






XGBoost: A Scalable Tree Boosting System
链接:https://www.kdd.org/kdd2016/papers/files/rfp0697-chenAemb.pdf
内容
- Introduction
- Tree boosting & Regularized objective & Gradient tree boosting & Shrinkage and Column Subsampling
- Split finding method(树结点分裂方法)
- XGBoost 与GBDT区别
1. Introduction
一作是大佬陈天齐。论文中介绍这个算法的效果已经被大量的机器学习和数据挖掘竞赛所验证。在Kaggle比赛中,2015年29组优胜方案中17组使用了XGBoost。同一年,在KDDCup 2015中,top-10 的每一组都使用了XGBoost。据说面试中也经常有这种问题,所以一定要或多或少掌握这个算法才可以。
它在很多问题上都得到了很好的结果:商店销售预测,高能物理事件分类,网站文本分类,顾客行为预测,动作检测,广告点击通过率预测等等。
2. Tree Boosting
2.1 Tree boosting & regularized objective
先简单介绍一下加法模型的tree boosing。如图,
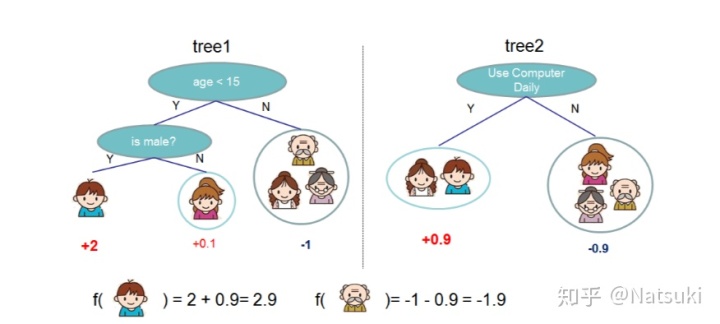
对于同一个数据,两个不同的树预测出不同的结果,然后把结果相加,就得到最后的预测结果。所以对于最后预测结果,可以写成下面的公式。
K: 树的个数。
目标函数就可以写成下面的形式,其中
2.2 Gradient Tree Boosting
根据前向分布算法,在t步的时候,给定前t-1棵回归树的情况下,第t步的目标函数可以表示为
根据泰勒展开,得到
where
移除常数项
当我们定义
根据一元二次方程的性质,此时,我们可以计算出极值,当
2.3 Shrinkage & Column Subsampling
和随即森林很像,它在使用过程中进行列抽样(特征抽样),防止过拟合,也加快训练和速测。Shrinkage是使用了一个
3. Split Finding Method(树结点分裂方法)
3.1 Exact Greedy Algorithm (精确贪心算法)
遍历所有的可能分裂点,计算出Gain 值,然后选择最大的去切分。算法如下图所示,

虽然这个方法很有效,但是由于要遍历所有可能的点,所以时间复杂度会很高,同时不是很有效率如果不把数据都放进内存,因此,他们使用了近似的方法来实现切分。
3.2 Approximate Algorithm(近似算法)
伪代码如图,

大概是把数据的feature k 根据百分比顺序选择候选点,然后根据候选点把数据分段,计算 g 和 h 值。文中提到,选择候选点的方式有global 和local 两种方式。global 的方法是,一开始就决定好了,每次都是在同样的候选中挑选。但是local方法是,在每次切分后,重新在候选中挑选。因为global一开始就决定好了,所以这种方式需要更多的候选点,而 local在比较深的树上有很好的表现。
下面是这两种方法和精确贪心算法的表现比较。
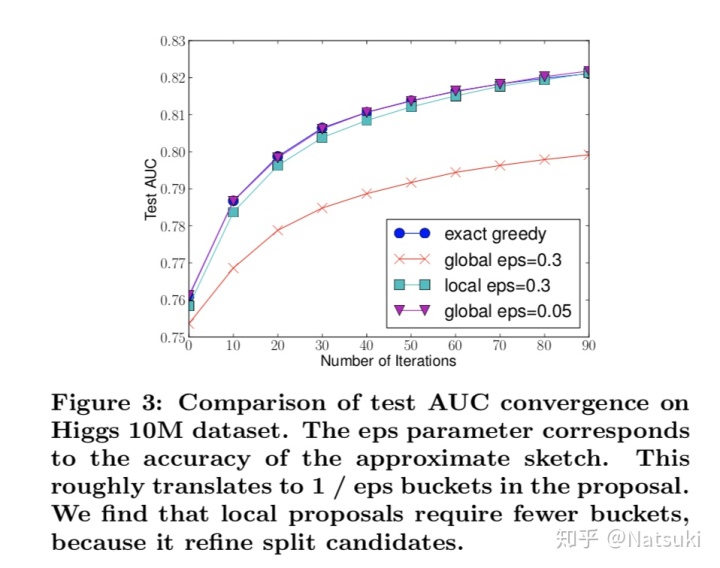
从上图我们可以看到:
- 全局切分的候选点足够多的时候,和精确贪心算法表现相近。(gloabl eps=0.05)
- 局部切分的候选点不需要那么多,表现比精确贪心算法差一点,但不是很多。(local exp=0.3)
本论文中介绍了一个叫 Weighted Quantile Sketch的方法来选择候选点,它是利用二阶梯度h权重的算法。
第k个特征小于z的样本比例。候选切分点为
上式表示,相邻两个候选点不超过阈值。
3.4 稀疏值处理(sparsity-aware split finding)
常用的数据集可能因为各种原因都是稀疏的,比如:1)数据缺失;2)频率较高地出现0; 3)可能是one-hot编码等。
XGBoost算法会处理缺失值。

4. XGBoost 与GBDT区别
传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
参考链接:
- Chen, Tianqi, and Carlos Guestrin. “Xgboost: A scalable tree boosting system. Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. ACM, 2016.
- 『我爱机器学习』集成学习(三)XGBoost
- https://github.com/Freemanzxp/GBDT_Simple_Tutorial















 29万+
29万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









