






首先,因为不熟悉pytorch的函数,首先在这记录一下查询到的函数。
1. view函数
类似于resize,把原先tensor中的数据按照行优先的顺序排成一个一维的数据(这里应该是因为要求地址是连续存储的),然后按照参数组合成其他维度的tensor。比如说是不管你原先的数据是[[[1,2,3],[4,5,6]]]还是[1,2,3,4,5,6],因为它们排成一维向量都是6个元素,所以只要view后面的参数一致,得到的结果都是一样的。比如,
a=torch.Tensor([[[1,2,3],[4,5,6]]])
b=torch.Tensor([1,2,3,4,5,6])
print(a.view(1,6))
print(b.view(1,6))结果都是tensor([[1., 2., 3., 4., 5., 6.]])
a=torch.Tensor([[[1,2,3],[4,5,6]]])
print(a.view(3,2))结果为
tensor([[1., 2.],
[3., 4.],
[5., 6.]])
view(-1),则原张量会变成一维的结构
>>> import torch
>>> tt2=torch.tensor([[-0.3623, -0.6115],
... [ 0.7283, 0.4699],
... [ 2.3261, 0.1599]])
>>> result=tt2.view(-1)
>>> result
tensor([-0.3623, -0.6115, 0.7283, 0.4699, 2.3261, 0.1599])
L1 线性回归
回归是在建模过程中用于分析变量之间的关系、以及变量是如何影响结果的一种技术。线性回归是指全部由线性变量组成的回归模型。例如,最简单的单变量线性回归(Single Variable Linear Regression)是用来描述单个变量和对应输出结果的关系,可以简单的表示成下面的式子:
Y=a∗X+b Y=a∗X+b
因为在实际的建模过程中遇到的问题往往更加复杂,用单个变量不能满足描述输出便变量的关系,所以需要用到更多的变量来表示与输出之间的关系,也就是多变量线性回归(Multi Variable Linear Regression)。多变量线性回归模型如下:
Y=a1∗X1+a1∗X2+a3∗X3+.....+an∗Xn+b Y=a1∗X1+a1∗X2+a3∗X3+.....+an∗Xn+b
其中a为系数,x是变量,b为偏置。因为这个函数只有线性关系,所以只适用于建模线性可分数据。我们只是使用系数权重来加权每个特征变量的重要性。
线性回归的几个特点:
1. 建模速度快,不需要很复杂的计算,在数据量大的情况下依然运行速度很快。
2. 可以根据系数给出每个变量的理解和解释
3. 对异常值很敏感
L2 softmax
多分类问题常用全连接层
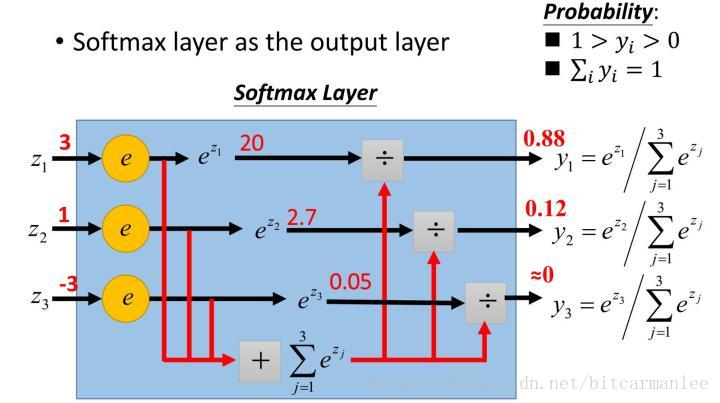
1.softmax设计的初衷,是希望特征对概率的影响是乘性的。
2.多类分类问题的目标函数常常选为cross-entropy。即L=−∑ktk⋅lnP(y=k)L=−∑ktk⋅lnP(y=k),其中目标类的tktk为1,其余类的tktk为0。
3. 在神经网络模型中(最简单的logistic regression也可看成没有隐含层的神经网络),输出层第i个神经元的输入为ai=∑dwidxdai=∑dwidxd。
4. 神经网络是用error back-propagation训练的,这个过程中有一个关键的量是∂L/∂αi∂L/∂αi。
根据cs224n课程,softmax为:

L2.1 交叉熵
ytorch中交叉熵函数是nn.CrossEntropyLoss()。其参数包括:weight,size_averaged,reduce
weight参数通常默认值是0,如果你的训练样本很不均衡的话,可以设置其值。
size_averaged参数是设置是否取均值,默认是对bach取均值,若设置为False就是对bach求和,这两种情况下损失函数输出的是一个标量
reduce是表示是否size_averaged起作用,默认为True,size_averaged起作用。设置为False,size_averaged不起作用,不求和也不求均值,输出一个向量。
此外要注意:input是二维的数据类型为FloatTensor,对应numpy的float32。而target是一维的,且为LongTensor,对应numpy的int64,也就是说target里面是整数,代表各个类别。eg,input是shape是(2,3)那么target应该为[a1,a2],其中a1,a2范围是0-3(不包括3)的整数。
L3 多层感知机
激活函数:
线性模型在处理非线性问题时往往无从下手,这时引入激活函数来解决线性不可分问题!激活函数往往存在于输入层和输出层之间,目的是给神经网络一些非线性因数,使得神经网络能够解决更加复杂的问题,同时增强了神经网络的表达能力和学习能力。
常用的激活函数:
修正线性单元ReLU
f(x) = max(0,x)
函数图像原点的左侧输出为0,斜率为0,函数图像原点右侧是斜率为1的直线,输出值就是输入值。相比上面的两种方法,有效的解决了梯度下降问题。并且计算简单,只要设置一定的阈值就可以计算激活值,极大的提高了计算的速度。
缺点:
训练的时候不适合大梯度的输入数据,因为在参数更新之后,ReLU的神经元不会再任何数据节点被激活,这就会导致梯度永远为0。比如:输入的数据小于0时,梯度就会为0,这就导致了负的梯度被置0,而且今后也可能不会被任何数据所激活,也就是说ReLU的神经元“坏死”了。
针对上面的问题又出现了:带泄露的ReLU和带参数的ReLU
双曲正切激活函数(Tanh)
它的输出范围是[-1,1]之间。Tanh函数的输出是以0为均值的,解决了Sigmoid函数的第二个缺点。但是当输入特别大或者特别小的时候仍然会存在梯度消失的问题。
Sigmoid函数
单调递增函数,输出范围在[0,1]之间,负向增大趋近于0,正向增大越来越慢,趋近于1。比较容易求导。
缺点:
1、容易造成梯度消失,可以看出当输入特别大或特别小时,神经元梯度几乎为0,导致神经网络不收敛,参数就不会更新,训练就会变难。
2、 函数的输出不是以0为均值,导致传入下一层神经网络的输入是非0。这就可能导致传入神经网络的值永远大于0,这时参数无论怎么更新梯度都为正。
L4. 文本预处理
针对于中文的文本预处理和英文步骤大体一样,只是针对于中文而言,不能依托于单词间的空格来进行分词步骤。现在不论是jieba还是hanlp,主流的分词技术都是依托于n-gram模型来进行中文文本的划分。往细说,隐马尔可夫链+维托比算法。
主要的问题还是未登陆词的解决,特定领域可以用词典解决。当然,再其上在加入基于bilstm + CRF的主流ner方法来解决也是很好的方法。
L5. 语言模型
在自然语言处理系统中,语言模型的性能好坏直接影响整个系统的性能。尽管语言模型的理论基础已比较完善,但在实际应用中常常会遇到一些难以处理的问题。其中,模型对跨领域的脆弱性(brittlenessacross domains)和独立性假设的无效性(false independence assumption)是两个最明显的问题。也就是说,一方面在训练语言模型时所采用的语料往往来自多种不同的领域,这些综合性语料难以反映不同领域之间在语言使用规律上的差异,而语言模型恰恰对于训练文本的类型、主题和风格等都十分敏感;另一方面,n元语言模型的独立性假设前提是一个文本中的当前词出现的概率只与它前面相邻的n-1个词相关,但这种假设在很多情况下是明显不成立的。另外,香农实验(Shannon-style experiments)表明,相对而言,人更容易运用特定领域的语言知识、常识和领域知识进行推理以提高语言模型的性能(预测文本的下一个成分)。因此,为了提高语言模型对语料的领域、主题、类型等因素的适应性,提出了自适应语言模型(adaptive language model)的概念。在随后的这些年里,人们相继提出了一系列的语言模型自适应方法,并进行了大量实践。例如基于缓存的语言模型(cache-based LM)、基于混合方法的语言模型(mixture-based LM)和基于最大熵的语言模型。
当然,现在使用word2vec的skip-gram较多。
L6. RNN
我们从基础的神经网络中知道,神经网络包含输入层、隐层、输出层,通过激活函数控制输出,层与层之间通过权值连接。激活函数是事先确定好的,那么神经网络模型通过训练“学“到的东西就蕴含在“权值“中。
基础的神经网络只在层与层之间建立了权连接,RNN最大的不同之处就是在层之间的神经元之间也建立的权连接。如图。
这是一个标准的RNN结构图,图中每个箭头代表做一次变换,也就是说箭头连接带有权值。左侧是折叠起来的样子,右侧是展开的样子,左侧中h旁边的箭头代表此结构中的“循环“体现在隐层。
在展开结构中我们可以观察到,在标准的RNN结构中,隐层的神经元之间也是带有权值的。也就是说,随着序列的不断推进,前面的隐层将会影响后面的隐层。图中O代表输出,y代表样本给出的确定值,L代表损失函数,我们可以看到,“损失“也是随着序列的推荐而不断积累的。
除上述特点之外,标准RNN的还有以下特点:
1、权值共享,图中的W全是相同的,U和V也一样。
2、每一个输入值都只与它本身的那条路线建立权连接,不会和别的神经元连接。















 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









