






我一直认为,查询优化器(Query Optimizer,后面简称优化器)一直是数据库领域 Top 级别的 hardcore 技术,自己也一直尝试去深入理解,但每每看到 TiDB 代码里面那一大坨 plan 的代码,我就望而生畏了,就像是『可远观而不可亵玩焉』。但虽然很难理解,还是能通过方式去理解优化器的,一个最直观的做法就是生成不同的 Query 去验证优化器的效果,实际在 PingCAP 内部,我们也是通过 Fuzz, A/B testing 等技术,来验证优化器是否出现性能问题这些。
但无论怎样,优化器的验证和测试工作是一件非常难的事情,毕竟对于一条 Query,数据库可能会生成非常多的查询计划(plan),我们当然可以通过穷举的方式找到最优的一条 plan,但实际中,我们只能在有限的时间内找到一个比较优的 plan。那么我们如何能确定优化器找到的是一条比较好的 plan 呢?自然需要有一些评价标准,最近看了几篇 Paper,刚好在这个上面做了研究,也对我们后续测试的改良提供了一些方向吧。
OptMark: A Toolkit for Benchmarking Query Optimizers
首先是 OptMark: A Toolkit for Benchmarking Query Optimizers 这篇 Paper,里面提到了验证优化器的两个指标 - Effectiveness 和 Efficiency。对于 Effectiveness 来说,它主要是衡量优化器对于某条 Query 生成的 plan 的质量,而 Efficiency 则是衡量生成的 plan 的资源消耗。
Effectiveness 主要有两个指标,一个是 Performance Factor,一个则是 Optimality Frequency,Performance Factor 计算公式如下:
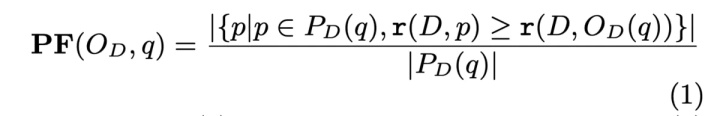
对于任何 query q 以及优化器 Od 来说,PF 衡量的是在搜索空间里面的 plans,比优化器选择的 plan 要差的比例。Od(q) 是优化器对于 q 生成的 plan,Pd(q) 则是所有可能被执行的 plan,r(D, p) 则是 plan p 执行的时间,而 r(D, Od(q)) 则是优化器选择的 plan 执行的时间。有了 PF,我们就能得到 Optimality Frequency,如果 PF = 1,就表明优化器找到了一条相对不错的 plan。
当然,实际中我们很难将搜索空间全部遍历出来,所以通常我们都只是会找足够多的 plan,Paper 里面提到了 Sample Size 的概念,也就是会有一个信心指数的计算,直白的说,就是如果我们需要有 x% 的信心,以及 y% 的精确度来计算 PF,那么就需要生成 n 个 plans 这种,具体的计算方法可以参考论文 2.1.2 章节。
要验证 Effectiveness,论文使用了如下方式:
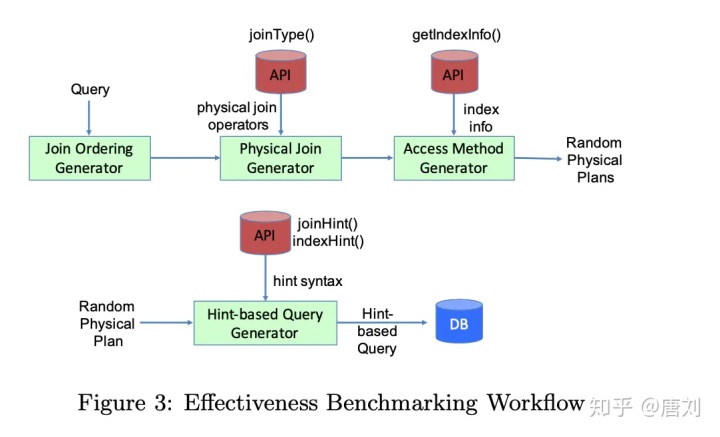
- 对于一条 Query,对里面的 Join 随机进行重新排序
- 对于 join 的两个 table,如果没有指定 join 方式,则使用 cross join,否则则随机从
joinType()里面选择一个 physical join,譬如 hash,index merge 等。 - 对任何 table,随机选择一种扫描方式,譬如使用某个 index,或者全表扫
- 生成一条 plan,去执行。然后重复执行上述操作,直到满足我们之前说的信心指数。
对于 Efficiency 来说,论文并没有用传统的衡量执行时间的方式,而是选用了 4 个指标:
#LP- 枚举的 logical plan个数#JO- 枚举的 join 顺序个数#PP- 总的有开销的 physical plan 的个数#PJ- 总的有开销的 physical join plan 的个数
论文里面将这些指标直接加到了 MySQL 和 PG 的代码里面进行统计,这个也就是开源的好处了,能直接改代码,后面也可以试试 TiDB。
总的来说,OptMark 这篇 Paper 从 Effectiveness 和 Efficiency 两个维度来告诉我们如何测试一个数据库的查询计划,而且也比较容易实施。不过,在测试 Effectiveness 生成 plan 的时候,其实我有点怀疑数据库到底会不会按照这条 plan 去执行。
Counting, Enumerating, and Sampling of Execution Plans in a Cost-Based Query Optimizer
在前面那篇 Paper 里面,OptMark 使用的是一种 random join ordering 的方式来对一条 query 进行 join 的顺序变换,然后对 join 的 table 选择不同的 join 算法,以及对每个 table 使用不同的查询方式,那么有没有其他的办法来对一条 Query 生成执行计划,并且让数据库执行呢?
然后刚好看到了一篇不错的 Paper, Counting, Enumerating, and Sampling of Execution Plans in a Cost-Based Query Optimizer ,其中提到了一个很不错的方式,就是通过 MEMO 这种数据结构,来建立好数字和 plan 的对应关系,我们只要给出一个数字,就能执行对应的 plan。
首先,对于一条 Query,我们可以有一个非常简单的 plan,并且用这个 plan 来生成 MEMO 结构
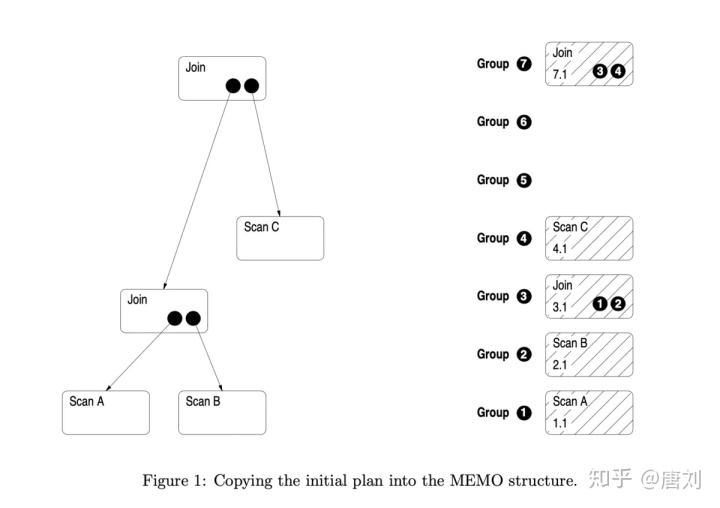
当生成 MEMO 之后,我们就可以对 logical operators 进行变换,一个转换规则可以是:
- 在同一个 group 里面的 logical operator,譬如
join(A, B) -> join(B, A) - 在同一个 group 里面的 physical operator,譬如
join -> hash join - 一组能连接多个 sub plan 的 logical operators,譬如
join(A, join(B, C)) -> join(join(A, B), C)
然后做完转换之后,MEMO 表现就更丰富了,如下:
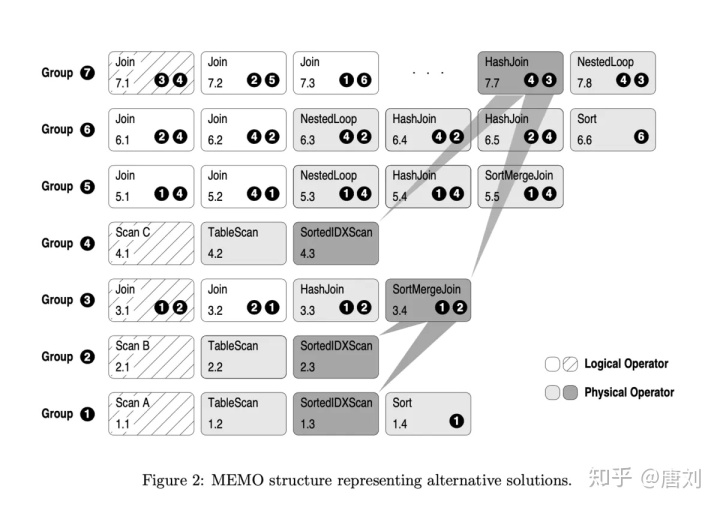
最后一项预备工作,就是抽出所有的 physical operators,并且具现化这个 operators 和它们的可能 children 的连接,如下:
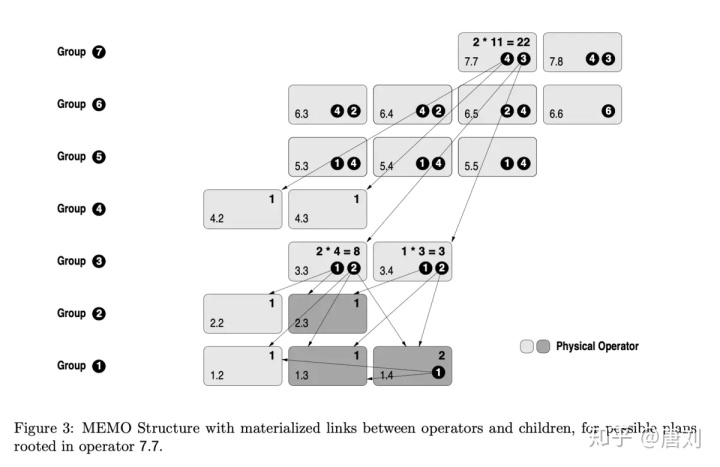
当做完了如上三个步骤,就可以通过 MEMO 这个数据结构算出来总的 Query Plans,算法可以直接看 Paper 3.2 章节,其实就是自下而上遍历每个可能 plan 的个数并且汇总。当我们得到了总的 plan 个数,就可以通过 unranking 算法知道某个 position 上面对应的 plan,具体的 unranking 算法可以参考 3.2。当构造了这些信息之后,我们就可以在 query 里面直接指定使用某个 plan 了,如下:

其实这个方式非常的巧妙,现在 TiDB 是不支持的,没准可以试试支持下,应该也不困难。
Testing the Accuracy of Query Optimizers
除了上面两篇 Paper,还看了一篇,Testing the Accuracy of Query Optimizers,讲的是如何测试优化器的精确度,其实就是一个 estimate time 和实际 execution time 的 pair 对比吧,会计算一个相关性 score,类似如下:
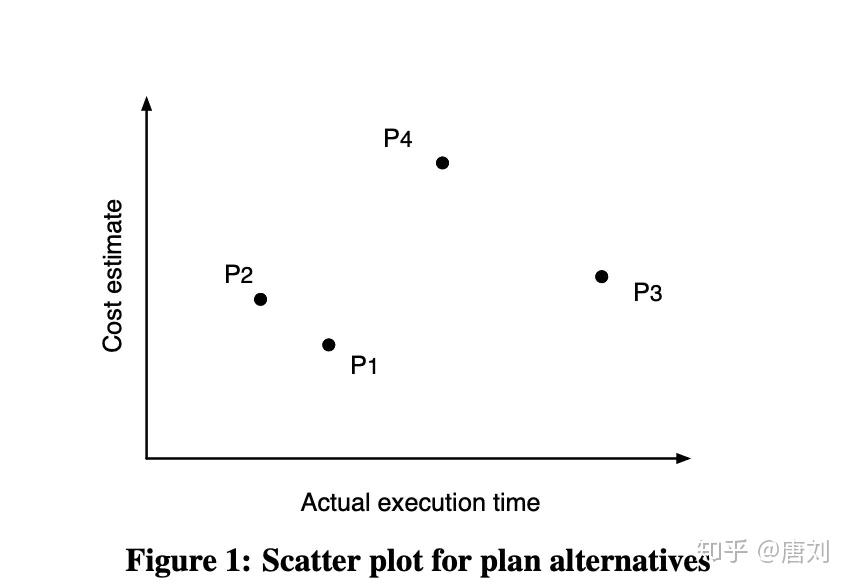
可以看到,上面 4 个 plan,P1 和 P2 其实明显会比 P3 和 P4 要好。
然后 Paper 的作者做了一个 TAQO 系统,如下:
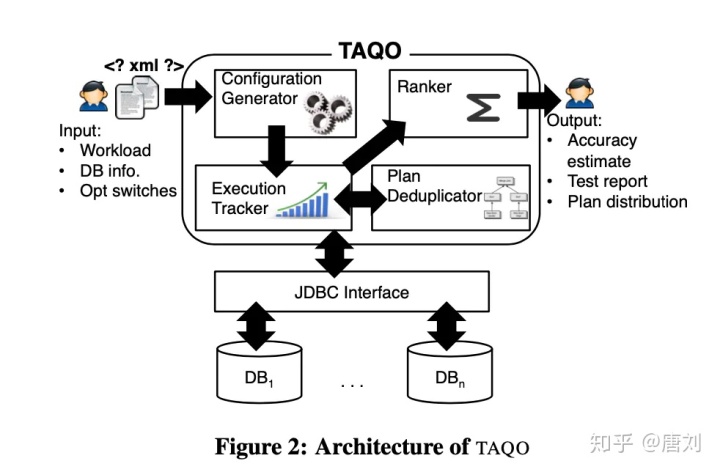
流程比较通俗易懂,不多做解释了,反正可以结合上面第一篇 paper,来验证优化器的效果吧。
总结
上面列了几篇,我们当然是想应用到 TiDB 来验证优化器的效果的,当然另外,我们也可以通过让优化器强制使用不用的 plan,来看优化器会不会有 bug,譬如对于第二篇 paper,没准我们使用 plan 8 得到的值跟 plan 9 不一样,这事情就有意思了。
总的来说,优化器这个方向是一个非常 hardcore 的东西,不光是测试上面,还包括如何实现一个高效的优化器上面,我们需要非常多的技术储备,如果你对这方面感兴趣,欢迎联系我 tl@pingcap.com。















 7993
7993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









