







 本文探讨DenseNet网络结构在训练过程中内存消耗过大的问题,提出通过预分配缓存和MFM方法优化内存使用效率,有效降低内存需求,同时保持良好的性能。
本文探讨DenseNet网络结构在训练过程中内存消耗过大的问题,提出通过预分配缓存和MFM方法优化内存使用效率,有效降低内存需求,同时保持良好的性能。
改进
Densenet是一个非常棒的网络结构,但是特别耗费显卡。
然后作者给出了解决方法
黄高博士及刘壮取得联系两位作者对 DenseNet 的详细介绍及常见疑问解答
DenseNet 特别耗费显存?
不少人跟我们反映过 DenseNet 在训练时对内存消耗非常厉害。这个问题其实是算法实现不优带来的。当前的深度学习框架对 DenseNet 的密集连接没有很好的支持,我们只能借助于反复的拼接(Concatenation)操作,将之前层的输出与当前层的输出拼接在一起,然后传给下一层。对于大多数框架(如 Torch 和 TensorFlow),每次拼接操作都会开辟新的内存来保存拼接后的特征。这样就导致一个 L 层的网络,要消耗相当于 L(L+1)/2 层网络的内存(第 l 层的输出在内存里被存了 (L-l+1) 份)。
解决这个问题的思路其实并不难,我们只需要预先分配一块缓存,供网络中所有的拼接层(Concatenation Layer)共享使用,这样 DenseNet 对内存的消耗便从平方级别降到了线性级别。在梯度反传过程中,我们再把相应卷积层的输出复制到该缓存,就可以重构每一层的输入特征,进而计算梯度。当然网络中由于 Batch Normalization 层的存在,实现起来还有一些需要注意的细节。为此我们专门写了一个技术报告(Memory-Efficient Implementation of DenseNets, https://arxiv.org/pdf/1707.06990.pdf)介绍如何提升 DenseNet 对内存的使用效率,同时还提供了 Torch, PyTorch, MxNet 以及 Caffe 的实现,代码参见:
Torch implementation: https://github.com/liuzhuang13/DenseNet/tree/master/models
PyTorch implementation: https://github.com/gpleiss/efficient_densenet_pytorch
MxNet implementation: https://github.com/taineleau/efficient_densenet_mxnet
Caffe implementation: https://github.com/Tongcheng/DN_CaffeScript
我平时用tensorflow,我对其中这种功能并不了解有没有这个功能(知道的小伙伴可以留言喷我下)。然后我想起了另一个人脸识别的论文中的降channel的方法--MFM,我对densenet的中间层和后面一层用了MFM处理(5层)。来达到降低channel的目的,这样也就降低了拼接占用资源大的问题。
什么是MFM呢?你看我的代码很好理解,MFM代码。就是对feature map间的maxpool处理。
为什么选择中间和最后一层处理MFM,前面层提取特征并不明显,用maxpool会损失一些信息。中间层的特征提取的比较突出了,丢失信息不会太对。这里说下,并没有对前面层提出的feature map进行MFM,而是我画的红圈处(直线上的,不是前面跳跃过来的)。
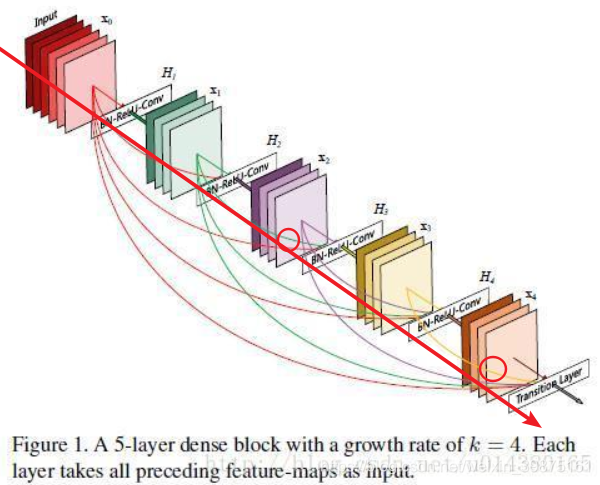
目前在小的训练集(cifar10)上表现还不错。性能/计算量上得到了明显的提升。
后记
这种方法还有待改进,或者尝试前面跳跃过来的feature map,他们哪些也可以MFM处理。但是因为设备(1070小笔记本),电费问题,我目前做不到挨个测试。
我认为,训练集足够,训练次数够多,这个方法会很不错。
--------
对mfm的改进。运用了通道剪枝的理论来实现,效果相当不错,在cirf10数据上,acc降低不太多。


















 83
83

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











