





(点击上方快速关注并设置为星标,一起学Python)
引言
众所周知,python最强大的地方在于,python社区汇总拥有丰富的第三方库,开源的特性,使得有越来越多的技术开发者来完善。
python的完美性。
未来人工智能,大数据方向,区块链的识别和进阶都将以python为中心来展开。
咳咳咳! 好像有点打广告的嫌疑了。
当前互联网信息共享时代,最重要的是什么?是数据。最有价值的是什么?是数据。最能直观体现技术水平的是什么?还是数据。
所以,今天我们要分享的是:如何来获取各个文件格式的文本信息。
普通文件的格式 一般分为: txt普通文本信息,doc word文档,html网页内容,excel表格数据,以及特殊的mht文件。
一、Python处理html网页信息
html类型的文本数据,内容是由前端代码书写的标签+文本数据的格式,可以直接在chrome浏览器打开,清楚 的展示出文本的格式。
python 获取html文件的内容和获取txt文件的方法相同,直接打开文件读取就可以了。
读取代码如下:
with open(html_path, file 是html文件的文本内容。是一个网页标签的格式内容。
二、Python处理excel表格信息
python拥有直接操作excel表格的第三方库xlwt,xlrd。调用对应的方法就可以读写excel表格数据。
读取excel操作代码如下:
"C:\\Users\Administrator\Desktop\新建文件夹\笨笨 前程6份 武汉.xls"其中row是表格数据对应的行数, cell获取具体行数,列数的具体数据。
三、Python读取doc文档数据
python读取doc文档是最麻烦的。处理逻辑复杂。处理的方式也有很多种。
python 没有直接处理doc文档的第三方库,但是有一个处理docx的第三方库。可以通过将doc文件转换为docx文件,再调用第三方python库pydocx来读取doc文档的内容。
这里需要注意的是,不要直接修改doc的后缀来修改成docx文件。直接通过修改后缀获取的docx文件,pydocx无法读取内容。
我们可以使用另外一个库来修改doc为docx。
具体代码如下:
def doSaveAas(self, doc_path):代码所需的包接口:
import ospython处理docx文档的方法有很多种,具体使用情况,根据个人需求来决定。
No.1 解压docx文件
docx文件的原理,本质上就是一个压缩的zip文件,通过解压以后,就可以获取原来文件的各个内容。
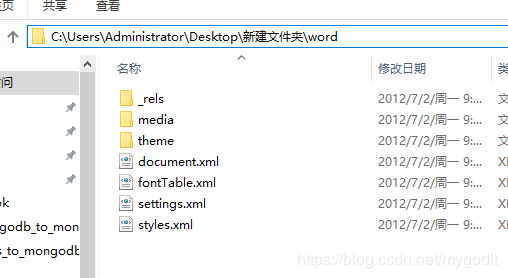
docx解压后的文件结构如下:

docx文件的文本内容存储结构如下:
文本内容存储于word/document.xml文件中。
第一种方法,我们就可以先将docx还原成zip压缩文件,再解压zip文件,读取word/document.xml文件的内容就ok了。
具体操作代码如下:
def get_content(self):最后获取到的就是docx文档的所有文本数据了。
No.2 将docx文档转换成python能够处理的文本格式
第一种方法,是依据docx文档的原理来获取数据,流程有点繁琐,有没有能直接读取docx文档内容的方法呢?答案,肯定是没有的,别想了,洗洗回家睡吧。
直接读取docx文档的方法没有,有没有能够将docx文档转换成python能够轻松处理的文本格式呢?
这个可以有,前面说了,python拥有大量丰富的第三方库(先夸一波我大python),历经千辛万苦终于找到了,一个能转换docx文档格式的第三方库,pydocx,pydocx库中有个方法pydocx.to_html()就可以直接将docx文档转换为html文件,怎么样?意不意外,惊喜不惊喜!
第二种方法,转换文本格式的代码如下:
def docx_to_html(self, docx_path):获取到的response是html文件内容。
四、Python处理mht文件
mht文件是一种只能在IE浏览器上展示的文本格式,在chrome浏览器中打开是一堆的乱码。
No.1 伪造IE请求mht文件内容
最基础的读取mht文本的方法就是伪造IE浏览器请求。
调用requests库,发送get请求网页链接,构造IE的请求头信息。
理论上来说,这种方法是可行的。但是呢,不建议用,原因大家都懂得。

No.2 转换文件格式
好了说正经的方法,猜测mht文件能否修改成其他文件格式来直接读取呢?
docx,不行;html,不行;excel,更不用说了。
真相只有一个!!!
直接修改后缀得到的docx,无法读取。
so,我们想到的方法是什么呢。没错,就是修改成doc文档。
方法是匪夷所思的,但也是灵感一现。
mht可以直接通过修改后缀转换成doc文档,doc文档读取文本内容的方法具体参考上面读取doc文档的方法。
如何获取html文本的内容?
html文本的内容是网页结构标签数据,取出文本的方式是:re正则,或者xpath。
后续,小伙伴有需要的话,会再开一章详细了解re,xapth的使用规则。
如果有问题的话,也可以随时留言,感谢观看!!
(完)
看完本文有收获?请转发分享给更多人
关注「Python那些事」,做全栈开发工程师
















 9064
9064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









