





Xgboost (eXtreme Gradient Boosting)是大规模并行boosted tree的工具。Xgboost演算法是经历以下的演算法演化而来,后续文章将逐一介绍个演算法
- Bagging演化至Boosting
- Boosting演化至Gradient boosting(GB)
- Gradient boosting(GB)和Decision Tree(DT)演化至Gradient Boosting Decision Tree(GBDT)
- Gradient Boosting Decision Tree(GBDT)演化至eXtreme Gradient Boosting(Xgboost)
Bagging原理
Bagging的概念就是从训练资料中随机抽取(抽后放回,称为bootstrap),建立多组训练样本,训练多组分类器(可自己设定要多少个分类器),每个分类器的权重一致最后透过投票方式(Majority vote)得到最终结果。
*Bagging的優點在於原始訓練樣本中有噪聲資料(不好的資料),透過Bagging抽樣就有機會不讓有噪聲資料被訓練到,所以可以降低模型的不穩定性
Boosting原理
Boosting概念是,对一份数据,建立M个模型(比如分类),一般选择的模型比较简单,称为弱分类器(weak learner)每次分类都将上一次分错的数据权重提高一点再进行分类,这样最终得到的分类器在测试数据与训练数据上都可以得到比较好的成绩。
Boosting的公式如下:
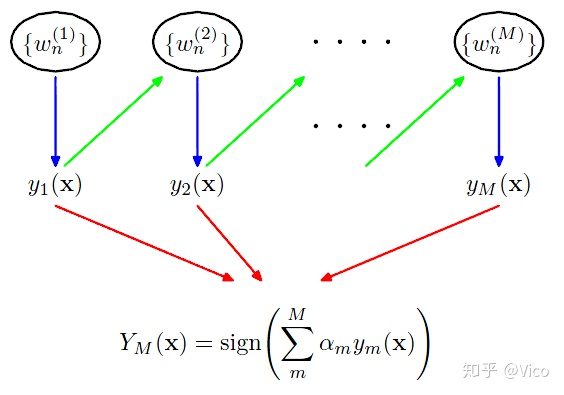
*Boosting将注意力集中在分类错误的资料上,因此Boosting对训练资料的噪声非常敏感,如果一笔训练资料噪声资料很多,那后面分类器都会集中在进行噪声资料上分类,反而会影响最终的分类性能。
GB(Gradient boosting)原理
Gradient Boosting是一种Boosting的方法,主要的概念是让每次建立模型是能够逐渐让损失函数(loss function)持续下降,代表模型不断在改进,而最好的方式就是让损失函数在其梯度(Gradient)的方向上下降。
举例:
- Input为x、Output为y
- 建立一个简单一层的回归树预测模型F(x),F(x)预测出来的值与真实值y的差额为Residual
- 为了提升F(X)的预测能力,再透过Input为x、output为Residual建立一个h(x)
- 因此得到了新的模型为H(x) = F(x) + h(x),并祈望预测能力比F(x)好
- 重复2-4的方法......
- 可以得到F(x) + h(x) + n(x) + g(x).....的预测模型
Gradient Descent 是一个在最佳化领域相当常见的迭代方法,用于寻找「可微分函数」的局部最小值,它的做法是这样的:
- 假设我们要最佳化的目标函数是 L(x),例如要找 L(x) 的最小值
- 随机选取一个起始点,例如从 a 出发
- 从 a 沿着 −∇L(a)走一小步,即 a−γ∇L(a),此处的 ∇L(a) 代表的是 L 在 a 上的 Gradient,那么对于一个够小的 γ,此处的函数值将小于等于 L(a)
- 当有一个够小的 γ,我们将有L(a)≥L(a−γ∇L(a))
- 令 a−γ∇L(a) 为新的出发点,重复 3–4
- 根据这样的方法,从 a 开始一步一步走(迭代),在 γ 选取适当的情况下,我们可以找到 L(x) 的局部最小值
GB称为Gradient的原因在于对于每次的Residual进行计算时加入了控制步伐大小的 γ 称作 Learning Rate,数学原理如下:
- y和F(x))的MSE为L(y, F(x))= (y−F(x))²
- 偷改造一下MSE为L(y, F(x))= (y−F(x))² / 2
- 对F(x)偏微分∂L/∂F = −(y−F),在使用 MSE Loss 的情况下,Residual 正是 Loss 对 F 的 Gradient 取负号(在 x 处取值)
- 两边同乘负号为y−F=−∂L/∂F
- 如果把H(x)=F(x)+h(x) 视作对F(x) 的更新
- 那么根据h(x)≈y−F(x)=−∂L/∂F,其实正如上述Gradient Descent 中的第三步,∂L/∂F为一个朝局部最小值移动的一个变动
- 因此H(x)=F(x)−γ∂L/∂F, 而γ为Learning Rate
DT(Decision Tree)原理
Decision Tree是采用CART (Classification and Regression Trees)算法来进行,执行的步骤为以下两大步骤:
- 决策树生成:递归地构建二叉决策树的过程,基于训练数据集生成决策树,生成的决策树要尽量大。分类问题可采用GINI,双化或有序双化;回归问题可采用最小二乘偏差(LSD)或最小绝对偏差(LAD)。
- 决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这时损失函数最小作为剪枝的标准。
GBDT(Gradient Boosting Decision Tree)原理
GBDT为GB+DT两大核心组合而成(不论是分类或是回归问题皆可处里)。GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。比如A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学。这就是Gradient Boosting在GBDT中的意义。
简单的训练集只有4个人,A,B,C,D,他们的年龄分别是14,16,24,26。其中A、B分别是高一和高三学生;C,D分别是应届毕业生和工作两年的员工。如果是用一棵传统的回归决策树来训练,会得到如下图1所示结果:

现在我们使用GBDT来做这件事,由于数据太少,我们限定叶子节点做多有两个,即每棵树都只有一个分枝,并且限定只学两棵树。我们会得到如下图2所示结果:
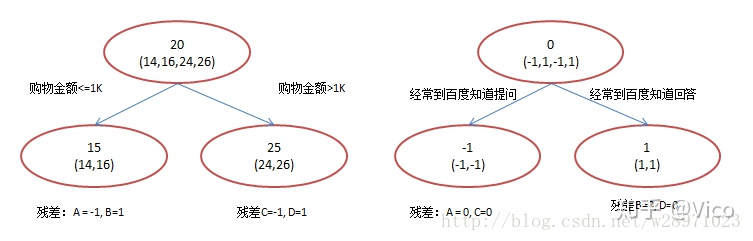
上图说明如下:
- 图左:以20岁为中心建立预测为15岁和25岁的二叉树,由于A,B年龄较为相近,C,D年龄较为相近,他们被分为两拨。并计算A,B对15岁的残差,C,D对25岁的残差,进而得到A,B,C,D的残差分别为-1,1,-1,1。
- 图右:将A,B,C,D的残差拿至第二棵树去学习,进行预测在拿到了得到A,B,C,D的残差为0,即每个人都得到了真实的预测值。
Xgboost(eXtreme Gradient Boosting)原理
Xgboost也是属于GBDT之中的其中一种,同样可以应用于分类与回归问题,gradient boosting 的实现是比较慢的,因为每次都要先构造出一个树并添加到整个模型序列中。
XGBoost 的特点就是计算速度快,模型表现好,依照XGBoost: A Scalable Tree Boosting Systemr 说明主要的原因有以下四个原因:
- Parallelization:训练时可以用所有的 CPU 内核来并行化建树。
- Distributed Computing :用分布式计算来训练非常大的模型。
- Out-of-Core Computing:对于非常大的数据集还可以进行 Out-of-Core Computing。
- Cache Optimization of data structures and algorithms:更好地利用硬件。
透过以下范例说明Xgboost:
(1) Regression Tree Ensemble 回归树集成
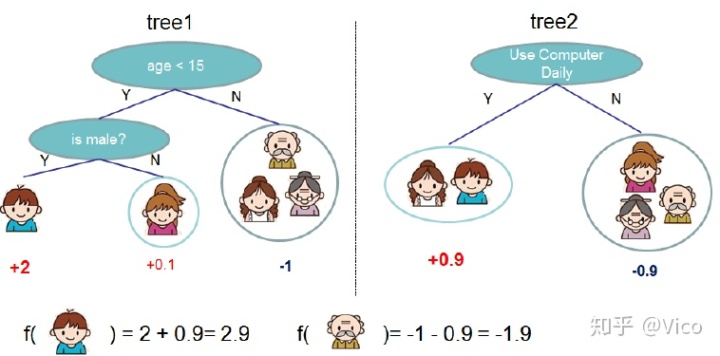
建立两颗树分别进行预测,并且把两个树的误差值加总。接下来分别说明进行GB和DT
(2)GB
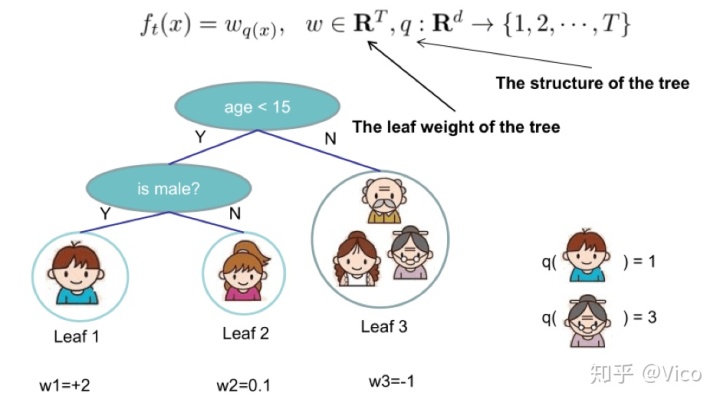
*透过公式的推导可以发现Xgboost与GBDT的差异在于Xgboost透过泰勒式二阶近似

第t轮的模型预测等于前t-1轮的模型预测y(t-1)加上ft,因此误差函式项记为l(yi,y(t-1) ft),后面一项为正则化项。在当前步,yi以及y(t-1)都是已知值,模型学习的是ft。

把平方损失函式的一二次项带入原目标函式,你会发现与之前的损失函式是一致的 。至于为什么要这样展开呢,这里就是xgboost的特殊,通过这种近似,你可以自定义一些损失函式(只要保证二阶可导),树分裂的打分函式是基于gi,hi(Gj,Hj )计算的。
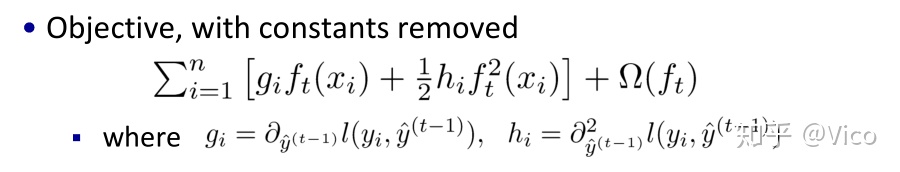
目标函式保留了泰勒展开的二次项。
(3)DT

从图中可以看出,xgboost算法中对树的复杂度项增加了一个L2正则化项,针对每个叶结点的得分增加L2平滑,目的也是为了避免过拟合

经过范例的计算只需要总结每个叶子上的梯度和二阶梯度统计量,然后应用得分公式来获得质量得分。
xgboost特點(與gbdt對比)
1.传统GBDT以CART作为基分类器,xgboost还支援线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)
2.传统GBDT在优化时只用到一阶导数资讯,xgboost则对损失函式进行了二阶泰勒展开,同时用到了一阶和二阶导数,对损失函数进行了改进。
3.xgboost在损失函式里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2的平方和。从Bias-variance tradeoff角度,正则项降低了模型variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性
4.shrinkage and column subsampling
(1)shrinkage缩减类似于学习速率,在每一步tree boosting之后增加了一个引数n(权重),通过这种方式来减小每棵树的影响力,给后面的树提供空间去优化模型。
(2)column subsampling列(特征)抽样,防止过拟合的效果比传统的行抽样还好,并且有利于并行化处理演算法。
5.split finding algorithms(划分点查询演算法)
(1)exact greedy algorithm—贪心演算法获取最优切分点
(2)approximate algorithm—近似演算法,提出了候选分割点概念,先通过直方图演算法获得候选分割点的分布情况,然后根据候选分割点将连续的特征资讯对映到不同的buckets中,并统计汇总资讯。
(3)Weighted Quantile Sketch—分散式加权直方图演算法
*这里的演算法(2)、(3)是为了解决资料无法一次载入记忆体或者在分散式情况下演算法(1)效率低的问题,说明如下:
可并行的近似直方图演算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法列举所有可能的分割点。当资料无法一次载入记忆体或者在分散式情况下,贪心演算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图演算法,用于高效地生成候选的分割点。
6.对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向(稀疏感知演算法)
7.Built-in Cross-Validation(内建交叉验证)
8.continue on Existing Model(接着已有模型学习)
9.High Flexibility(高灵活性)
10.并行化处理—系统设计模组,块结构设计等
xgboost还设计了快取记忆体压缩感知演算法,这是系统设计模组的效率提升。当梯度统计不适合于处理器快取记忆体和快取记忆体丢失时,会大大减慢切分点查询演算法的速度。
(1)针对 exact greedy algorithm采用快取感知预取演算法
(2)针对 approximate algorithms选择合适的块大小
参考资料:
机器学习中的数学(3)-模型组合(Model Combining)之Boosting与Gradient Boosting
CART 分类与回归树
https://www.zhihu.com/question/41354392/answer/98658997
A Kaggle Master Explains Gradient Boosting
https://blog.csdn.net/w28971023/article/details/8240756
https://www.kdd.org/kdd2016/papers/files/rfp0697-chenAemb.pdf
https://medium.com/@chih.sheng.huang821/%E6%A9%9F%E5%99%A8%E5%AD%B8%E7%BF%92-ensemble-learning%E4%B9%8Bbagging-boosting%E5%92%8Cadaboost-af031229ebc3
https://codertw.com/%E7%A8%8B%E5%BC%8F%E8%AA%9E%E8%A8%80/635146/















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









