






码字不易,欢迎给个赞!
欢迎交流与转载,文章会同步发布在公众号:机器学习算法全栈工程师(Jeemy110)
图像分割是计算机视觉中除了分类和检测外的另一项基本任务,它意味着要将图片根据内容分割成不同的块。相比图像分类和检测,分割是一项更精细的工作,因为需要对每个像素点分类,如下图的街景分割,由于对每个像素点都分类,物体的轮廓是精准勾勒的,而不是像检测那样给出边界框。

图像分割可以分为两类:语义分割(Semantic Segmentation)和实例分割(Instance Segmentation),其区别如图2所示。
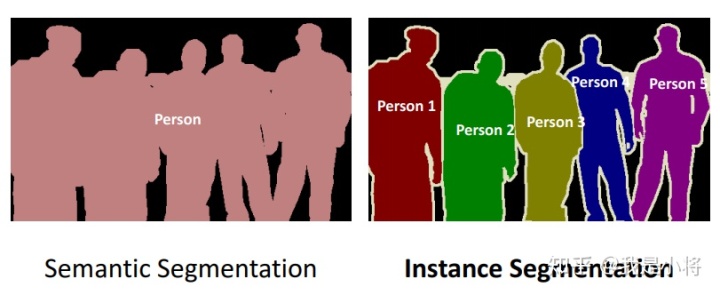
可以看到语义分割只是简单地对图像中各个像素点分类,但是实例分割更进一步,需要区分开不同物体,这更加困难,从一定意义上来说,实例分割更像是语义分割加检测。这里我们主要关注语义分割。
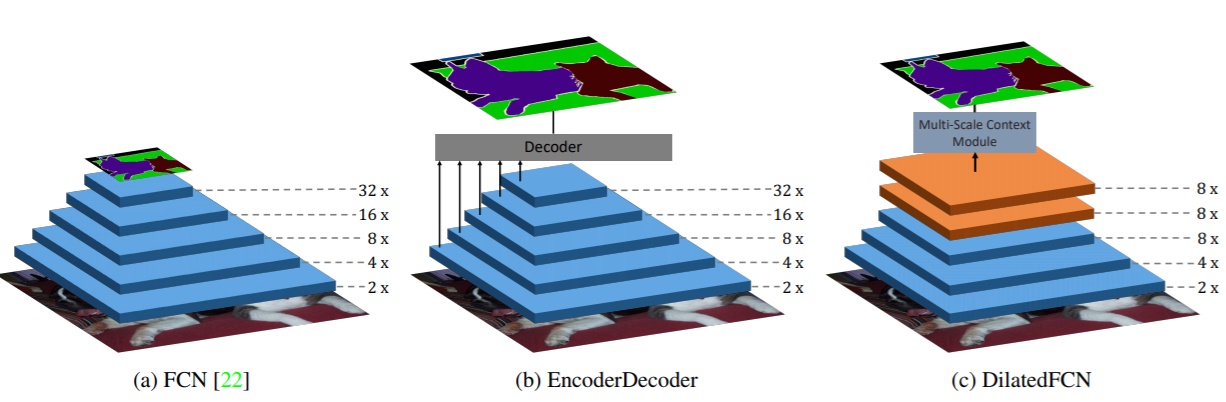
与检测模型类似,语义分割模型也是建立是分类模型基础上的,即利用CNN网络来提取特征进行分类。对于CNN分类模型,一般情况下会存在stride>1的卷积层和池化层来降采样,此时特征图维度降低,但是特征更高级,语义更丰富。这对于简单的分类没有问题,因为最终只预测一个全局概率,对于分割模型就无法接受,因为我们需要给出图像不同位置的分类概率,特征图过小时会损失很多信息。其实对于检测模型同样存在这个问题,但是由于检测比分割更粗糙,所以分割对于这个问题更严重。但是下采样层又是不可缺少的,首先stride>1的下采样层对于提升感受野非常重要,这样高层特征语义更丰富,而且对于分割来说较大的感受野也至关重要;另外的一个现实问题,没有下采样层,特征图一直保持原始大小,计算量是非常大的。相比之下,对于前面的特征图,其保持了较多的空间位置信息,但是语义会差一些,但是这些空间信息对于精确分割也是至关重要的。这是语义分割所面临的一个困境或者矛盾,也是大部分研究要一直解决的。
对于这个问题,主要存在两种不同的解决方案,如图3所示。其中a是原始的FCN(Fully Convolutional Networks for Semantic Segmentation),图片送进网络后会得到大小降为32x的特征图,虽然语义丰
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 363
363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









