





杀鸡要用牛刀
沛哥最近出差比较忙,积累了很多聊天记录没有处理,一下子处理这么多聊天记录,不是沛哥这种懒人的风格。于是乎开始继续雕琢沛哥的工具。

第一步,通过多选→邮件发送到印象笔记专属邮箱→批量保存的操作,我们已经get到了。
第二步,要对文本内容进行加工汇总。通过印象笔记保存之后,复制内容到Word中。我们观察一下,大部分内容是井底望天作为发言人产生的。因此很多内容是连续在一起的。需要把连续发言的部分,去掉昵称合并成为一个发言人。也就是把多个分散的段落整合为一个发言段落。减少中间的冗余字符串,提升阅读效率。
识别文本特征

祭上神器:正则表达式
首先识别文本特征,对应的处理方式,首先识别发言人昵称:井底望天+空格+小时+分钟,对应的替换逻辑为 井底望天 ([0-9]{2}):([0-9]{2}) 替换内容为空。
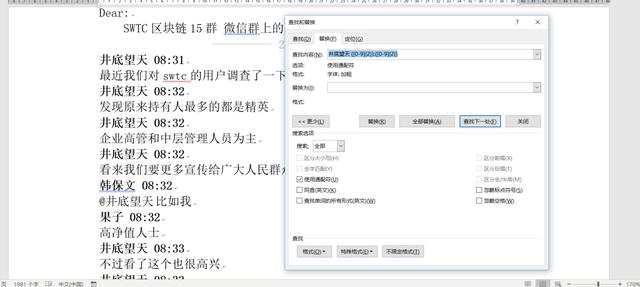
替换后的效果如下
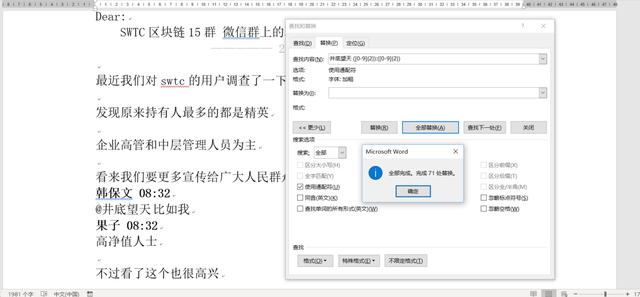
可以看到替换后有很多空行出现。原因是替换的内容中,没有换行符。 我们加入一下换行符试一试,看看能不能直接把文本和多余的换行符一起替换掉,第一次,先不勾选使用通配符
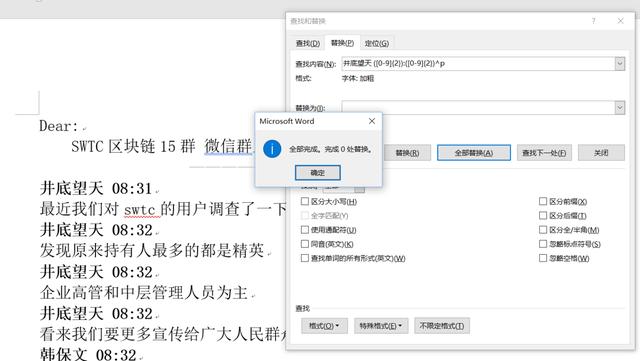
勾选使用通配符,word提示,这个换行符在通配符中无法查找。
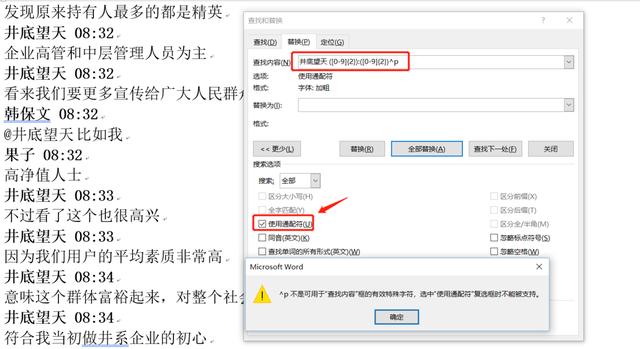
退而求其次, 而且为了后面的处理考虑,经过测试,把这部分井底望天 ([0-9]{2}):([0-9]{2}) 内容替换为$,也就是美元符号$
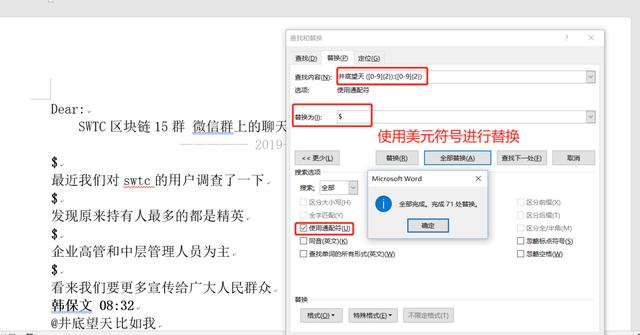
然后开始录制下一段宏。
第二段批处理
替换完之后,我们还需要在把首行的$替换为发言人昵称:井底望天:并且进行加粗 然后中间的美元符号,换行符替换。我们识别一下规律,调整为两个换行符中间一个美元符号$。 这个宏就录到这里,因为中间需要一些手动处理的段落。 然后把每一个环节的$美元符号前面的换行符删除掉,这样^p$^p替换命令在替换的时候就无法匹配前面的换行符^p,而留下美元符号$。留下的美元符号,是作为段首的标记留作后面的处理。 这样只需要在每个段首的美元符号手动做一个删除换行符的操作即可,留下美元符号$。
第一步:把^p$^p替换为$,
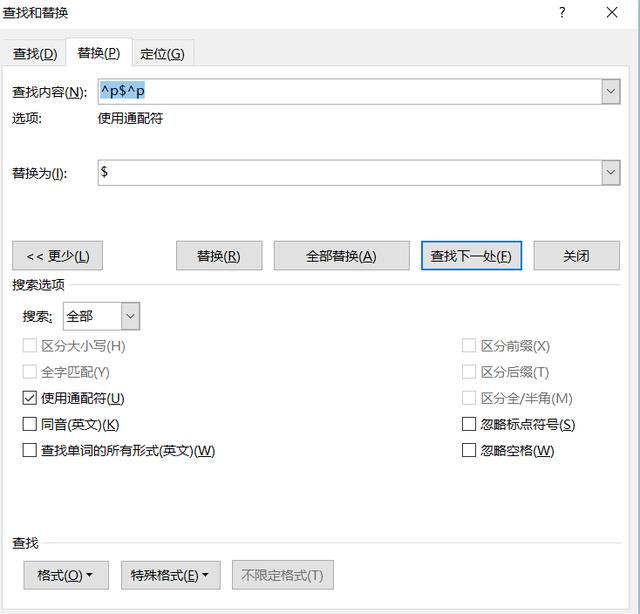
替换完之后的效果
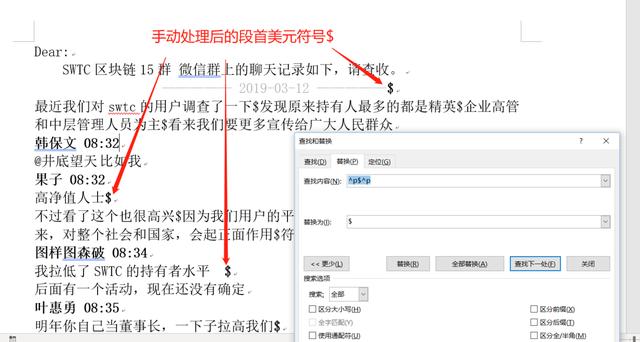
第二步:把手动处理后的段首美元符号$,替换为发言人昵称:井底望天:替换的时候需要在昵称前面加两个换行符。另外需要按下ctrl+B对替换后的昵称逆行加粗处理。
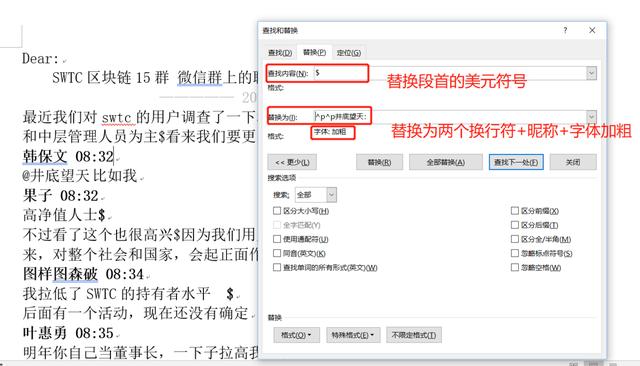
井底望天作为发言人的部分处理完了。还有其他群友发言的部分,需要在昵称前面加换行符处理。需要在文本中每个昵称的前面加一个换行符,单独起一行。

我们识别一下这个部分的特征,一个加粗的昵称,空格,小时,分钟这种结构。正则表达式的写法 () ([0-9]{2}):([0-9]{2})替换为^p12:3 观察文本结构的特征,每个昵称后面都有一个时间格式,时间格式通过([0-9]{2}):([0-9]{2})来进行匹配,很容易做到。 但是前面的昵称有的有汉字,有的有英文,而且长度不等,还有汉字英文的混杂。沛哥尝试过用汉字进行匹配,用汉字加英文的表达式进行匹配。[一-龥_a-zA-Z0-9]效果都不尽如人意。 看了很多资料,最后想到,不区分汉字还是英文,看作一个字符串,做模糊识别。于是用()匹配,效果非常赞。 注意后面要有空格。 替换对象说明 首先是()和([0-9]{2})和([0-9]{2}),三个括号,分别代表三个字符组。而1和2和3分别对应这三个字符组。我们的需求是在字符组的整体前面加上一个换行。换行通过^p作为换行符来实现。 至于2和3之间的分号“:”不在括号内,需要保留处理,08:34处理后会得到0834这样的结果,就失去了一个完整的时间格式。 下午测试的过程中,又出现了一些问题,沛哥调整了一下正则表达式的写法,降低了一下复杂度。把多个表达式合并在一起了。具体的就是去掉中间的括号( [0-9]{2}:[0-9]{2}) 如果直接替换,会得到的效果如下。并不是我们想要的结果,本意是想在昵称前面加换行符,结果匹配的内容很多并不是。
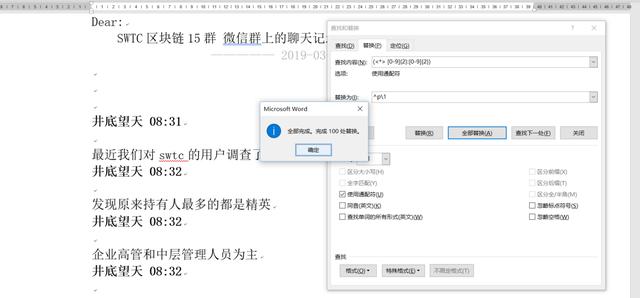
我们来看一下匹配过程。
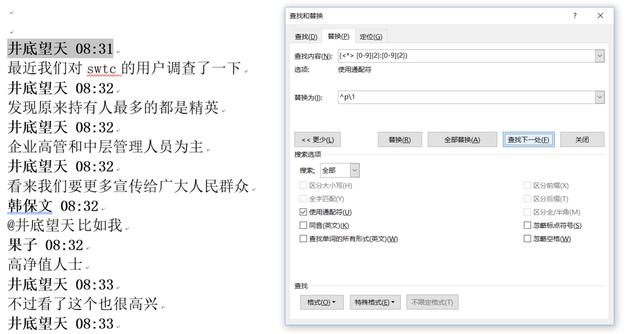
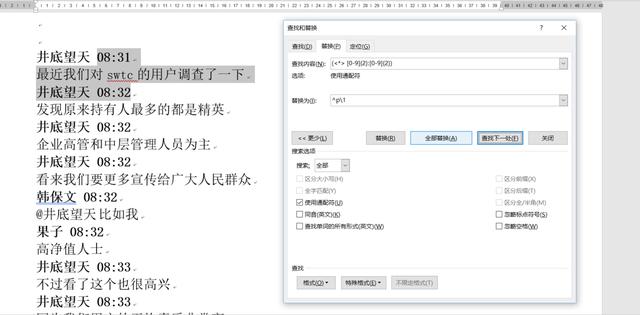
因为好用,但是也容易产生错误匹配,因此需要一些限制。
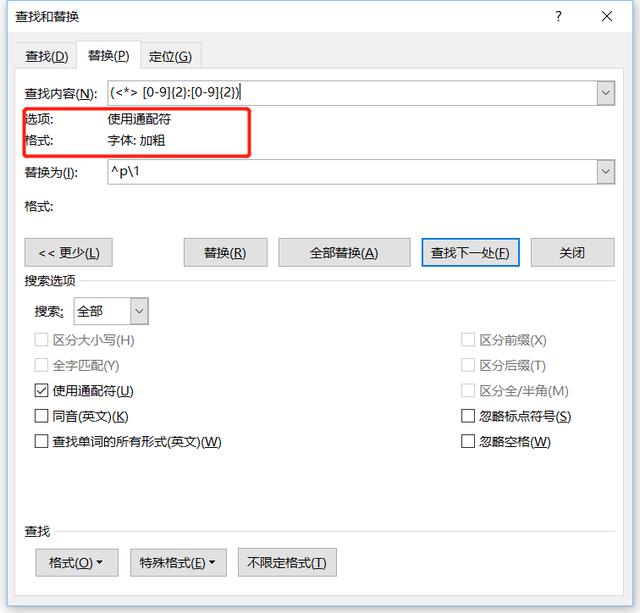
我们观察到所有的昵称都是加粗的。鼠标光标放到查找内容这里,按下Crl+B,对匹配格式做了限制 再次点击全部替换,得到的结果就是我们想要的结果了。只匹配加粗的文本。防止对其他文本的错误匹配。
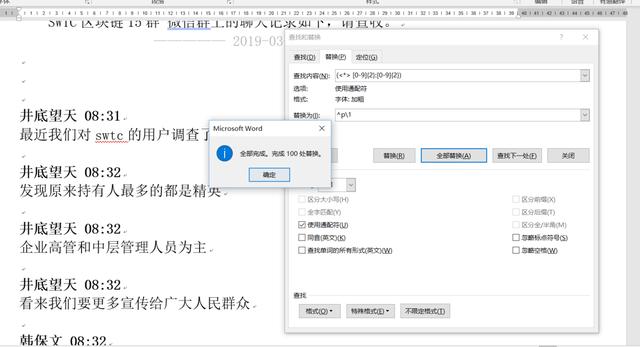

两次宏处理后的效果
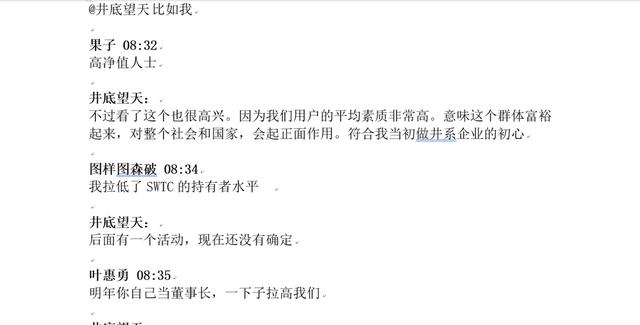
两次宏处理后德效果
简化后的正则表达式只适合处理在这个字符组的开头或者结尾做批量处理,无法在字符的中间做处理,如果需要在中间做处理的话,还是分解成多个串联的字符组比较好处理。 事实证明,对于文本特征的了解和分析是多么重要。 貌似掌握一个技能和灵活应用,get到其中的精髓,没有捷径,通过笨办法反反复复的练习,尝试。 杀鸡要用牛刀,而牛刀需要反反复复的打磨。 通过具体的任务驱动,沛哥对于正则表达式的掌握又精进了一个层次。
最后附上完整的宏处理的代码
Sub 井底望天聊天记录整理第一段()
'
' 聊天记录整理 宏
'
'
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = "Dear:^p"
.Replacement.Text = ""
.Forward = True
.Wrap = wdFindContinue
.Format = False
.MatchCase = False
.MatchWholeWord = False
.MatchByte = False
.MatchWildcards = False
.MatchSoundsLike = False
.MatchAllWordForms = False
End With
Selection.Find.Execute Replace:=wdReplaceAll
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = "SWTC区块链15群 微信群上的聊天记录如下,请查收。"
.Replacement.Text = "整理自【SWTC区块链15群 微信群上的聊天记录】"
.Forward = True
.Wrap = wdFindContinue
.Format = False
.MatchCase = False
.MatchWholeWord = False
.MatchByte = False
.MatchWildcards = False
.MatchSoundsLike = False
.MatchAllWordForms = False
End With
Selection.Find.Execute Replace:=wdReplaceAll
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = "SWTC区块链15群 微信群上的聊天记录如下,请查收。"
.Replacement.Text = "整理自【SWTC区块链15群 微信群上的聊天记录】"
.Forward = True
.Wrap = wdFindContinue
.Format = False
.MatchCase = False
.MatchWholeWord = False
.MatchByte = False
.MatchWildcards = False
.MatchSoundsLike = False
.MatchAllWordForms = False
End With
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = "井底望天 ([0-9]{2}):([0-9]{2})"
.Replacement.Text = "$"
.Forward = True
.Wrap = wdFindContinue
.Format = False
.MatchCase = False
.MatchWholeWord = False
.MatchByte = False
.MatchAllWordForms = False
.MatchSoundsLike = False
.MatchWildcards = True
End With
Selection.Find.Execute Replace:=wdReplaceAll
End Sub
Sub 井底望天聊天记录整理第二段()
'
' 聊天记录整理2 宏
'
'
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = "^p$^p"
.Replacement.Text = "。"
.Forward = True
.Wrap = wdFindContinue
.Format = False
.MatchCase = False
.MatchWholeWord = False
.MatchByte = False
.MatchWildcards = False
.MatchSoundsLike = False
.MatchAllWordForms = False
End With
Selection.Find.Execute Replace:=wdReplaceAll
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
Selection.Find.Replacement.Font.Bold = True
With Selection.Find
.Text = "$"
.Replacement.Text = "^p^p井底望天:"
.Forward = True
.Wrap = wdFindContinue
.Format = True
.MatchCase = False
.MatchWholeWord = False
.MatchByte = False
.MatchWildcards = False
.MatchSoundsLike = False
.MatchAllWordForms = False
End With
Selection.Find.Execute Replace:=wdReplaceAll
Selection.Find.ClearFormatting
Selection.Find.Font.Bold = True
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = "( [0-9]{2}:[0-9]{2})"
.Replacement.Text = "^p1"
.Forward = True
.Wrap = wdFindContinue
.Format = True
.MatchCase = False
.MatchWholeWord = False
.MatchByte = False
.MatchAllWordForms = False
.MatchSoundsLike = False
.MatchWildcards = True
End With
Selection.Find.Execute Replace:=wdReplaceAll
End Sub















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









