







满帮集团,作为“互联网+物流”的平台型企业,一端承接托运人运货需求,另一端对接货车司机,提升货运物流效率。2021 年美股上市,成为数字货运平台上市第一股。根据公司年报,2021 年,超过 350 万货车司机在平台上完成超 1.283 亿个订单,实现总交易价值 GTV 2623 亿元,占中国数字货运平台份额超 60%。2022 年 10 月,运满满司机版 MAU 达到 949.21 万人,货车帮司机版 MAU 为 399.91 万人;运满满货主版 MAU 为 218.68 万人,货车帮货主版 MAU 为 63.78 万人。(以下内容基于满帮实践,由聪言、子葵整理)
业务增长对服务稳定性的挑战
Aliware
满帮集团在业务生产环境中自建微服务网关,负责南北方向流量调度、安全防护以及微服务治理,同时考虑到多活容灾能力还提供了诸如同机房优先调用、容灾跨机房调用等机制。微服务网关作为微服务架构前端的组件,充当了所有微服务的流量入口。客户端的请求进来会先打到 ALB(负载均衡),然后到内部的网关,再通过网关路由到具体的业务服务模块。
所以网关需要通过一个服务注册中心来动态发现当前生产环境部署的所有微服务实例,当部分服务实例因故障而无法提供服务时,网关还可以跟服务注册中心搭配工作,自动将请求转发到健康的服务实例上,实现故障转移和弹性,使用自研框架配合服务注册中心实现服务间调用,同时使用自建配置中心实现配置管理和变更推送,满帮集团最早采用了开源 Eureka,ZooKeeper 来搭建集群实现服务注册中心和配置中心,这套架构也很好的承接了满帮集团前期的业务快速增长。
但是随着业务体量的逐渐增大,业务模块越来越多,服务注册实例数爆发式增长,自建 Eureka 服务注册中心集群和 ZooKeeper 集群在这套架构的稳定性问题也日益明显。
满帮集团的同学在运维的时候发现自建的 Eureka 集群在服务注册实例到达 2000+ 规模的时候,由于 Eureka 集群节点之间在做实例注册信息同步的时候,部分节点处理不过来,很容易出现节点挂掉无法提供服务最终引发故障的问题;ZooKeeper 集群频繁 GC 导致服务间调用和配置发布出现抖动,影响整体稳定性,并且由于 ZooKeeper 默认没有任何开启鉴权和身份认证能力,配置存储面临安全挑战,这些问题也给业务的稳定持久发展带来了很大的挑战。
业务架构平滑迁移
Aliware
在上述业务背景下,满帮同学选择了紧急上云,采用阿里云 MSE Nacos,MSE ZooKeeper 产品来替换原先的 Eureka 和 Zookeeper 集群,但是如何才能做到低成本快速的架构升级,以及上云期间业务流量的无损平滑迁移呢?
在这个问题上,MSE Nacos实现了对开源 Eureka 原生协议的完全兼容,内核仍然由 Nacos 驱动,业务适配层把 Eureka InstanceInfo 数据模型和 Nacos 的数据模型(Service 和 Instance)做了一一映射。而这一切对于满帮集团已经对接过自建 Eureka 集群的业务方而言,做到了完全透明。
这就意味着,原先的业务方在代码层面上完全不用改动,只需要把 Eureka Client 连接的服务端实例 Endpoint 配置修改成 MSE Nacos 的 Endpoint即可。使用上同样也很灵活,既可以继续使用原生的 Eureka 协议把 MSE Nacos 实例当成一个 Eureka 集群来用,也可以 Nacos、Eureka 客户端双协议并存,不同协议的服务注册信息之间支持互相转换,从而保证业务微服务调用的连通性。
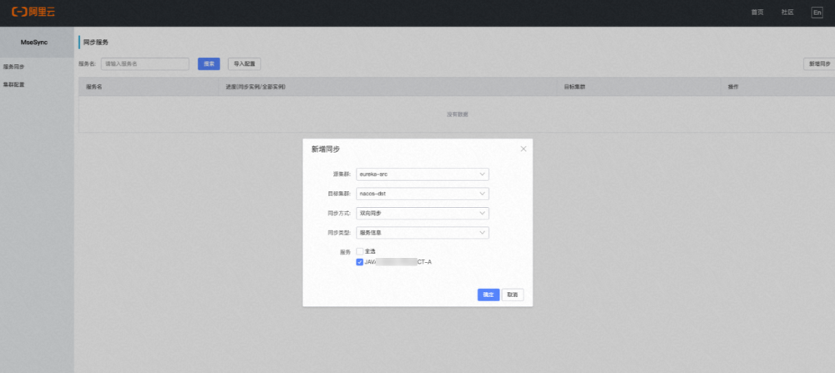
另外在上云过程中,MSE 官方提供了 MSE-Sync 解决方案,是一款基于开源 Nacos-Sync 优化后的迁移配套数据同步工具,支持双向同步、自动拉取服务和一键同步的功能。满帮同学通过 MSE-Sync 很轻松的完成原先自建 Eureka 集群上已有的线上服务注册存量数据一键迁移到新的 MSE Nacos 集群,同时后续在老的集群上新注册的增量数据也会源源不断的自动获取同步到新集群,这样就保证了在业务实际切流迁移之前,两边的集群服务注册实例信息始终是完全一致的。待数据同步 check 通过之后,将原先的 Eureka Client 的 Endpoint 配置进行替换,重新发布升级后就成功的迁移到新的 MSE Nacos 集群了。
突破原生 Eureka 集群架构性能瓶颈
Aliware
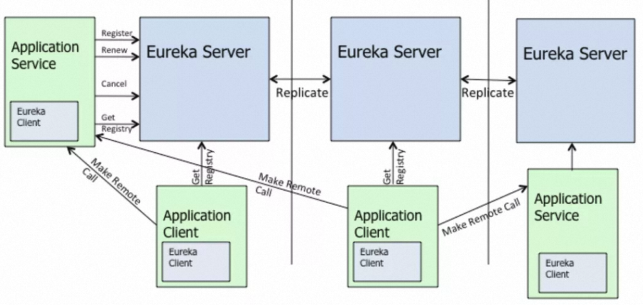
满帮集团在找到 MSE 团队合作技术架构升级的时候,提出的最重要的一条诉求,就是要解决原先 Eureka 集群间服务注册信息同步压力大的问题,这其是因为 Eureka Server 是传统的对等星型同步 AP 模型导致的,各个 Server 节点角色相等完全对等,对于每次变更(注册/反注册/心跳续约/服务状态变更等)都会生成相应的同步任务来用于所有实例数据的同步,这样一来同步作业量随着集群规模、实例数正相关同步上涨。
满帮集团同学实践下来,当集群服务注册规模达到 2000+ 的时候,发现部分节点 CPU 占用率、负载都很高,时不时还会假死导致业务抖动。这一点在 Eureka 官方文档也有提及,开源 Eureka 的这种广播复制模型,不仅会导致它自身的架构脆弱性,也影响了集群整体的横向扩展性。
Replication algorithm limits scalability: Eureka follows a broadcast replication model i.e. all the servers replicate data and heartbeats to all the peers. This is simple and effective for the data set that eureka contains however replication is implemented by relaying all the HTTP calls that a server receives as is to all the peers. This limits scalability as every node has to withstand the entire write load on eureka.
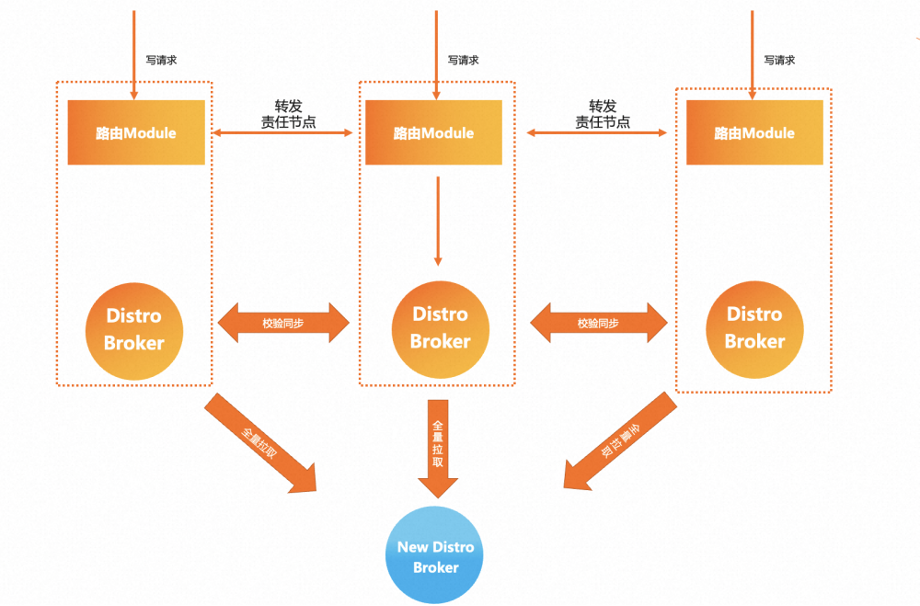
而 MSE Nacos 在架构选型上就考虑到这个问题并给出了更好的解决方案,那就是自研的 AP 模型 Distro 协议,保留了星型同步模型的基础上,Nacos 对所有服务注册实例数据进行了 Hash 散列、逻辑数据分片,为每一条服务实例数据分配一个集群责任节点,每一个 Server 节点仅负责自己 own 的那一部分数据的同步和续约逻辑,同时集群间数据同步的粒度相对于 Eureka 也更小。这样带来的好处是即使在大规模部署、服务实例数据很多的情况下,集群间同步的任务量也能保证相对可控,并且集群规模越大,这样的模式带来的性能提升也愈发明显。
持续迭代优化追求极致性能
Aliware
MSE Nacos 和 MSE ZooKeeper 在完成了满帮集团的全量微服务注册中心业务的承接后,在后续的升级版本中持续迭代优化,通过大量的性能压测对比测试,从各个细节上继续优化服务端性能来优化业务体验,接下来会针对升级版本的优化点逐一分析介绍。
服务注册高可用容灾保护
原生 Nacos 提供了高阶功能:推空保护,服务消费者(Consumer)通过注册中心订阅服务提供者(Provider)的实例列表,当注册中心进行变更或遇到突发情况, 或服务提供者与注册中心间的链接因网络、CPU 等其他因素发生抖动时,可能会导致订阅异常,从而使服务消费者获取到空的服务提供者实例列表。
为了解决这个问题,可以在 Nacos 客户端或 MSE Nacos 服务端开启推空保护功能,以提高整个系统的可用性。我们同样把这个稳定性功能引入到了对 Eureka 的协议支持中,当 MSE Nacos 服务端数据出现异常的时候,Eureka 客户端从服务端拉取数据的时候,会默认得到容灾保护支持,保障业务使用的时候不会拿到不符合预期的服务提供者实例列表,而导致业务故障。
另外 MSE Nacos 和 MSE ZooKeeeper 还提供了多重高可用保障机制,如果业务方有更高的高可靠性和数据安全需求,在创建实例的时候可以选择不少于 3 节点的方式进行部署。当其中某个实例故障的时候,节点间秒级完成切换,故障节点自动离群。同时 MSE 每个 Region 都包含多个可用区,同一个 Region 内不同 Zone 之间的网络延迟很小(3ms 以内),多可用区实例可以将服务节点部署在不同可用区,当可用区 A 出现故障的时候,流量会在很短的时间内切换到另外的可用区 B。整个过程业务方无感知,应用代码层面无感知、无需变更。这一个机制只需要配置多节点部署,MSE 会自动帮你部署到多个可用区进行打散容灾。
支持 Eureka 客户端增量拉取数据
满帮同学在迁移到 MSE Nacos 之后,原先服务端实例假死无法提供服务的问题得到了很好的解决,但是发现机房的网络带宽占用过高,偶尔服务高峰期还会出现带宽打满的情况。后来发现是因为每次 Eureka 客户端从 MSE Nacos 拉取服务注册信息的时候,每次都只支持全量拉取,大几千级别的数据量定时拉取,导致网关层面的 FGC 次数也升高了很多。
为了解决这个问题,MSE Nacos 上线了针对 Eureka 服务注册信息的增量拉取机制,配合上客户端使用方式的调整,客户端只需要在首次启动后拉取一次全量数据,后续只需要根据增量数据来保持本地数据和服务端数据的一致性,不再需要周期性的全量拉取,而正常生产环境中变更增量数据的数据量很小,这样一来可以大幅降低出口带宽的压力。满帮同学在升级了这个优化版本之后,发现带宽从升级前的 40MB/s 一下子降到了 200KB/s,带宽打满问题迎刃而解。
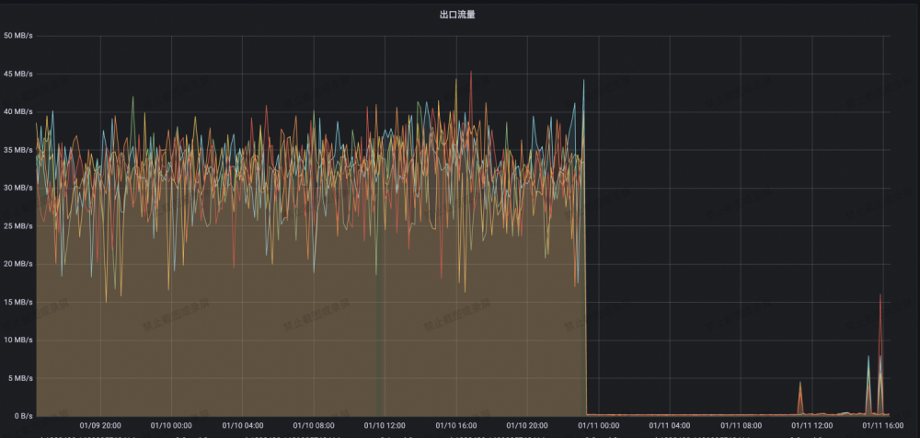
充分压测优化服务端性能
MSE 团队后续对 MSE Nacos 集群 For Eureka 的场景进行了更大规模的性能压测,并通过各种性能分析工具排查业务链路上的性能瓶颈点,对原有功能进行了更多的性能优化和底层性能调参。
针对服务端的全量和增量数据注册信息引入了缓存,并基于服务端数据 hash 来判断是否发生变更。在 Eureka 服务端读多写少的场景下,可以大幅减少了 CPU 计算生成返回结果的性能开销。
发现 SpringBoot 原生的 StringHttpMessageConverter 在处理大规模数据返回的时候存在性能瓶颈,提供了 EnhancedStringHttpMessageConverter 来优化字符串数据 IO 传输性能。
服务端数据返回支持 chunked。
Tomcat 线程池数根据容器配置自适应调整。
满帮集团在完成了以上版本迭代升级之后,服务端各项参数也取得了很棒的优化结果:
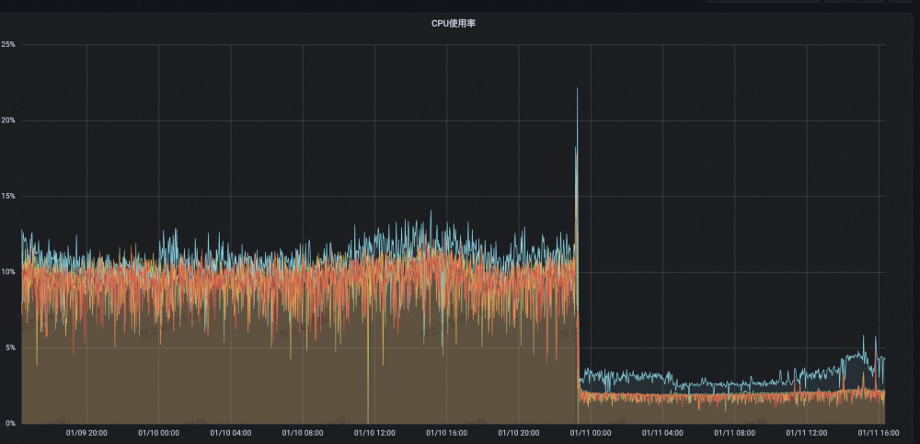
服务端 CPU 利用率从 13% 降到了 2%
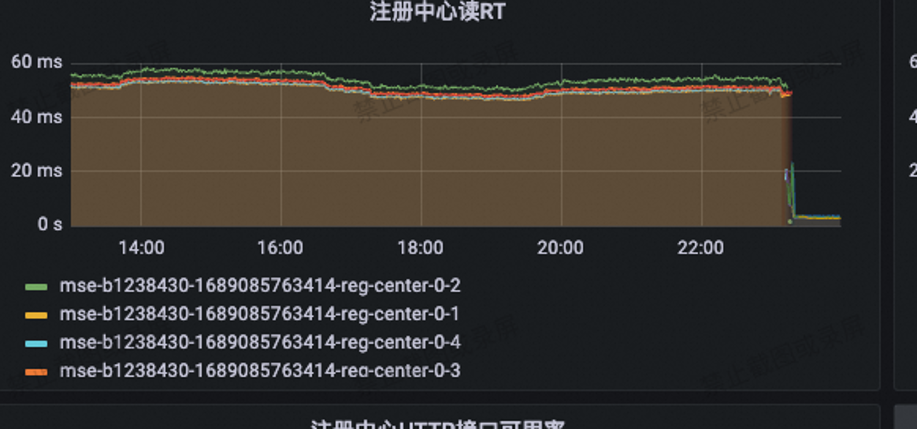
注册中心读 RT 从原先 55ms 降至 3ms 以内
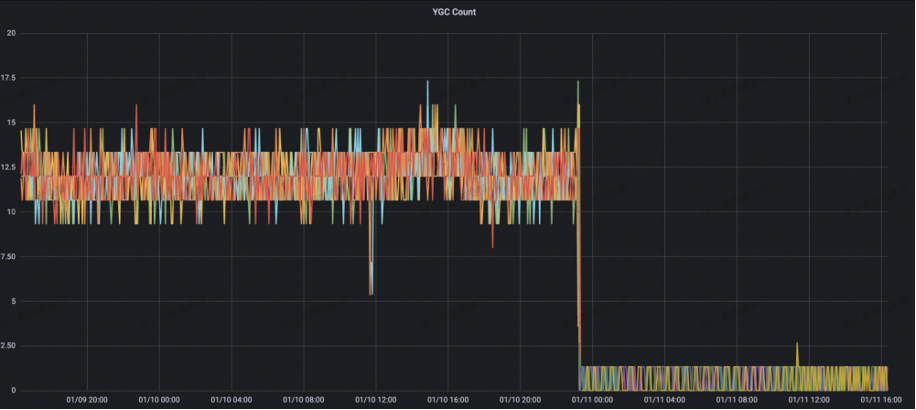
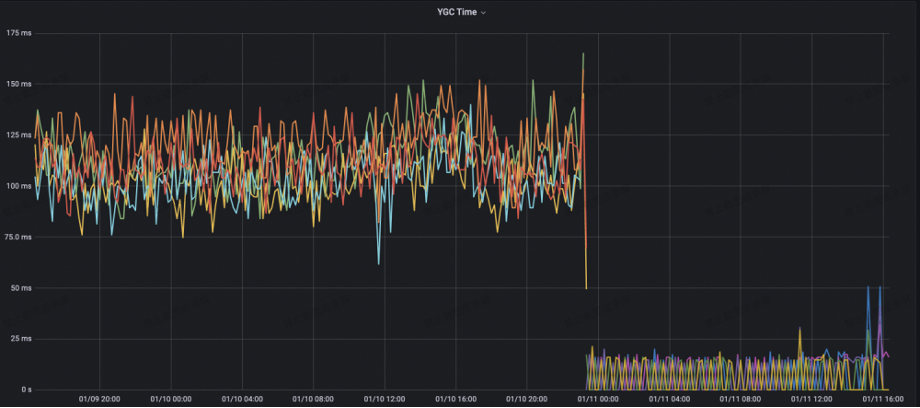
服务端 YGC Count 从原先的 10+ 降至 1
YGC Time 从原先的 125ms 降至 10ms 以内
旁路优化,保障集群高压下的稳定性
满帮同学在迁移到 MSE ZooKeeper 一段时间后,集群又出现了 Full GC,导致集群不稳定,经过 MSE 紧急排查,发现是因为 ZooKeeper 中 Metrics 的一个watch相关的统计指标在计算时对当前节点保存的 watch 数据进行了全量拷贝,在满帮的场景下有非常大的 Watch 规模,metrics 计算拷贝 watch 在这样的场景下产生了大量的内存碎片,导致最终集群无法分配出符合条件的内存资源,最终 Full GC。
为了解决这个问题,MSE ZooKeeper 针对非重要 metrics 采取降级的措施,保障这部分 metrics 不会影响集群稳定性,针对 watch 拷贝的 metrics,采取动态获取的策略,避免数据拷贝计算带来的内存碎片问题。在应用此优化之后,集群 Young GC 时间和次数都明显下降。
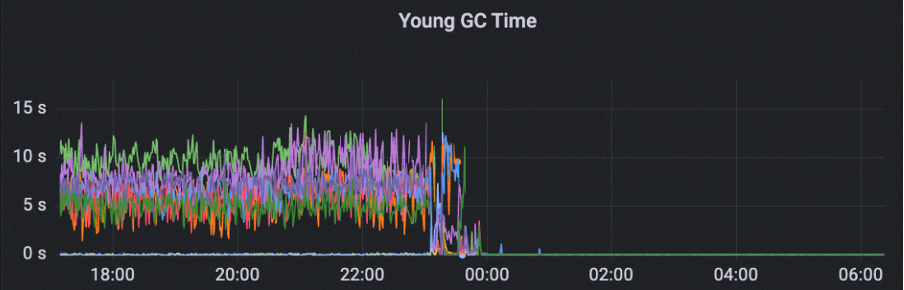
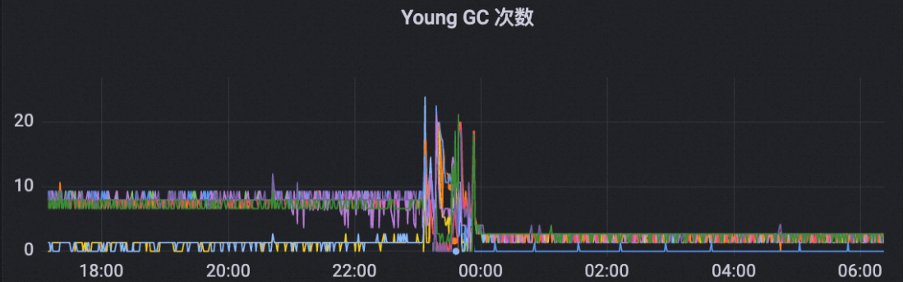
优化之后集群能够平稳承接 200W QPS,GC 稳定
持续参数优化,寻找延时和吞吐量的最佳平衡点
满帮同学将自建 ZooKeeper 迁移到 MSE ZooKeeper 之后,发现应用发布时,客户端读取 ZooKeeper 中数据的延时过大,应用启动读取配置超时,导致应用启动超时,为了解决这个问题,MSE ZooKeeper 针对性进行压测分析,在满帮的场景下,ZooKeeper 在应用发布时需要承接大量请求,请求产生的对象在现有的配置中导致Young GC 频繁。
针对这种场景,MSE 团队经过多轮压测调整集群配置,寻找请求延时和 TPS 最优的交点,在满足延时需求的前提下,探索集群最优性能,在保证请求延时 20ms 的前提下,集群在日常 10w QPS 的水平下,CPU 从 20% 降低到 5%,集群负载显著降低。
后记
Aliware
在数字货运行业竞争激烈和技术快速发展的背景下,满帮集团成功地实现了自身技术架构的升级,从自建的 Eureka 注册中心平滑迁移到了更为高效和稳定的 MSE Nacos 平台。这不仅代表了满帮集团在技术创新和业务扩展上的坚定决心,同时也展现了其对未来发展的深远规划。满帮集团将微服务架构的稳定性和高性能作为其数字化转型的核心,全新的注册中心架构带来的显著性能提高和稳定性增强,为满帮提供了强有力的支撑,使得平台能够更加从容地应对日益增长的业务需求,并且有余力以应对未来可能出现的任何挑战。
值得一提的是,满帮集团在整个迁移过程中的敏捷反应和技术团队的专业执行力也加速了架构升级的步伐。业务平台的成功转型不仅增强了用户对满帮服务的信任,也为其他企业提供了宝贵的经验。在未来,满帮将继续与 MSE 紧密合作,致力于进一步提升技术架构的稳定性、可扩展性和性能,持续为业界树立标杆,推动整个物流行业的数字化转型。
在此次迁移过程中,业务能够平稳无损迁移和性能的大幅提升,证明了 MSE 在服务注册中心领域的卓越性能和可靠性。相信随着 MSE 的不断演进,其对易用性和稳定性的持续追求无疑将为更多企业带来巨大的商业价值,并在企业数字化进程中发挥越来越重要的作用。
此外,MSE 还全面支持微服务治理功能,包括流量防护、全链路灰度发布等。通过在入口网关到后端应用配置完备的限流规则,有效地解决了突发流量带来的系统稳定性风险,保障系统持续稳定运行,企业能够更加专注于核心业务的发展。满帮集团的成功案例为行业树立了新的里程碑,我们怀着期待的目光,期待更多的企业都能在数字化征途上取得更辉煌的成就。
满帮 CTO 王东(东天)寄语:充分了解和利用云的能力,能够让满帮技术团队从底层的持续投入中解脱出来,聚焦更上层的系统稳定性和工程效率,从架构层面实现更高的 ROI。

















 2011
2011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









