







写在前面
上面整理的前向分布算法、adaboost、提升树算法、GBDT&GBRT。
这篇整理XGBoost
约定
假设存在数据集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } D=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\} D={(x1,y1),(x2,y2),...,(xN,yN)},其中, y i ∈ { − 1 , 1 } y_i\in\{-1,1\} yi∈{−1,1}
XGBoost VS GBDT
天奇大佬,分享了PPT和论文,超级棒。
大佬从理论,尤其是工程方面实现了对GBDT的一次极大改进,不仅是预测精度而且训练速度加快很多。
全称:Extreme Gradient boosting
我以为: X Gradient boosting 类似于X战警,哈哈哈哈嗝。
先吹嘘一波天奇大佬,
【文中提到,XGBoost,这个系统的效果已经被大量的机器学习和数据挖掘竞赛所验证。以Kaggle为例,2015年29组优胜方案中17组使用了XGBoost。这其中,8组只是使用了XGBoost去训练模型,其他大部分都是将XGBoost和神经网络做集成。作为对比,第二受欢迎的工具,深度神经网络,有11组采用。在KDDCup 2015中,top-10 每一组都使用了XGBoost。】
1、泰勒二阶展开式:
f
(
x
+
Δ
x
)
=
f
(
x
)
+
f
′
(
x
)
Δ
x
+
1
2
f
′
′
(
x
)
Δ
2
x
f(x+\Delta x)=f(x)+f^\prime(x)\Delta x + \dfrac{1}{2 }f^{\prime\prime}(x) \Delta ^2x
f(x+Δx)=f(x)+f′(x)Δx+21f′′(x)Δ2x
(1)
o
b
j
=
∑
i
=
1
N
L
(
y
i
;
y
i
^
t
−
1
+
f
t
(
x
i
)
)
+
Ω
(
f
t
)
+
c
o
n
s
t
a
n
t
obj = \sum_{i=1}^{N}L(y_i;\hat{y_i}^{t-1}+f_t(x_i))+\Omega(f_t)+constant\tag{1}
obj=i=1∑NL(yi;yi^t−1+ft(xi))+Ω(ft)+constant(1)
将
f
t
(
x
i
)
f_t(x_i)
ft(xi)看作
Δ
x
\Delta x
Δx,对公式(1)展开可得,
o
b
j
=
∑
i
=
1
N
L
(
y
i
;
y
i
^
t
−
1
)
+
g
i
f
t
(
x
i
)
+
h
i
f
t
2
(
x
i
)
+
Ω
(
f
t
)
+
c
o
n
s
t
a
n
t
obj = \sum_{i=1}^{N}L(y_i;\hat{y_i}^{t-1})+g_if_t(x_i)+h_if^2_t(x_i)+\Omega(f_t)+constant
obj=i=1∑NL(yi;yi^t−1)+gift(xi)+hift2(xi)+Ω(ft)+constant
记
g
i
=
∂
y
i
^
t
−
1
L
(
y
i
;
y
i
^
t
−
1
)
g_i =\partial_{\hat{y_i}^{t-1}}L(y_i;\hat{y_i}^{t-1})
gi=∂yi^t−1L(yi;yi^t−1),
h
i
=
∂
y
i
^
t
−
1
2
L
(
y
i
;
y
i
^
t
−
1
)
h_i =\partial _{\hat{y_i}^{t-1}}^2L(y_i;\hat{y_i}^{t-1})
hi=∂yi^t−12L(yi;yi^t−1)。
去掉常量:
(2)
o
b
j
=
∑
i
=
1
N
g
i
f
t
(
x
i
)
+
h
i
f
t
2
(
x
i
)
obj =\sum_{i=1}^{N} g_if_t(x_i)+h_if^2_t(x_i)\tag{2}
obj=i=1∑Ngift(xi)+hift2(xi)(2)
以上,用二阶展开替代之前gbdt的一阶展开(求导)的结果,可以获得更高的精度,收敛更快(不仅加速度最大,而且加速度的增大方向也是最大的。)
2、重新定义树的结构,按叶子加和:
adaboost,gbdt等:
T
(
x
;
θ
m
)
=
∑
i
=
1
N
w
j
I
(
x
i
∈
C
j
)
)
T(x;\theta_m)=\sum_{i=1}^{N}w_jI(x_i\in{C_j}))
T(x;θm)=i=1∑NwjI(xi∈Cj))
xgboost:
定义叶节点的分数(输出值)向量:
w
i
∈
R
T
w_i\in R^T
wi∈RT,
T
T
T是叶节点数量。
将实例映射到叶节点索引的函数:
q
:
R
d
−
>
{
1
,
2
,
.
.
.
,
T
}
q:R^d->\{{1,2,...,T}\}
q:Rd−>{1,2,...,T},
x代表所有样本,
f
t
(
x
)
=
w
q
(
x
)
f_t(x)=w_{q(x)}
ft(x)=wq(x)
3、修改正则项(minor),论文中说是很小的修改,但在实践中效果不错。相比于gbdt增加了一项叶节点的权重和,当然还有其它的定义方式,其中
T
t
T_t
Tt表示某棵树的叶节点数量 ,还记得gbdt怎么更新叶节点的输出吗?选择使得Loss function 最小的输出。
Ω
(
f
t
)
=
γ
T
t
+
λ
1
2
∑
j
=
1
T
w
j
2
\Omega(f_t)= \gamma T_t + \lambda\dfrac{1}{2}\sum_{j=1}^{T}w_j^2
Ω(ft)=γTt+λ21j=1∑Twj2
4、上面说清楚了,天奇大佬定义的损失函数包含哪些内容,那么这里的二阶导数除了收敛更快,精度更高之外,还有更大的目的是为了根据自定义损失函数,实现一个可扩展的损失函数。对于公式(2),
o
b
j
=
∑
i
=
1
N
g
i
f
t
(
x
i
)
+
h
i
f
t
2
(
x
i
)
+
Ω
(
f
t
)
+
c
o
n
s
t
a
n
t
obj = \sum_{i=1}^{N}g_if_t(x_i)+h_if^2_t(x_i)+\Omega(f_t)+constant
obj=i=1∑Ngift(xi)+hift2(xi)+Ω(ft)+constant
定义节点
j
j
j的样本集合:
I
j
=
{
i
∣
q
(
x
i
)
=
j
}
I_j=\{i|q(x_i)=j\}
Ij={i∣q(xi)=j}
o
b
j
=
∑
i
=
1
N
g
i
f
t
(
x
i
)
+
h
i
f
t
2
(
x
i
)
+
γ
T
t
+
λ
1
2
∑
j
=
1
T
w
j
2
+
c
o
n
s
t
a
n
t
obj = \sum_{i=1}^{N}g_if_t(x_i)+h_if^2_t(x_i)+\gamma T_t + \lambda\dfrac{1}{2}\sum_{j=1}^{T}w_j^2+constant
obj=i=1∑Ngift(xi)+hift2(xi)+γTt+λ21j=1∑Twj2+constant
o
b
j
=
∑
i
=
1
N
g
i
w
q
(
x
i
)
+
h
i
w
q
(
x
i
)
2
+
γ
T
t
+
λ
1
2
∑
j
=
1
T
w
j
2
+
c
o
n
s
t
a
n
t
obj = \sum_{i=1}^{N}g_iw_{q(x_i)}+h_iw_{q(x_i)}^2+\gamma T_t + \lambda\dfrac{1}{2}\sum_{j=1}^{T}w_j^2+constant
obj=i=1∑Ngiwq(xi)+hiwq(xi)2+γTt+λ21j=1∑Twj2+constant
o
b
j
=
∑
j
=
1
T
[
(
∑
i
∈
I
j
g
i
)
w
j
+
1
2
(
(
∑
i
∈
I
j
h
i
)
+
λ
)
w
j
]
+
γ
T
t
obj = \sum_{j=1}^{T}[(\sum_{i\in {I_j}}g_i)w_j+\dfrac{1}{2}((\sum_{i\in {I_j}}h_i)+\lambda)w_j]+\gamma T_t
obj=j=1∑T[(i∈Ij∑gi)wj+21((i∈Ij∑hi)+λ)wj]+γTt
假设树的结构固定,即
γ
T
t
\gamma T_t
γTt是常量,记
G
j
=
∑
i
∈
I
j
g
i
G_j=\sum_{i\in {I_j}}g_i
Gj=∑i∈Ijgi,
H
j
=
∑
i
∈
I
j
h
i
H_j=\sum_{i\in {I_j}}h_i
Hj=∑i∈Ijhi
o
b
j
=
∑
j
=
1
T
[
G
j
w
j
+
1
2
(
H
j
+
λ
)
w
j
]
+
γ
T
t
obj = \sum_{j=1}^{T}[G_jw_j+\dfrac{1}{2}(H_j+\lambda)w_j]+\gamma T_t
obj=j=1∑T[Gjwj+21(Hj+λ)wj]+γTt
存在单变量二次函数的两个结论:
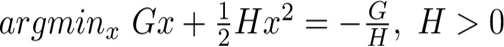
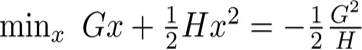
最终,天奇大佬,推出,每个叶子的最优分数和最终的loss函数的分别是,
w
j
∗
=
−
G
j
H
j
+
λ
w_j^*=-\dfrac{G_j}{H_j+\lambda}
wj∗=−Hj+λGj
(3)
o
b
j
=
−
∑
j
=
1
T
G
j
2
H
j
+
λ
+
+
γ
T
j
obj=-\sum_{j=1}^{T}\dfrac{G_j^2}{H_j+\lambda}++\gamma T_j\tag{3}
obj=−j=1∑THj+λGj2++γTj(3)
观察一下公式(3),对于任意损失函数,只要可二阶导,都可以用该公式计算最终的loss。得到了极小值的解析解。实现了可扩展性。而且工程实现中,基模型还可以是线性模型。具体可以看一下这里树的定义,是叶子节点的加权和,和线性模型很相似了。
XGBoost 工程优化
1、Why so fast?
-
树的生成算法
-
exact greedy algorithm,预排序+线性搜索所有特征切分点(CART回归树也是这样做的),预排序用空间换时间。
-
构建直方图:对连续特征做离散化,xgb的工程实现中,给出了两种方式global, local。global在建树之前建proposal,对于所有层保持一致。local,每一次分割后会更新 proposal
2、Sparse aware?
对于missing data 分别计算该样本划分到左右节点的增益,选择较大的增益节点作为划分节点,也可以设定默认划分方向。
feature zero:在分布式系统上的实现中,用直方图做分桶。
类别特征:one-hot
3、预排序时间太长,或者data无法完全放进内存。
- exact greedy algorithm: sort all data in one block
- approximate algorithm: save into several blocks. 每个block 与data中的列的子集(仅部分特征)相关。
4、对于工程上的优化,还需要仔细读API,和论文以及源码才能弄清楚,用的话还是api比较重要。
小问题
1、为什么展开用二阶导?(为什么不用三阶导呢)?
我的理解:
二阶导相比于一阶导来说,精度更高,同时会加快模型训练速度。
此外,天奇大佬根据二阶导的loss function,推导了一个叶子节点和loss function的一般解,而只用到了上一次迭代输出模型的梯度信息。
斗胆猜测一下,不用三阶导可能因为:二阶导足够用了,三阶导增加计算量的花费>对精度的提高。
2、xgb的直方图和LGB的直方图有什么区别呢?
下一篇















 422
422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









