







 本文综述了图像分割领域的多种算法,包括语义分割、实例分割和全景分割等,并介绍了FCN、Mask R-CNN、SOLOv2等经典模型的工作原理及创新点。
本文综述了图像分割领域的多种算法,包括语义分割、实例分割和全景分割等,并介绍了FCN、Mask R-CNN、SOLOv2等经典模型的工作原理及创新点。
目录
FCN(Fully Convolutional Networks 全卷积网络)
PSPNet(Pyramid Scene Parsing Network 金字塔场景解析网络)
FCIS(Fully Convolutional Instance-aware Semantic Segmentation 全卷积语义实例分割网络)
SOLOv1: Segmenting Objects by Locations(2020)
Mask2Former(2022 可以做语义、实例、全景分割 Masked-attention Mask Transformer for Universal Image Segmentation)
四个层次:物体分割(普通分割)、语义分割、实例分割、全景分割
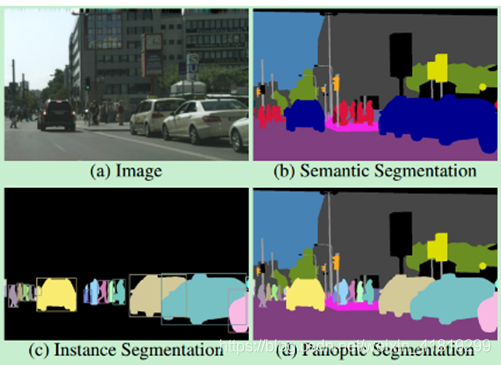
物体分割(利用灰度值的不连续性及相似性,做前景、背景的分割,不区分主体)比如psenet等用分割的方法检测文字
全景分割(对图中的所有物体包括背景都要进行检测和分割)
语义分割(像素级分类)
包含:FCN、SegNet、DeepLab、RefineNet、PSPNet
常用数据集如下:

FCN(Fully Convolutional Networks 全卷积网络)
FCN的学习及理解(Fully Convolutional Networks for Semantic Segmentation)_moonuke的博客-CSDN博客_fcn

1)虚线以上是全卷积提取特征,最后2层用卷积替代了分类网络(如vgg)的全连接,蓝色为卷积,绿色为池化
2)batch_size 为1,当输入图像大小为H*W*C,输出大小为H*W*(1+CLASS),加了一个背景类。此图H*W*C=500*500*C,CLASS=20。不包含全连接层的全连接网络,可以适应任意尺寸的输入
3)虚线以下:
crop(灰色):裁剪成同样尺寸
eltwise(黄色):融合两个层
反卷积|上采样(橙色):为获得与原图同样的HW
4)SKIP跨层连接(类似resnet)操作。skip融合3层信息,结果更精细
5)这个网络并不好训练,需要分4步分阶段训练,详见链接
扩展阅读:
Concat层和Eltwise层对比解析
caffe | Concat层和Eltwise层对比解析_努力努力再努力tq的博客-CSDN博客_eltwise
SegNet
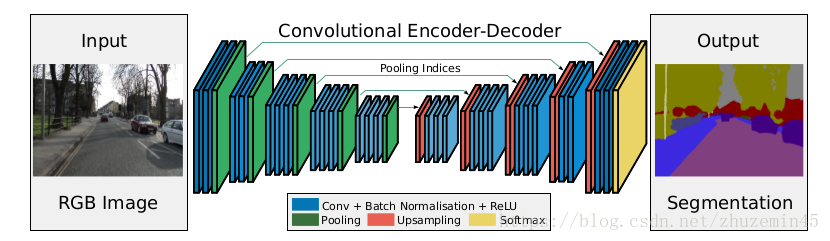
1)基于FCN,基于VGG实现了编解码
2)index机制(segnet最大特色)
在池化过程中记录选出值的相对位置
在pooling图中,左图为原始featuremap,右下为最大池化结果,右上记录了每个最大值的位置
在unpooling图中,featuremap根据对应的index信息实现尺寸变大。对应到上图中,解码过程中,蓝色图 结合 对称绿色的index信息,实现尺寸变大
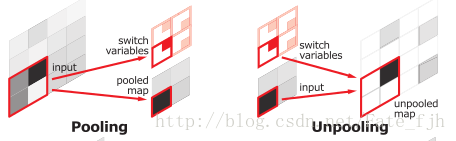
与FCN相比,FCN需要用到转置卷积实现上采样,用index不需要学习
3)解码器中的卷积是为了丰富上采样变大图像的信息,因为除了index对应位置,其他位置还是0,需要用卷积来丰富一下
PSPNet(Pyramid Scene Parsing Network 金字塔场景解析网络)

Semantic Segmentation--Pyramid Scene Parsing Network(PSPNet)论文解读_DFann的博客-CSDN博客
作者的意思是用这个金字塔多尺度信息更多的考虑了上下文和全局信息,减少一些不良情况:水上的是船而不是车;一个大楼不该分成好几块;枕头和被子用了四件套但也应该分出来
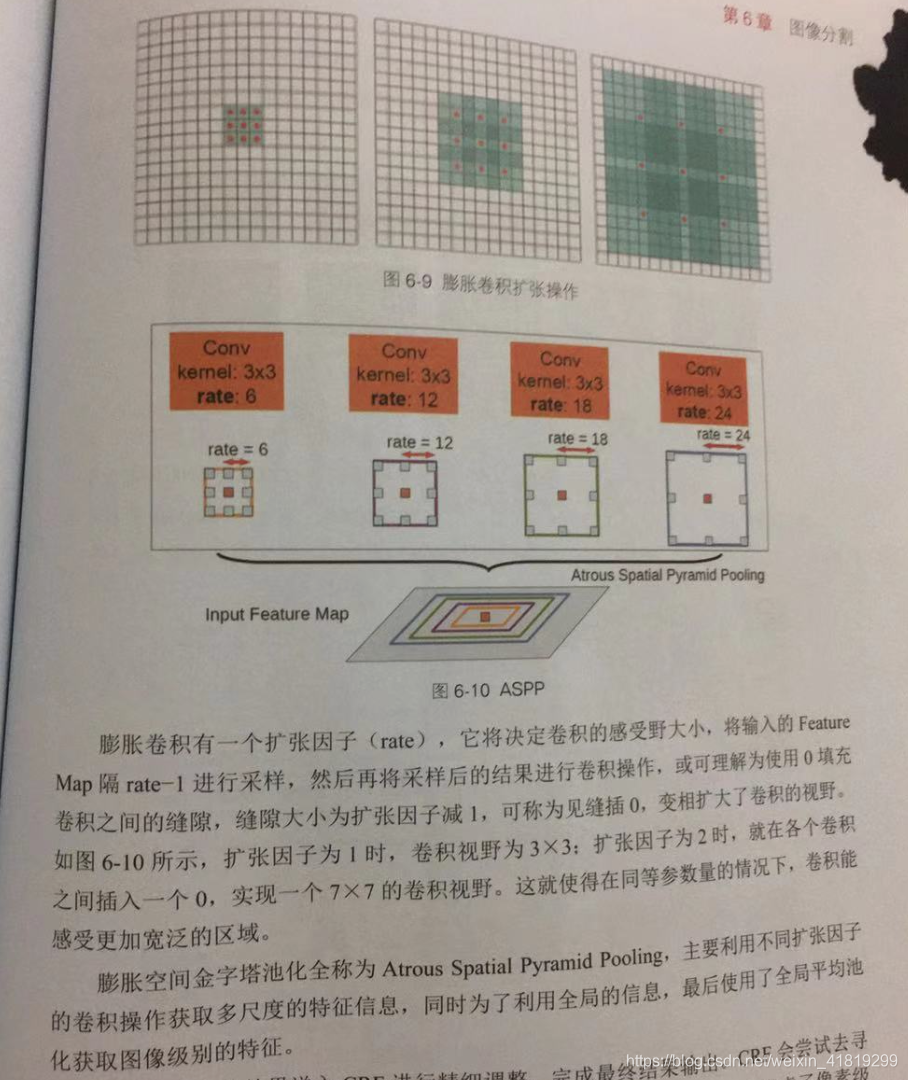
DeepLab
有 v1、v2、v3、v3+ 这一系列网络,用到再具体了解其间但区别,需要注意的是自v2开始用到了膨胀卷积(又名空洞卷积)技术,及膨胀空间金字塔池化(ASPP,用不同扩张因子的卷积获取多尺度特征信息)
实例分割(可区分同一类别的不同主体)
包含:Mask RCNN、FCIS、MaskLab、PANet
三大流派:
一、Detection-based
先检测BBOx后分割
二、Segmentation-based
先粗略分割,后精细分割(基于像素级聚类、利用低层卷积信息)(学习关系亲和场,给每个 pixel 分配一个嵌入式向量,将属于不同实例的 pixel 推远,把属于同一个实例的 pixel 拉近。之后,需要一个后处理来分开每个实例。)
三、solo系列
FCIS(Fully Convolutional Instance-aware Semantic Segmentation 全卷积语义实例分割网络)
脱胎于FCN和InstanceFCN,能同时进行检测与分割。
FCN的缺点:
1)卷积的平移不变性使得卷积对位置信息不敏感,同一像素在子图中会获得同样的响应。利用RFCN的位置敏感得分图得分可以克服(同一像素在不同子图可能有不同语义,比如这张图该像素属于主体,那张图属于背景)。
2)FCN输出通道为(1+class),反应了每个位置的类别信息,但没有每个实例对应的输出。
InstanceFCN:
1)空间金字塔耗时
2)不是端到端,还需要单独的网络判别每个分割候选的类别(即判别语义)
FCIS:同时进行检测与分割,全卷积,端到端
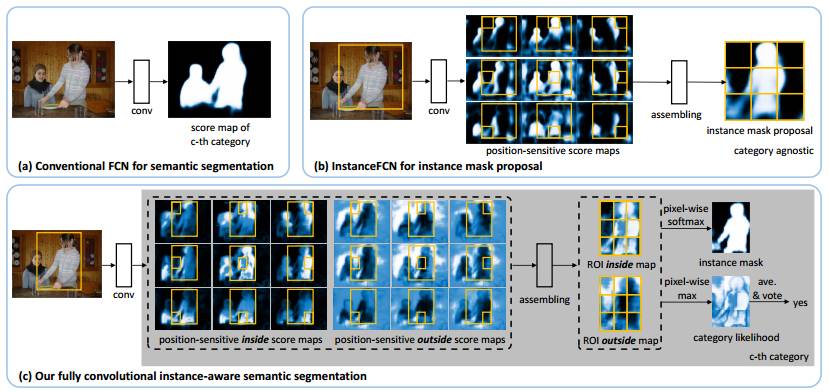
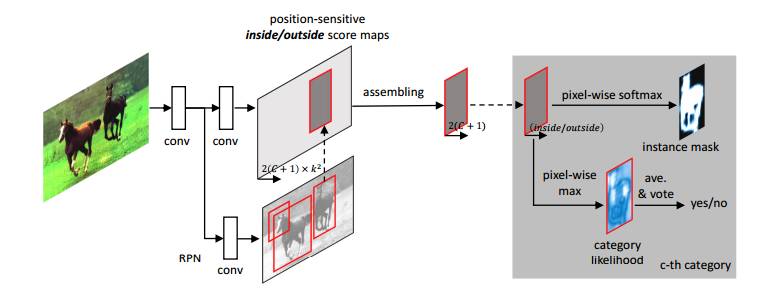
assembling:在roi内部进行,获取像素级得分图
最左侧conv为基网络Resnet,使用RPN网络获取候选区域,每个ROI生成2*K*K*(1+class)的得分图,其中class代表类别数,1为背景,k为宽高划分数量,2为inside+outside(代表内部/外部得分)
检测与分割结合的方法:通过矩形检测框和分割曲线将每个位置分为3种情况:在框外,框内曲线外,曲线内。对应的2个分数为低低,低高,高高。用softmax和max来表征这两个问题,max负责检测,softmax做分割
MASK R-CNN(2018)
Mask R-CNN原理详细解读_echo_hao的博客-CSDN博客_mask r-cnn
mask R-cnn=Faster rcnn+FCN,Faster rcnn获取ROI,FCN在ROI上获取mask。
ROIAlign(ROI对齐)代替ROI Pooling ,使用双线性插值,不破坏像素到像素的平移同变性
ROI Pooling:将RPN导出的特征图处理为同一尺寸,例如都处理成7*7,引入的问题是信息损失坐标偏移,无法从这个7*7对应到原图上,对检测中的分类无影响,但会影响分割精度。一张rgb的原图要得到这个7*7的信息,需要经历2次量化信息损失。原图到feature map,由于检测框的位置不可能都是2的n次方,这里引入来第一次量化,取ROI后处理为7*7,引入第二次量化。
ROIAlign跳出了坐标都是整数这个思维限制,不使用量化,用了虚拟点的概念,原来ROI池化要对应到最近一个的点的值,现在ROI对齐用最近四个点的值做双线性插值


Masklab
与deeplab同一作者
masklab=bbox检测+语义分割+方向检测+微调
bbox检测:Faster rcnn检测回归框
语义分割:根据回归框的类别逐个像素预测标签
方向检测:获取每个像素对应中心的方向角
微调:上面几步获取了一个粗略的分割结果,再结合低层的feature map做精细化
PANet(用于实例分割的路径聚合网络)
【实例分割】PANet简单笔记 - wuzeyuan - 博客园
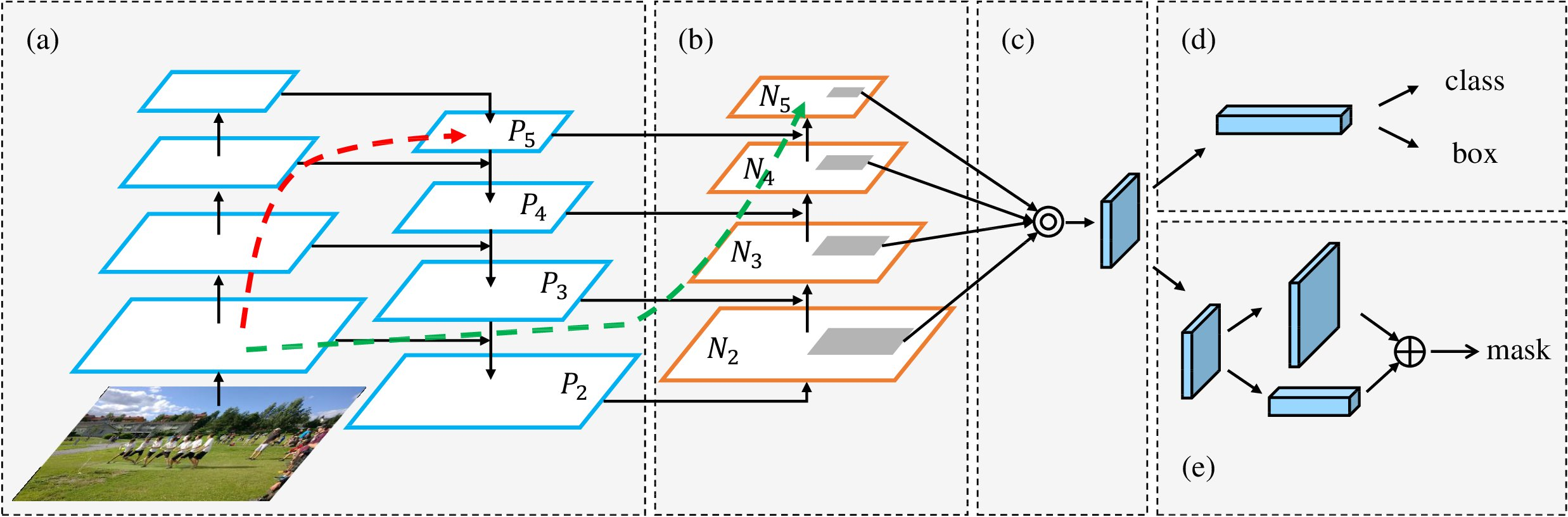
可视为 mask rcnn加强版,主要有以下几个特点
1)双塔战术:普通的FPN如图a,PANet又做了一层自底向上金字塔,如图b,加强底层信息(对边缘线条及纹理敏感)
2)动态特征池化:每个候选区域融合了多层特征层的信息,如图b的灰色区域
3)全连接层融合:图e的上半部分为原来的FCN,是每个类别的二分类信息,下半部分为PANet增加的分支,是前背景的二分类结果。融合FCN和全连接层的信息,可提升mask的效果。
SOLOv1: Segmenting Objects by Locations(2020)
【实例分割】1、SOLOv1: Segmenting Objects by Locations_2019_呆呆的猫的博客-CSDN博客_solov1
实例分割新思路之SOLO v1&v2深度解析 - 腾讯云开发者社区-腾讯云
前提:
- 98.3% 的目标的中心距离大于 30 pixels
- 剩余1.7% 的目标,其中 40.5% 的大小之比大于 1.5x
也就是说大部分目标中心点距离远,距离近的目标有一半大小差别大,总之中心点不同或大小不同。在语义分割中,每个类别有个通道,在实例分割中,每个实例需要有一个通道。solo作者提出的中心点位置和大小统计信息,可以推出,不同实例可以根据中心点位置(与格子对应mask有关)和大小(与FPN对应通道有关)分配到不同的通道上,实现近距离同语义的实例的区分。也就是这篇论文的含义“Segmenting Objects by Locations”

输入图像被分为S*S的格子,中间上半部分负责预测类别,尺寸为S*S*C,C为类别数量,;下半部分负责分割mask,尺寸为H*W*S*S,对每个 positive grid cell 产生一个对应的 instance mask。
分类分支:划分S*S个格子,gt是不规则的,而不是正方形。对gt的质心等比例缩小(如0.2)后,缩小后的box落在某几个格子上。这个格子对应的分类分支和mask分支即为正样本,否则为负样本。
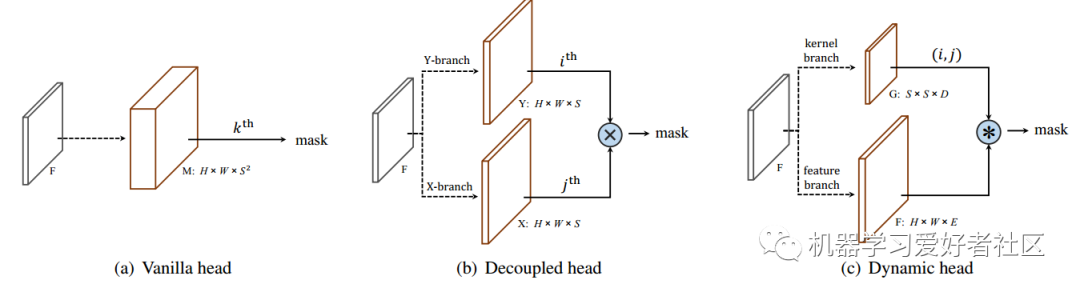
Mask分支:大小为H*W*S*S,S*S是按照SxS拆分格子最大的实例个数。(I,j)的格子对应的mask通道为I*S+J。为降维,提出了解耦head(Decoupled head)。将S*S拆分为X分支和Y分支的2*S通道,要获取(i,j)格子对应的mask,将X分支第i个通道和Y分支的j通道进行相乘即可
FPN特征金字塔:设置scale_ranges=((1, 96), (48, 192), (96, 384), (192, 768), (384, 2048)),相邻区间存在重叠。对gt的面积开根号,属于哪个区间则对应区间负责该gt的预测。由于区间重叠,会出现1个gt对应多个fpn层(一般是2个)
CoordConv:给卷积加上坐标。卷积是位置不敏感的,但实例分割需要对位置敏感。在一般的特征后cat上x和y坐标的信息。这里的坐标是[-1,1]之间的虚拟坐标,即归一化后的 pixel 坐标。
ins_feat = x # 当前实例特征tensor
# 生成从-1到1的线性值
x_range = torch.linspace(-1, 1, ins_feat.shape[-1], device=ins_feat.device)
y_range = torch.linspace(-1, 1, ins_feat.shape[-2], device=ins_feat.device)
y, x = torch.meshgrid(y_range, x_range) # 生成二维坐标网格
y = y.expand([ins_feat.shape[0], 1, -1, -1]) # 扩充到和ins_feat相同维度
x = x.expand([ins_feat.shape[0], 1, -1, -1])
coord_feat = torch.cat([x, y], 1) # 位置特征
ins_feat = torch.cat([ins_feat, coord_feat], 1) # concatnate一起作为下一个卷积的输入SOLOv2(2020)
SOLOv2算法解读_‘Atlas’的博客-CSDN博客_solov2
主要有2个改进点:dynamic head、matrix NMS
动态mask head(dynamic head):v1中将S*S的通道解耦成X分支+Y分支的2*S通道,v2解耦为kernel核分支和feature特征分支,分别负责卷积核和卷积特征的学习。提取mask时,用核分支的tensor作为卷积核对特征分支进行1*1的卷积。
kernel分支:S*S*D,D与输入特征有关
# 直接进行双线性插值,尺度变化为: [1,256+2,h,w] -> [1,256+2,S,S]
# 这里的256+2同样利用了CorrdConv,S为grid cell的个数
kernel_feat = F.interpolate(kernel_feat, size=seg_num_grid, mode='bilinear')
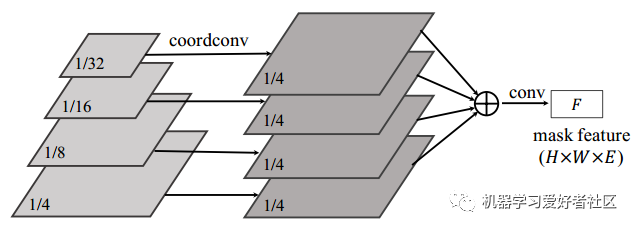
#后续还有一些卷积操作,最终输出的tensor为[1,256,S,S]feature分支: H*W*E,将FPN输出的多层特征图通过卷积+上采样融合为1个tensor
矩阵NMS(matrix NMS):通过并行矩阵运算加速,1ms内处理500张mask,集合soft mask(对高iou框做惩罚,防止误删)、Fask mask(上三角矩阵,按列取最大值,提速)、mask求iou的优点
如果用solo,S*S默认为7*7,注意能否应对场景需求。
Mask2Former(2022 可以做语义、实例、全景分割 Masked-attention Mask Transformer for Universal Image Segmentation)
https://blog.csdn.net/bikahuli/article/details/121991697
一种基于transformer的分割网络,架构为:主干网络+像素解码器+Transformer解码器。
目前(2023.01.10)是mmdet做实例分割的最新方法,backbone可以选择resnet或swin-transformer,Swin效果更好一点。。

主干网络:获取高层特征图
像素解码器:将高层特征图尺寸变大
Transformer解码器:引入掩码注意力机制,在transformer的计算的QK后加上掩码(0或负无穷),将交叉注意力限制在预测的掩码区域内来提取局部特征。



efficient multi-scale strategy:多尺度解码器输出逐渐加入attention中。
EVA: Exploring the Limits of Masked Visual Representation Learning at Scale
作者认为当前的MIM预训练过于依赖有监督或弱监督的数据,将最强语义学习(CLIP)与最强几何结构学习(MIM)结合,未设计特殊网络结构,使用标准的ViT-g模型,并将其规模扩大到十亿参数(1-Billion),下游可用于分类、检测、分割等任务,多个榜单第一(2023.01)。
模型的3个重要构成:模型结构、数据、训练方式,近期很多工作不再专注于设计特殊的网络结构,主要是通过特殊的训练方式扩大训练参数量,如clip、eva。同时数据也倾向于不严重依赖人工标注,这样才能快速获得大量数据进行训练。大参数量模型+大数据量+弱化标注。大力出奇迹,用参数量的提升引起性能的提升。
训练方式:联合CLIP和EVA,CLIP输入完整图像,EVA输入mask后的图像,让Eva模型mask部分的输出去预测clip对应位置输出。从而将clip的参数量扩大(scaling up)到eva的十亿参数量。训练eva时只需要纯图像数据,无需标注。
多类别的实例分割效果和少类别时相近,可用于辅助clip的训练,eva clip性能相比 open clip显著提升。


















 1457
1457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









