






免责声明:本文是通过网络收集并结合自身学习等途径合法获取,仅作为学习交流使用,其版权归出版社或者原创作者所有,并不对涉及的版权问题负责。若原创作者或者出版社认为侵权,请联系及时联系,我将立即删除文章,十分感谢!
注:来源刘顺祥《从零开始学Python数据分析与挖掘》,版权归原作者或出版社所有,仅供学习使用,不用于商业用途,如有侵权请留言联系删除,感谢合作。
10.1 朴素贝叶斯理论基础
在介绍如何使用贝叶斯概率公式计算后验概率之前,先回顾一下概率论与数理统计中的条件概率和全概率公式:
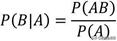
如上等式为条件概率的计算公式,表示在已知事件A的情况下事件B发生的概率,其中P(AB)表示事件A与事件B同时发生的概率。所以, 根据条件概率公式得到概率的乘法公式:P(AB)=P(A)P(B|A)=P(B)P(A|B)。
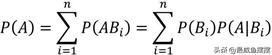
如上等式为全概率公式,其中事件B1,B2,…,Bn构成了一个完备的事件组,并且每一个P(Bi)均大于0。该公式表示,对于任意的一个事件A来说,都可以表示成n个完备事件组与其乘积的和。
在具备上述的基础知识之后,再来看看贝叶斯公式。如前文所说, 贝叶斯分类器的核心就是在已知X的情况下,计算样本属于某个类别的概率,故这个条件概率的计算可以表示为:
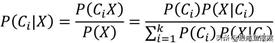
其中,Ci表示样本所属的某个类别。假设数据集的因变量y一共包含k个不同的类别,故根据全概率公式,可以将上式中的分母表示成
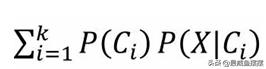
;再根据概率的乘法公式,可以将上式中的分子重新改写为P(Ci)P(X|Ci)。对于上面的条件概率公式而言,样本最终属于哪个类别Ci,应该将计算所得的最大概率值P(Ci|X)对应的类别作为样本的最终分类,所以上式可以表示为:
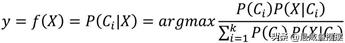
如上公式所示,对于已知的X,朴素贝叶斯分类器就是计算样本在各分类中的最大概率值。接下来详细拆解公式中的每一个部分,为获得条件概率的最大值,寻找最终的影响因素。分母是一个常量,它与样本属于哪个类别没有直接关系,所以计算P(Ci|X)的最大值就转换成了计算分子的最大值,即argmax P(Ci)P(X|Ci);如果分子中的P(Ci)项未知的话,一般会假设每个类别出现的概率相等,只需计算P(X|Ci)的最大值,然而在绝大多数情况下,P(Ci)是已知的,它以训练数据集中类别Ci的频率作为先验概率, 可以表示为NCi/N。所以,现在的主要任务就是计算P(X|Ci)的值,即已知某个类别的情况下自变量X为某种值的概率。假设数据集一共包含p个自变量,则X可以表示成(x1,x2,…,xp),进而条件概率P(X|Ci)可以表示为:P(X|Ci)=P(x1,x2,…,xp|Ci)很显然,条件联合概率值的计算还是比较复杂的,尤其是当数据集的自变量个数非常多的时候。为了使分类器在计算过程中提高速度,提出了一个假设前提,即自变量是条件独立的(自变量之间不存在相关 性),所以上面的计算公式可以重新改写为:
P(X|Ci)=P(x1,x2,…,xp|Ci)=P(x1|Ci)P(x2|Ci)…P(xp|Ci)
如上式所示,将条件联合概率转换成各条件概率的乘积,进而可以大大降低概率值P(X|Ci)的运算时长。但问题是,在很多实际项目的数据集中,很难保证自变量之间满足独立的假设条件。根据这条假设,可以得到一般性的结论,即自变量之间的独立性越强,贝叶斯分类器的效果就会越好;如果自变量之间存在相关性,就会在一定程度提高贝叶斯分类器的错误率,但通常情况下,贝叶斯分类器的效果不会低于决策树。
接下来的章节将介绍如何计算P(Ci)P(x1|Ci)P(x2|Ci)…P(xp|Ci)的最大概率值,从而实现一个未知类别样本的预测。
10.2 几种贝叶斯模型
自变量X的数据类型可以是连续的数值型,也可以是离散的字符 型,或者是仅含有0-1两种值的二元类型。通常会根据不同的数据类型选择不同的贝叶斯分类器,例如高斯贝叶斯分类器、多项式贝叶斯分类器和伯努利贝叶斯分类器,下面将结合案例详细介绍这几种分类器的使用方法。
10.2.1 高斯贝叶斯分类器
如果数据集中的自变量X均为连续的数值型,则在计算P(X|Ci)时会假设自变量X服从高斯正态分布,所以自变量X的条件概率可以表示成:
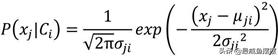
其中,xj表示第j个自变量的取值,μji为训练数据集中自变量xj属于类别Ci的均值,σji为训练数据集中自变量xj属于类别Ci的标准差。所以, 在已知均值μji和标准差σji时,就可以利用如上的公式计算自变量xj取某种值的概率。
为了使读者理解P(xj|Ci)的计算过程,这里虚拟一个数据集,并通过手工的方式计算某个新样本属于各类别的概率值。
如表10-1所示,假设某金融公司是否愿意给客户放贷会优先考虑两个因素,分别是年龄和收入。现在根据已知的数据信息考察一位新客 户,他的年龄为24岁,并且收入为8500元,请问该公司是否愿意给客户放贷?手工计算P(Ci|X)的步骤如下:
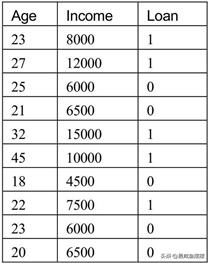
表10-1 适合高斯贝叶斯的数据类型
(1) 因变量各类别频率
P(loan=0)=5/10=0.5
P(loan=1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 514
514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









