






编辑:zero 关注 搜罗最好玩的计算机视觉论文和应用,AI算法与图像处理 微信公众号,获得第一手计算机视觉相关信息
在本教程中,您将学习在训练自己的自定义深度神经网络时,验证损失可能低于训练损失的三个主要原因。
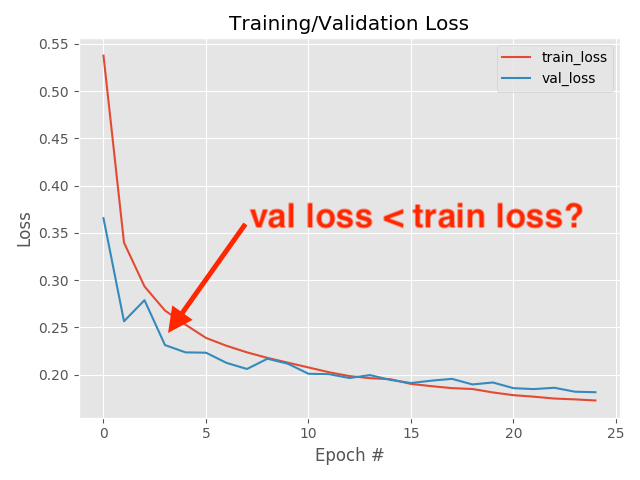
我的验证损失低于训练损失!
怎么可能呢?
- 我是否意外地将训练和验证loss绘图的标签切换了? 潜在地。 我没有像matplotlib这样的绘图库,因此将丢失日志通过管道传输到CSV文件,然后在Excel中进行绘图。 绝对容易发生人为错误。
- 我的代码中有错误吗? 几乎可以确定。 我同时在自学Java和机器学习-该代码中肯定存在某种错误。
- 我只是因为太疲倦而无法理解我的大脑吗? 也很有可能。 我一生中的睡眠时间不多,很容易错过一些明显的事情。
但是,事实证明,上述情况都不是——我的验证损失确实比我的训练损失低。
要了解您的验证loss可能低于训练loss的三个主要原因,请继续阅读!
为什么我的验证loss低于训练loss?
在本教程的第一部分中,我们将讨论神经网络中“loss”的概念,包括loss代表什么以及我们为什么对其进行测量。
在此,我们将实现一个基础的CNN和训练脚本,然后使用新近实现的CNN进行一些实验(这将使我们的验证损失低于我们的训练损失)。
根据我们的结果,我将解释您的验证loss可能低于训练loss的三个主要原因。
训练神经网络时的“loss”是什么?
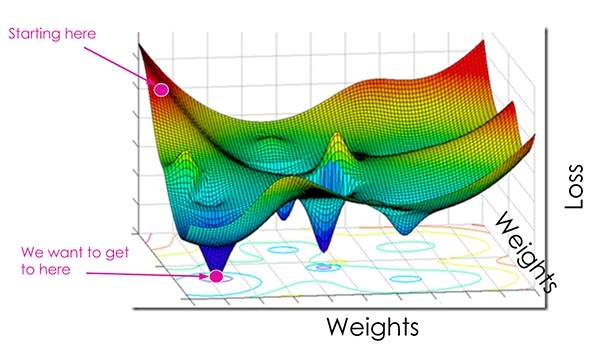
在最基本的层次上,loss函数可量化给定预测变量对数据集中输入数据点进行分类的“好”或“坏”程度。
loss越小,分类器在建模输入数据和输出目标之间的关系方面的工作就越好。
就是说,在某种程度上我们可以过度拟合我们的模型-通过过于紧密地建模训练数据(modeling the training data too closely),我们的模型将失去泛化的能力。
因此,我们寻求:
- 尽可能降低loss,从而提高模型精度。
- 尽可能快地这样子做,并减少超参数的更新/实验次数。
- 所有这些都没有过度拟合我们的网络,也没有将训练数据建模得过于紧密。。
这是一种平衡,我们选择loss函数和模型优化器会极大地影响最终模型的质量,准确性和通用性。
典型的损失函数(也称为“目标函数”或“评分函数”)包括:
- Binary cross-entropy
- Categorical cross-entropy
- Sparse categorical cross-entropy
- Mean Squared Error (MSE)
- Mean Absolute Error (MAE)
- Standard Hinge
- Squared Hinge
对loss函数的全面回顾不在本文的范围内,但就目前而言,只需了解对于大多数任务:
- loss衡量你的模型的“好(goodness)”
- loss越小越好
- 但你要小心别过拟合
要了解在训练自己的自定义神经网络时loss函数的作用,请确保:
- 阅读参数化学习和线性分类简介。https://www.pyimagesearch.com/2016/08/22/an-intro-to-linear-classification-with-python/
- 请阅读以下有关SoftMax分类器的教程。https://www.pyimagesearch.com/2016/09/12/softmax-classifiers-explained/
- 关于多类SVM损失,请参阅本指南。https://www.pyimagesearch.com/2016/09/05/multi-class-svm-loss/
文件结构
从那里,通过tree命令检查项目/目录结构:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ └── minivggnet.py
├── fashion_mnist.py
├── plot_shift.py
└── training.pickle
1 directory, 5 files今天我们将使用一个称为MiniVGGNet的更小版本的vggnet。pyimagesearch模块包括这个CNN。
我们的fashion_mnist.py脚本在fashion MNIST数据集上训练MiniVGGNet。我在之前的一篇博文中写过关于在时尚mnist上训练MiniVGGNet,所以今天我们不会详细讨论。
https://www. pyimagesearch.com/2019/ 02/11/fashion-mnist-with-keras-and-deep-learning/
今天的训练脚本将生成一个training.pickle文件,其中包含训练精度/loss历史记录。在下面的原因部分中,我们将使用plot_shift.py将训练loss图移动半个epoch,以证明当验证loss低于训练loss时,测量loss的时间起作用。现在让我们深入探讨三个原因来回答这个问题:“为什么我的验证loss比训练loss低?“。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









