








#文章首发于公众号“如风起”。
原文链接:
小白学统计|面板数据分析与Stata应用笔记(二)mp.weixin.qq.com
面板数据分析与Stata应用笔记整理自慕课上浙江大学方红生教授的面板数据分析与Stata应用课程,笔记中部分图片来自课程截图。
笔记内容还参考了陈强教授的《高级计量经济学及Stata应用(第二版)》
短面板数据分析的基本程序
1、模型设定与数据
2、描述性统计与作图
3、模型选择
4、报告计量结果
#以啤酒税将降低交通死亡率的假说为例,数据来自陈强教授的《高级计量经济学及Stata应用(第二版)》中的“traffic.dta”数据集。
第一步 模型设定与数据
为了检验假说,构造一个双向固定效应模型
其中,被解释变量
在Stata软件中对数据进行分析,执行如下步骤:
1、导入数据到Stata中
在Stata的“命令窗口”中输入
命令【use"数据集路径traffic.dta"】将“traffic.dta”数据集导入到Stata中,
例如【use"C:Userstraffic.dta"】。
将数据导入Stata后,即可在Stata的“变量窗口”中看到“traffic”数据集中的各个变量的名称及其标签。
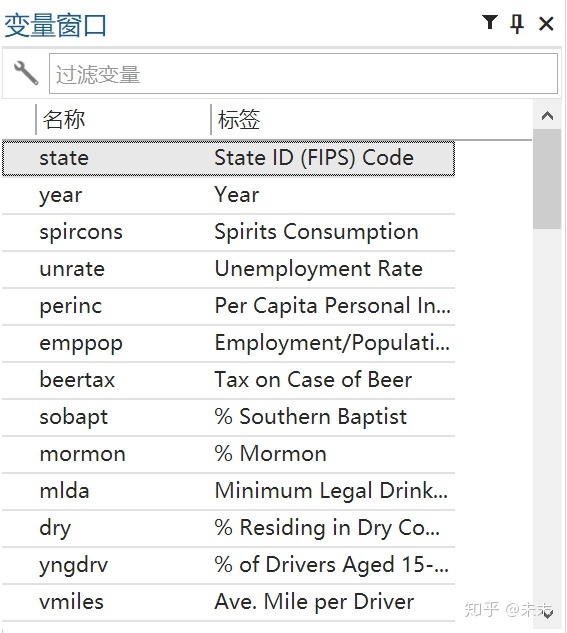
2、查看数据
在Stata的“命令窗口”输入命令【des】查看“traffic”数据集。
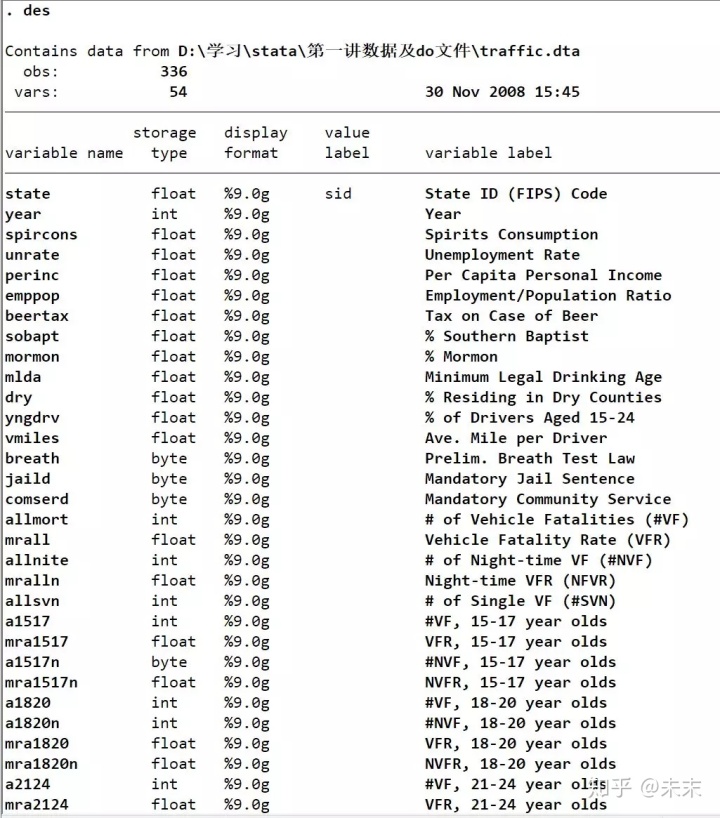
从输出结果我们可以看到:“traffic”数据集包含336个观测值,54个变量。此外,我们还可以看到数据集中的变量名称、数据类型以及相关的说明。
通过命令【xtdes】我们可以查看面板数据的特征。
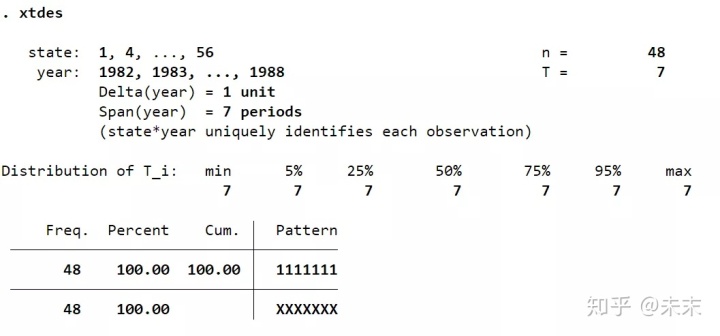
由结果可知:面板数据的截面数 ,时间数 , ,说明这是一个短面板数据集。
在使用面板数据分析前,我们需要输入命令【xtset state year】,来告诉Stata软件,这是一个以截面变量state为州,时间变量为year的面板数据。
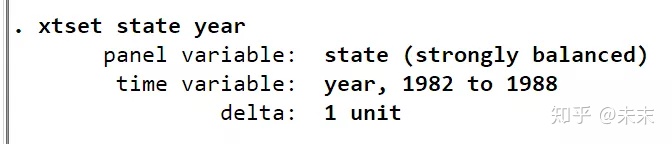
观察输出结果,由strongly balance可知,这是一个平衡面板数据。
至此,我们可以知道,“traffic”数据集是一个48个州,1982-1988年的平衡面板数据集。
第二步 描述性统计作图
1、描述性统计
使用命令【sum 关键变量】可以得到关键变量的描述性统计表。
在Stata中输入命令【sum fatal beertax spircons unrate perinck】,我们可以得到解释变量与被解释变量的观测值、均值、标准差、最小值和最大值。

2、绘制散点图及回归直线在回归之前,我们可以先画出核心变量与别解释变量的散点图及回归直线,来预先判定一下核心变量与被解
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5896
5896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









