






 作者 | Justina Petraityte 译者 | 平川 编辑 | 陈思
AI 前线导读:像谷歌助手这样的平台简化了自定义语音助手的构建。但是,如果你想要构建一个在本地运行并能确保数据隐私的助手,该怎么办呢?你可以使用 Rasa、Mozilla DeepSpeech 和 Mozilla TTS 等开源工具来实现。通过本教程,你可以了解实现过程。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
作者 | Justina Petraityte 译者 | 平川 编辑 | 陈思
AI 前线导读:像谷歌助手这样的平台简化了自定义语音助手的构建。但是,如果你想要构建一个在本地运行并能确保数据隐私的助手,该怎么办呢?你可以使用 Rasa、Mozilla DeepSpeech 和 Mozilla TTS 等开源工具来实现。通过本教程,你可以了解实现过程。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
像谷歌助手这样的平台简化了自定义语音助手的构建。但是,如果你想要构建一个在本地运行并能确保数据隐私的助手,该怎么办呢?你可以使用 Rasa、Mozilla DeepSpeech 和 Mozilla TTS 等开源工具来实现。通过本教程,你可以了解实现过程。
随着谷歌助手和 Alexa 等平台越来越受欢迎,语音助手必将成为各行各业客户互动的下一个重要领域。然而,除非你使用托管的现成解决方案,否则语音助手的开发将带来一系列超越 NLU 和对话管理的全新挑战——除此之外,你还需要照顾到语音转文本、文本转语音组件以及前端。不久前,当我们尝试构建一个 基于 Rasa 的谷歌助手 时,我们谈到了语音主题。像谷歌助手这样的平台消除了实现语音处理和前端组件的障碍,但是它迫使你在数据的安全性和所用工具的灵活性上做出妥协。
那么,如果你想要构建一个本地运行并能确保数据安全的语音助手,你有哪些选项呢?我们来看看。在本文中,你将了解仅使用开源工具如何构建语音助手——从后端到前端。

工具和软件概述
Rasa 助手
实现语音转文本组件
实现文本转语音组件
组合到一起
下一步工作
小结及相关资源
本文的目的是向你展示仅使用开源工具如何构建自己的语音助手。一般来说,构建语音助手需要五个主要组件:
语音界面——供用户和助手通信的前端(Web、移动应用、智能扬声器等);
语音转文本(STT)——一个语音处理组件,将用户的音频输入转换为文本表示;
NLU——该组件从用户输入文本中提取结构化数据(意图和实体),帮助助手理解用户意图;
对话管理——该组件决定助手在特定的对话状态中如何响应并生成响应文本;
文本转语音(TTS)——该组件获取助手的文本响应,生成语音表示然后返回给用户。
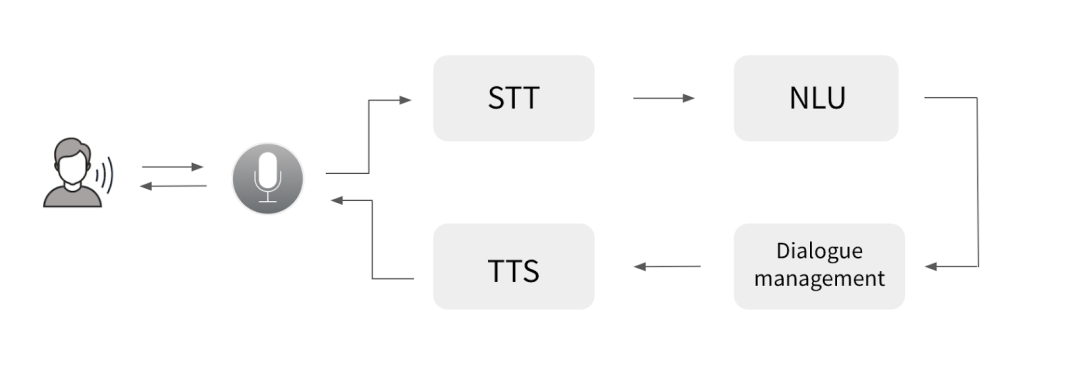
虽然对于 NLU 和对话管理来说,开源的 Rasa 是一个显而易见的选择,但是 STT 和 TTS 的选择就比较困难了,因为没有那么多开源框架可供选择。在研究了当前可用的选项 CMUSphinx、Mozilla DeepSpeech、Mozilla TTS、Kaldi 之后,我们决定使用 Mozilla 的工具——Mozilla DeepSpeech 和 Mozilla TTS,原因如下:
Mozilla 的工具提供了一组预先训练好的模型,但是你也可以使用定制的数据训练自己的模型。这就让你可以快速实现一些东西,但也让你可以自由地构建自定义组件。
与其他可选工具相比,Mozilla 的工具似乎是操作系统无关度最高的。
两个工具都是用 Python 编写的,与 Rasa 集成稍微容易些。
有一个大而活跃的开源社区时刻准备着帮助回答技术问题。
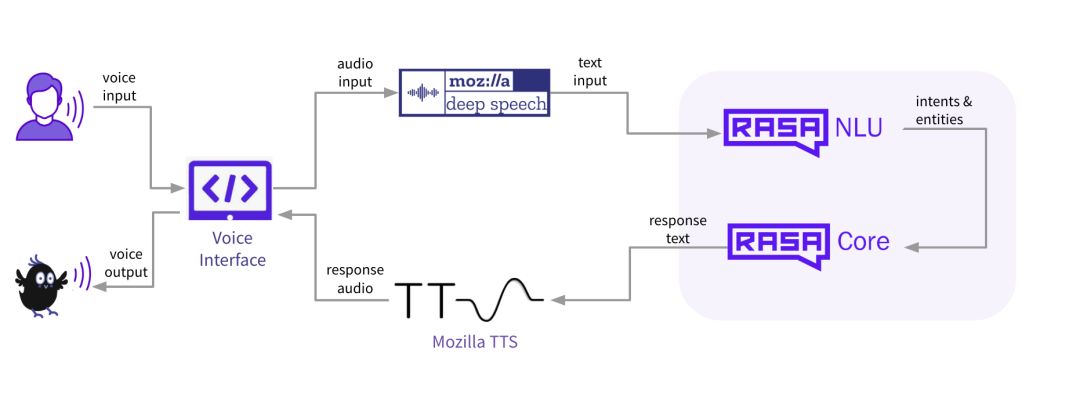
Mozilla DeepSpeech 和 Mozilla TTS 是什么?Mozilla DeepSpeech 是一个语音转文本的框架,它接收用户的音频输入,并使用机器学习将其转换为文本格式,稍后由 NLU 和对话系统进行处理。Mozilla TTS 则负责相反的工作——它接收文本输入(在我们的例子中是对话系统生成的助手响应),并使用机器学习创建文本的音频表示。
NLU、对话管理和语音处理组件处理语音助手的后端,那么前端呢?好吧,这就是最大的问题所在——如果你搜索开源语音界面小部件,最终很可能没有结果。至少我们遇到了这样的情况,这也是为什么我们开发了自己的语音界面 Rasa,我们将在这个项目中使用它,并且很高兴能与社区分享!
综上所述,开源语音助手包含以下组成部分:
Rasa:https://github.com/RasaHQ/rasa
Mozilla DeepSpeech:https://github.com/mozilla/DeepSpeech
Mozilla TTS:https://github.com/mozilla/TTS
Rasa Voice Interface:https://github.com/RasaHQ/rasa-voice-interface
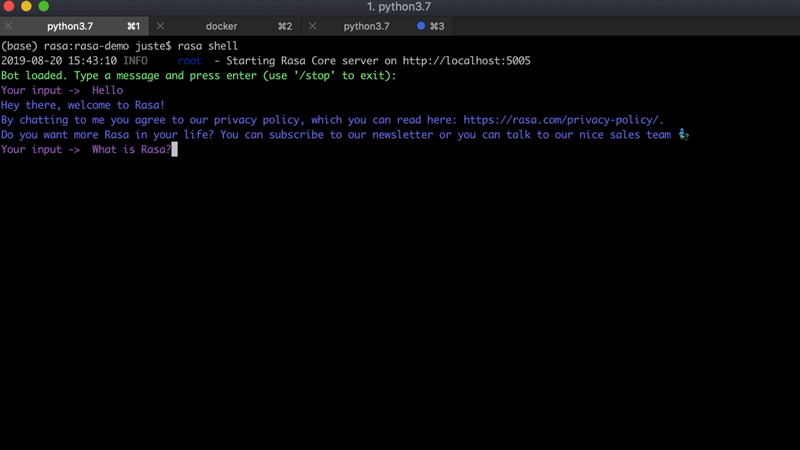
对于这个项目,我们将使用一个已有的 Rasa 助手——Sara。它是一个基于 Rasa 的开源助手,可以回答关于 Rasa 框架的各种问题来帮助你入门。下面是和 Sara 对话的一个例子:
下面是在本地机器上安装 Sara 的步骤:
克隆 Sara 库:
git clone https://github.com/RasaHQ/rasa-demo.git
cd rasa-demo
安装必要的依赖:
pip install -e .
训练 NLU 和对话模型:
rasa train --augmentation 0
在你的终端上测试 Sara:
docker run -p 8000:8000 rasa/duckling
rasa run actions --actions demo.actions
make run-cmdline
为了把 Sara 变成一个语音助手,我们必须在实现的后期编辑一些项目文件。在此之前,让我们先实现 TTS 和 STT 组件。
实现语音转文本组件我们接下来要实现语音转文本组件——Mozilla DeepSpeech 模型。阅读 Rouben Morais 的这篇 博文,进一步了解 Mozilla DeepSpeech 的工作原理。Mozilla DeepSpeech 提供了一些预训练的模型,也允许你训练自己的模型。简单起见,我们在这个项目中使用了一个预先训练好的模型。以下是在本地机器上安装 STT 的步骤:
安装 Mozilla DeepSpeech:
pip3 install deepspeech
下载预训练的语音转文本模型并解压到项目目录下:
wget https://github.com/mozilla/DeepSpeech/releases/download/v0.5.1/deepspeech-0.5.1-models.tar.gz
tar xvfz deepspeech-0.5.1-models.tar.gz
运行上述命令后,项目目录下会新增一个目录 deepspeech-0.5.1-models,其中包含模型文件。
测试模型:
检查组件设置是否正确的最佳方法是使用一些音频输入示例测试模型。下面是测试脚本:
函数 record_audio() 获取一段时长 5 秒的音频并保存到文件 test_audio.wav 中;
函数 deepspeech_predict() 加载 DeepSpeech 模型并将文件 test_audio.wav 传递给它,它会预测音频输入的文本。
import pyaudio
from deepspeech import Model
import scipy.io.wavfile as wav
WAVE_OUTPUT_FILENAME = "test_audio.wav"
def record_audio(WAVE_OUTPUT_FILENAME):
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 16000
RECORD_SECONDS = 5
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("* recording")
frames = [stream.read(CHUNK) for i in range(0, int(RATE / CHUNK * RECORD_SECONDS))]
print("* done recording")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
def deepspeech_predict(WAVE_OUTPUT_FILENAME):
N_FEATURES = 25
N_CONTEXT = 9
BEAM_WIDTH = 500
LM_ALPHA = 0.75
LM_BETA = 1.85
ds = Model('deepspeech-0.5.1-models/output_graph.pbmm', N_FEATURES, N_CONTEXT, 'deepspeech-0.5.1-models/alphabet.txt', BEAM_WIDTH)
fs, audio = wav.read(WAVE_OUTPUT_FILENAME)
return ds.stt(audio, fs)
if __name__ == '__main__':
record_audio(WAVE_OUTPUT_FILENAME)
predicted_text = deepspeech_predict(WAVE_OUTPUT_FILENAME)
print(predicted_text)
使用下面的命令运行脚本,一旦你看到消息“录制……”就说一个你希望用于测试这个模型的句子:
python deepspeech_test_prediction.py
在本文的下一部分中,你将学习如何设置项目的第三部分——文本转语音组件。
实现文本转语音组件为了使助手能够用语音而不是文本进行响应,我们必须设置文本转语音组件,该组件将接收 Rasa 生成的文本响应并将其转换为声音。为此,我们使用 Mozilla TTS。就像 Mozilla DeepSpeech 一样,它提供了预训练模型,但是你也可以使用自定义数据训练自己的模型。这次,我们还是使用一个预先训练好的 TTS 模型。下面是在本地机器上设置 TTS 组件的步骤:
克隆 Mozilla TTS 库:
git clone https://github.com/mozilla/TTS.git
cd TTS
git checkout db7f3d3
安装程序包:
python setup.py develop
下载模型:
在 Sara 目录下,创建一个文件夹 tts_mode*l ,并从这里下载模型文件:
https://drive.google.com/drive/folders/1GU8WGix98WrR3ayjoiirmmbLUZzwg4n0
测试组件:
使用以下脚本测试文本转语音组件。下面是脚本完成的工作:
函数 load_model() 加载模型并做好处理准备;
函数 tts() 获取文本输入并创建一个音频文件 test_tts.wav。
如果你希望使用自定义的输入来测试模型,则可以修改 sentence 变量。脚本运行结束后,结果将保存在 test_tt .wav 文件中,你可以听下该文件来查看模型的效果。
import os
import sys
import io
import torch
from collections import OrderedDict
from TTS.models.tacotron import Tacotron
from TTS.layers import *
from TTS.utils.data import *
from TTS.utils.audio import AudioProcessor
from TTS.utils.generic_utils import load_config
from TTS.utils.text import text_to_sequence
from TTS.utils.synthesis import synthesis
from utils.text.symbols import symbols, phonemes
from TTS.utils.visual import visualize
# 设置常量
MODEL_PATH = './tts_model/best_model.pth.tar'
CONFIG_PATH = './tts_model/config.json'
OUT_FILE = 'tts_out.wav'
CONFIG = load_config(CONFIG_PATH)
use_cuda = False
def tts(model, text, CONFIG, use_cuda, ap, OUT_FILE):
waveform, alignment, spectrogram, mel_spectrogram, stop_tokens = synthesis(model, text, CONFIG, use_cuda, ap)
ap.save_wav(waveform, OUT_FILE)
return alignment, spectrogram, stop_tokens
def load_model(MODEL_PATH, sentence, CONFIG, use_cuda, OUT_FILE):
# 加载模型
num_chars = len(phonemes) if CONFIG.use_phonemes else len(symbols)
model = Tacotron(num_chars, CONFIG.embedding_size, CONFIG.audio['num_freq'], CONFIG.audio['num_mels'], CONFIG.r, attn_windowing=False)
# 加载音频处理器
# CONFIG.audio["power"] = 1.3
CONFIG.audio["preemphasis"] = 0.97
ap = AudioProcessor(**CONFIG.audio)
# 加载模型状态
if use_cuda:
cp = torch.load(MODEL_PATH)
else:
cp = torch.load(MODEL_PATH, map_location=lambda storage, loc: storage)
# 加载模型
model.load_state_dict(cp['model'])
if use_cuda:
model.cuda()
model.eval()
model.eval()
model.decoder.max_decoder_steps = 1000
align, spec, stop_tokens = tts(model, sentence, CONFIG, use_cuda, ap, OUT_FILE)
if __name__ == '__main__':
sentence = "Hello, how are you doing? My name is Sara"
load_model(MODEL_PATH, sentence, CONFIG, use_cuda, OUT_FILE)
到这里,你本地的机器上应该已经运行着所有最重要的组件——Rasa 助手、语音转文本和文本转语音组件。接下来要做的就是将所有这些组件组合到一起,并将助手连接到 Rasa 语音界面。要了解如何实现,请阅读本文的下一部分。
组合到一起要把这些组件组合到一起对语音助手进行实际的测试,我们还需要两个东西:
(1)语音界面;
(2)一个可以在 UI 和后端(Mozilla 和 Rasa 组件)之间建立通信的连接器。
我们先设置下 Rasa 语音界面,步骤如下:
按照 这里的说明 安装 npm 和 node;
克隆 Rasa Voice UI 库:
git clone https://github.com/RasaHQ/rasa-voice-interface.git
cd rasa-voice-interface
安装组件:
npm install
测试组件:
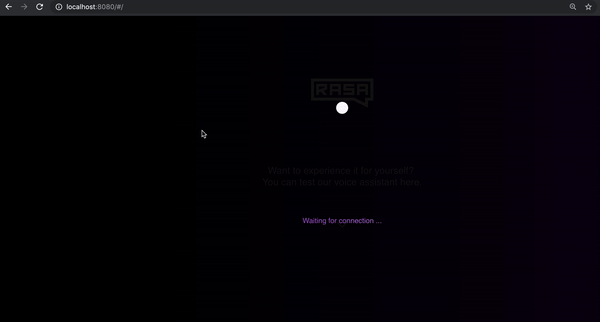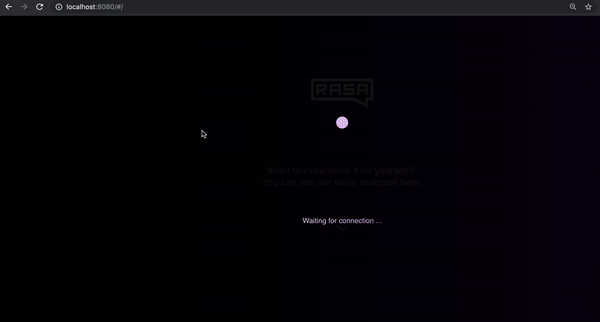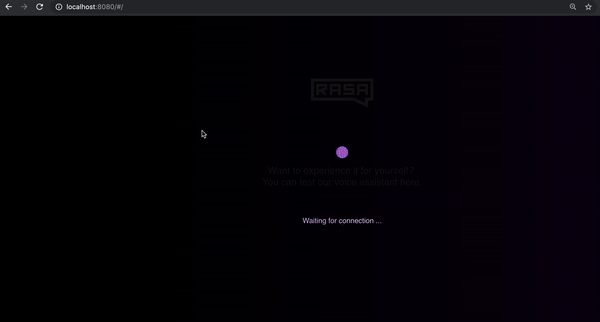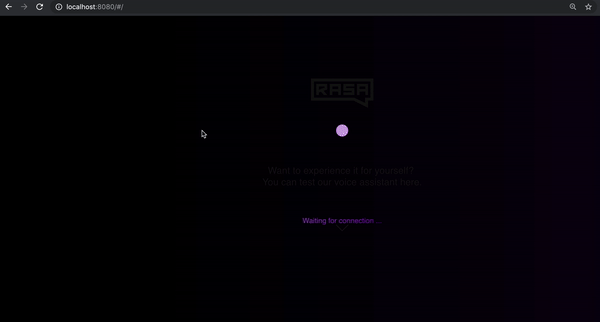
npm run serve
运行上述命令后,打开浏览器并导航到 https://localhost:8080,检查语音界面是否正在加载。弹跳球表示它已成功加载并在等待连接。
为了将助手连接到界面,你需要一个连接器。该连接器还将确定用户说话时引发什么动作,以及音频响应如何传回前端组件。要创建一个连接器,我们可以使用现有的 socketio 连接器,并使用几个新组件升级它:
SocketIOInput() 类事件 ‘user_utter’ 已经更新为接收 Rasa 语音界面以链接形式发送的音频数据并保存为磁盘上的一个.wav 文件。然后,我们加载 Mozilla STT 模型将音频转换为文本表示并传递给 Rasa;
SocketIOutput() 类获得一个新方法 _send_audio_message(),该方法取得 Rasa 对话管理模型预测生成的文本响应,加载 Mozilla TTS 模型将文本转换为音频格式并发回前端。
下面是升级后连接器的全部代码:
import logging
import uuid
from sanic import Blueprint, response
from sanic.request import Request
from socketio import AsyncServer
from typing import Optional, Text, Any, List, Dict, Iterable
from rasa.core.channels.channel import InputChannel
from rasa.core.channels.channel import UserMessage, OutputChannel
import deepspeech
from deepspeech import Model
import scipy.io.wavfile as wav
import os
import sys
import io
import torch
import time
import numpy as np
from collections import OrderedDict
import urllib
import librosa
from TTS.models.tacotron import Tacotron
from TTS.layers import *
from TTS.utils.data import *
from TTS.utils.audio import AudioProcessor
from TTS.utils.generic_utils import load_config
from TTS.utils.text import text_to_sequence
from TTS.utils.synthesis import synthesis
from utils.text.symbols import symbols, phonemes
from TTS.utils.visual import visualize
logger = logging.getLogger(__name__)
def load_deepspeech_model():
N_FEATURES = 25
N_CONTEXT = 9
BEAM_WIDTH = 500
LM_ALPHA = 0.75
LM_BETA = 1.85
ds = Model('deepspeech-0.5.1-models/output_graph.pbmm', N_FEATURES, N_CONTEXT, 'deepspeech-0.5.1-models/alphabet.txt', BEAM_WIDTH)
return ds
def load_tts_model():
MODEL_PATH = './tts_model/best_model.pth.tar'
CONFIG_PATH = './tts_model/config.json'
CONFIG = load_config(CONFIG_PATH)
use_cuda = False
num_chars = len(phonemes) if CONFIG.use_phonemes else len(symbols)
model = Tacotron(num_chars, CONFIG.embedding_size, CONFIG.audio['num_freq'], CONFIG.audio['num_mels'], CONFIG.r, attn_windowing=False)
num_chars = len(phonemes) if CONFIG.use_phonemes else len(symbols)
model = Tacotron(num_chars, CONFIG.embedding_size, CONFIG.audio['num_freq'], CONFIG.audio['num_mels'], CONFIG.r, attn_windowing=False)
# 加载音频处理器
# CONFIG.audio["power"] = 1.3
CONFIG.audio["preemphasis"] = 0.97
ap = AudioProcessor(**CONFIG.audio)
# 加载模型状态
if use_cuda:
cp = torch.load(MODEL_PATH)
else:
cp = torch.load(MODEL_PATH, map_location=lambda storage, loc: storage)
# 加载模型
model.load_state_dict(cp['model'])
if use_cuda:
model.cuda()
#model.eval()
model.decoder.max_decoder_steps = 1000
return model, ap, MODEL_PATH, CONFIG, use_cuda
ds = load_deepspeech_model()
model, ap, MODEL_PATH, CONFIG, use_cuda = load_tts_model()
class SocketBlueprint(Blueprint):
def __init__(self, sio: AsyncServer, socketio_path, *args, **kwargs):
self.sio = sio
self.socketio_path = socketio_path
super(SocketBlueprint, self).__init__(*args, **kwargs)
def register(self, app, options):
self.sio.attach(app, self.socketio_path)
super(SocketBlueprint, self).register(app, options)
class SocketIOOutput(OutputChannel):
@classmethod
def name(cls):
return "socketio"
def __init__(self, sio, sid, bot_message_evt, message):
self.sio = sio
self.sid = sid
self.bot_message_evt = bot_message_evt
self.message = message
def tts(self, model, text, CONFIG, use_cuda, ap, OUT_FILE):
import numpy as np
waveform, alignment, spectrogram, mel_spectrogram, stop_tokens = synthesis(model, text, CONFIG, use_cuda, ap)
ap.save_wav(waveform, OUT_FILE)
wav_norm = waveform * (32767 / max(0.01, np.max(np.abs(waveform))))
return alignment, spectrogram, stop_tokens, wav_norm
def tts_predict(self, MODEL_PATH, sentence, CONFIG, use_cuda, OUT_FILE):
align, spec, stop_tokens, wav_norm = self.tts(model, sentence, CONFIG, use_cuda, ap, OUT_FILE)
return wav_norm
async def _send_audio_message(self, socket_id, response, **kwargs: Any):
# type: (Text, Any) -> None
"""Sends a message to the recipient using the bot event."""
ts = time.time()
OUT_FILE = str(ts)+'.wav'
link = "http://localhost:8888/"+OUT_FILE
wav_norm = self.tts_predict(MODEL_PATH, response['text'], CONFIG, use_cuda, OUT_FILE)
await self.sio.emit(self.bot_message_evt, {'text':response['text'], "link":link}, room=socket_id)
async def send_text_message(self, recipient_id: Text, message: Text, **kwargs: Any) -> None:
"""Send a message through this channel."""
await self._send_audio_message(self.sid, {"text": message})
class SocketIOInput(InputChannel):
"""A socket.io input channel."""
@classmethod
def name(cls):
return "socketio"
@classmethod
def from_credentials(cls, credentials):
credentials = credentials or {}
return cls(credentials.get("user_message_evt", "user_uttered"),
credentials.get("bot_message_evt", "bot_uttered"),
credentials.get("namespace"),
credentials.get("session_persistence", False),
credentials.get("socketio_path", "/socket.io"),
)
def __init__(self,
user_message_evt: Text = "user_uttered",
bot_message_evt: Text = "bot_uttered",
namespace: Optional[Text] = None,
session_persistence: bool = False,
socketio_path: Optional[Text] = '/socket.io'
):
self.bot_message_evt = bot_message_evt
self.session_persistence = session_persistence
self.user_message_evt = user_message_evt
self.namespace = namespace
self.socketio_path = socketio_path
def blueprint(self, on_new_message):
sio = AsyncServer(async_mode="sanic")
socketio_webhook = SocketBlueprint(
sio, self.socketio_path, "socketio_webhook", __name__
)
@socketio_webhook.route("/", methods=['GET'])
async def health(request):
return response.json({"status": "ok"})
@sio.on('connect', namespace=self.namespace)
async def connect(sid, environ):
logger.debug("User {} connected to socketIO endpoint.".format(sid))
print('Connected!')
@sio.on('disconnect', namespace=self.namespace)
async def disconnect(sid):
logger.debug("User {} disconnected from socketIO endpoint."
"".format(sid))
@sio.on('session_request', namespace=self.namespace)
async def session_request(sid, data):
print('This is sessioin request')
if data is None:
data = {}
if 'session_id' not in data or data['session_id'] is None:
data['session_id'] = uuid.uuid4().hex
await sio.emit("session_confirm", data['session_id'], room=sid)
logger.debug("User {} connected to socketIO endpoint."
"".format(sid))
@sio.on('user_uttered', namespace=self.namespace)
async def handle_message(sid, data):
output_channel = SocketIOOutput(sio, sid, self.bot_message_evt, data['message'])
if data['message'] == "/get_started":
message = data['message']
else:
##receive audio
received_file = 'output_'+sid+'.wav'
urllib.request.urlretrieve(data['message'], received_file)
path = os.path.dirname(__file__)
fs, audio = wav.read("output_{0}.wav".format(sid))
message = ds.stt(audio, fs)
await sio.emit(self.user_message_evt, {"text":message}, room=sid)
message_rasa = UserMessage(message, output_channel, sid,
input_channel=self.name())
await on_new_message(message_rasa)
return socketio_webhook
将上述代码保存为项目目录下的一个文件 socketio_connector.py。
在开始试用之前,还有最后一件事需要完成,就是连接器配置——既然我们已经构建了一个自定义的连接器,所以我们必须告诉 Rasa 使用这个自定义连接器接收用户输入并发回响应。为此,在 Sara 的项目目录中创建一个 credentials.yml 文件,并提供以下详细信息(这里的 socketio_connector 是实现自定义连接器的模块的名称,而 SocketIOInput 是自定义连接器的输入类的名称):
socketio_connector.SocketIOInput:
bot_message_evt: bot_uttered
session_persistence: true
user_message_evt: user_uttered
至此,所有工作就已经完成了!剩下的就是启动助手并与它进行对话,步骤如下:
进入工作目录,在服务器上启动 Rasa 助手:
rasa run --enable-api -p 5005
启动 Rasa 的自定义 action 服务器:
rasa run actions --actions demo.actions
DucklingHTTPExtractor 是 Sara 的其中一个组件。要使用该组件,运行以下命令启动该组件的服务器:
docker run -p 8000:8000 rasa/duckling
启动一个简单的 http 服务器,用于向客户端发送音频文件:
python3 -m http.server 8888
如果你在浏览器中刷新 Rasa 语音界面,就会看到我们构建的语音助手已经准备好对话:
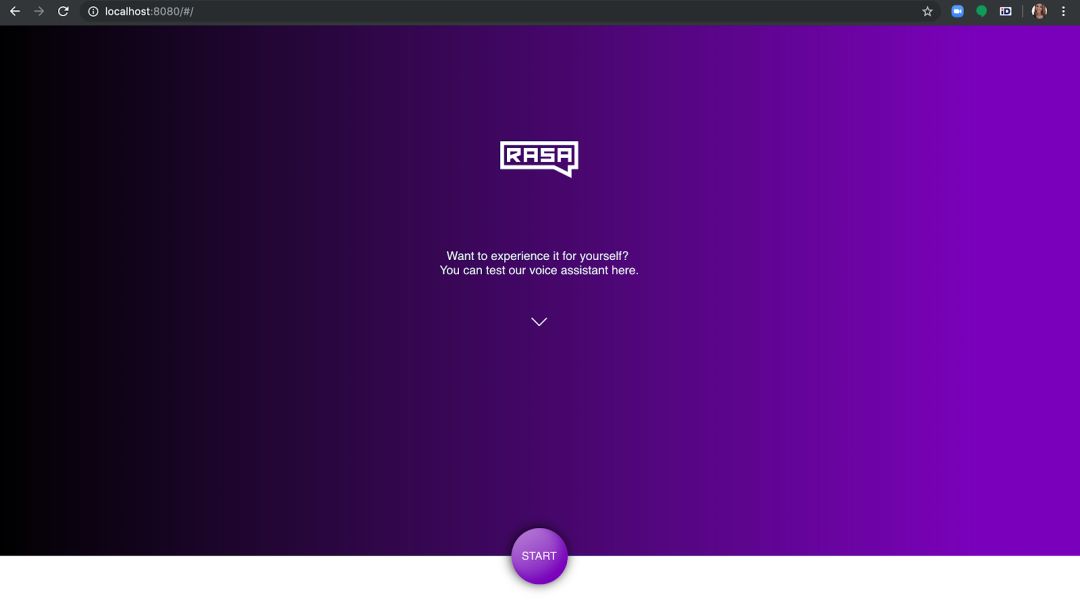
点击开始,与仅使用开源工具构建的语音助手进行对话!
下一步工作语音助手开发带来了一系列全新的挑战——不仅仅是有效的 NLU 和对话,你还需要有效的 STT 和 TTS 组件,而且,你的 NLU 必须足够灵活,可以弥补 STT 所犯的错误。如果你跟随本教程做了这个项目,就会注意到这个助手并不完美,它还有很大的改进空间,尤其是在 STT 和 NLU 阶段。那么如何改进呢?以下是一些建议:
预先训练好的 STT 模型是针对非常通用的数据进行训练的,这使得该模型在更具体的领域中比较容易出错。使用 Mozilla DeepSpeech 构建自定义 STT 模型可以提高 STT 和 NLU 的性能。
改进 NLU 大概可以弥补 STT 所犯的一些错误。提高 NLU 模型性能有一个相当简单的方法,就是增加训练数据,为每个意图提供更多的示例,并向 Rasa NLU 管道添加拼写检查器来纠正一些比较小的 STT 错误。
在 Rasa,为了使开发人员能够构建出了不起的东西,我们一直在寻找方法突破工具和软件的极限。我们希望通过构建这个项目向你展示,使用 Rasa 不仅可以构建文本助手,还可以构建语音助手。同时,我们也希望可以为你带来灵感,让你构建出了不起的应用程序,而又不损害你所使用的工具的安全性和灵活性。你用 Rasa 构建语音助手了吗?你用了什么工具?请在 Rasa 社区论坛上分享你的经验。
Rasa 社区论坛:https://forum.rasa.com/
Rasa 文档:https://rasa.com/docs
Rasa 语音界面:https://github.com/RasaHQ/rasa-voice-interface
查看英文原文:
https://blog.rasa.com/how-to-build-a-voice-assistant-with-open-source-rasa-and-mozilla-tools/

你也「在看」吗??















 887
887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









