key关键字,value为自增的整数,构造字典。利用了字典的key唯一的特性。
2.根据上一部提取的字典,对照字典,将数据集的中文key,替换为对应的value,即可。
from pandas import DataFrame
import pandas as pd
import matplotlib.pyplot as plt
import xlrd
fd = pd.read_excel("complain.xls", encoding='utf-8',header=None)
# fd[fd.notnull()]#查看缺失值情况
newdf = pd.DataFrame()#保存处理后的数据集
keydf = pd.DataFrame()#保存中文对照表
for i in range(len(fd.columns)):
newdata = {}#利用字典的key唯一特性,去除重复的文字,并利用value
index = #累加数值
rowline = []
keylist = []
rowdf = pd.DataFrame()
,len(fd)):#.提取关键字字典,key为中文,value为累加整型
key = fd.iloc[j,i]
if key not in newdata.keys():
newdata[key] = index
index +=
keylist.append(key)#将中文提取出来,方便对照
rowdf = pd.DataFrame({i: keylist})#保存中文对照表
keydf = pd.concat([keydf, rowdf], axis=, ignore_index=True)
, len(fd)):#.根据对照表,将中文替换成对应的数值
rowline.append(newdata[fd.iloc[k,i]])
rowdf = pd.DataFrame({i: rowline})#保存处理后的表
newdf = pd.concat([newdf, rowdf], axis=, ignore_index=True)
print newdf.info()
newdf.to_csv('newdata.csv')
keydf.to_csv('keylist.csv', encoding='gbk')转自:https://www.bbsmax.com/A/QV5Z1gqyJy/















 1283
1283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









