







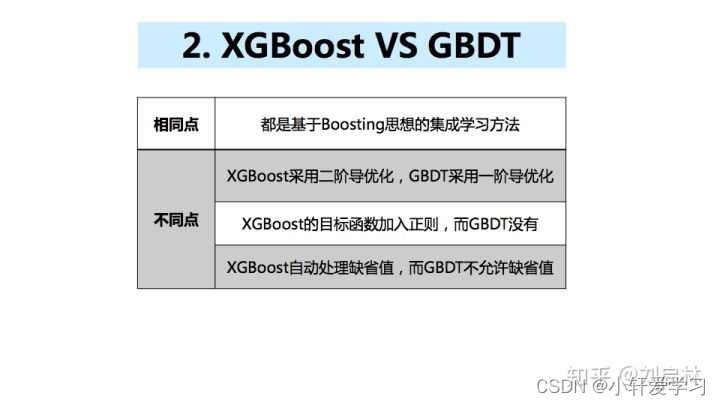
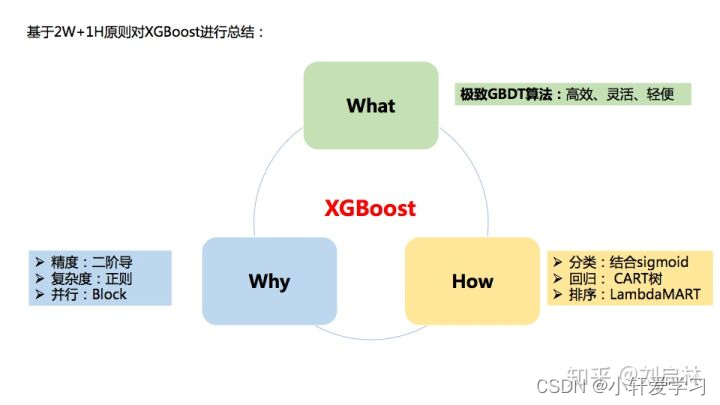
XGBoost(eXtreme Gradient Boosting)极致梯度提升,是一种基于GBDT的算法或者说工程实现。
XGBoost的基本思想和GBDT相同,但是做了一些优化,比如二阶导数使损失函数更精准;正则项避免树过拟合;Block存储可以并行计算等。
XGBoost具有高效、灵活和轻便的特点,在数据挖掘、推荐系统等领域得到广泛的应用。
GBDT
梯度提升决策树(Gradient Boosting Decision Tree,GBDT)是一种基于boosting集成思想的加法模型,训练时采用前向分布算法进行贪婪的学习,每次迭代都学习一棵CART树来拟合之前 t-1 棵树的预测结果与训练样本真实值的残差。
梯度提升决策树算法(GBDT)如下:
第一步:初始化弱学习器
第二步:迭代训练
第三步:得到最终学习器
函数的近似计算
f(x)≈ f(x0)+ f ’ (x0)(x - x0)
适用于:f(x0),f ’ (x0)易求
本质:用x的线性函数f(x0)+ f ’ (x0)(x - x0)来近似表达函数f(x)
泰勒公式
一阶展开式同上
二阶展开式精度更高,误差更小
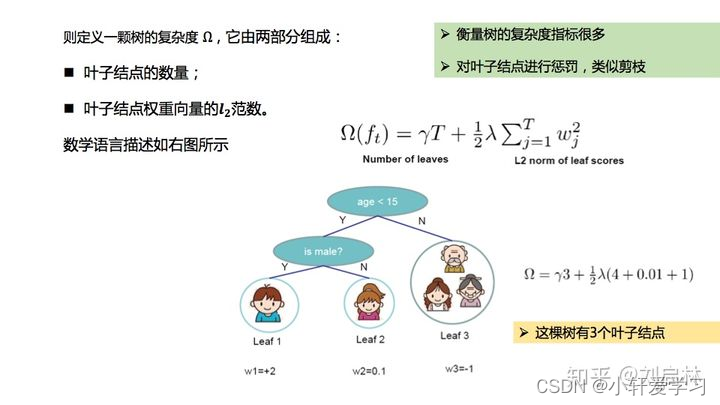
正则
L1正则化:根据权重的绝对值的总和来惩罚权重。
L2正则化:根据权重的平方来惩罚权重。
XGBoost原理
XGBoost(eXtreme Gradient Boosting)极致梯度提升,是基于GBDT的一种算法。
2016年,陈天奇在论文《 XGBoost:A Scalable Tree Boosting System》中正式提出。
XGBoost的基本思想和GBDT相同,但XGBoost进行许多优化:
- 利用二阶泰勒公式展开,优化损失函数,提高计算精确度
- 利用正则项。简化模型,避免过拟合
- 采用Blocks存储结构。可以进行并行计算
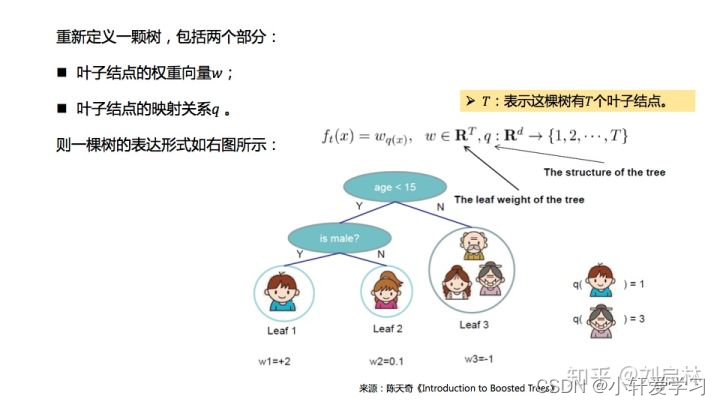
XGBoost目标函数推导
XGBoost的目标函数由损失函数和正则化项两部分组成。

用GBDT梯度提升树表达方式XGBoost。

接下来,三个步骤优化XGBoost目标函数。
第一步:二阶泰勒展开,去除常数项,优化损失函数项;
第二步:正则化项展开,去除常数项,优化正则化项;
第三步:合并一次项系数、二次项系数,得到最终目标函数




XGBoost目标函数解,构建形如一元二次方程形式,求最优值


XGBoost应用
XGBoost库是XGBoost算法的一种实现。
XGBoost是一个优化的分布式梯度提升库,被设计为高效、灵活和轻便。
GitHub:[https://github.com/tqchen/xgboost]
(https://github.com/tqchen/xgboost)
XGBoost一个很重要应用就是进行数据特征挖掘分析
总结
1、XGBoost的优缺点

2、XGBoost VS GBDT

















 653
653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









