







上一篇介绍了强化学习的一些基本概念强化学习系列--概念介绍(Introduction to Reinforcement Learning),今天我们讲解一个简单且经典的强化学习算法:Q-Learning。
背景
按照不同分类标准,Q Learning可以被分为:model-free,off-policy,value-based,TD等类别。
Q Learning算法思想主要是去学习一个纵坐标为状态(state)、横坐标是动作(action)、取值为当前状态下执行对应action时所获得的奖励(短期激励+长期收益)的Q-table矩阵。我们通过大量试错获取经验(reward)来更新Q-table,最终通过Q-table中记录的奖励情况来指导某个state执行哪个action可以获取最大收益。
举个例子: 一个小朋友(agent)假设无任何历史奖惩经验,那么Q-table中每个元素初使值都为0。
当小朋友还没做完作业状态时(state1),去学习(action1)还是去看电视(action2)得到父母的奖励是不一样的,学习的奖励会是一个棒棒糖(+2),看电视的奖励将会是挨揍一顿(-2)。
当小朋友已经做完作业时(state2),去学习(action 1)还是去看电视得到的奖励又会和state1的情况有所不同,此时学习的奖励为+1,看电视奖励会是-1。
...
多次经验总结后,Q-table的取值更新如下:
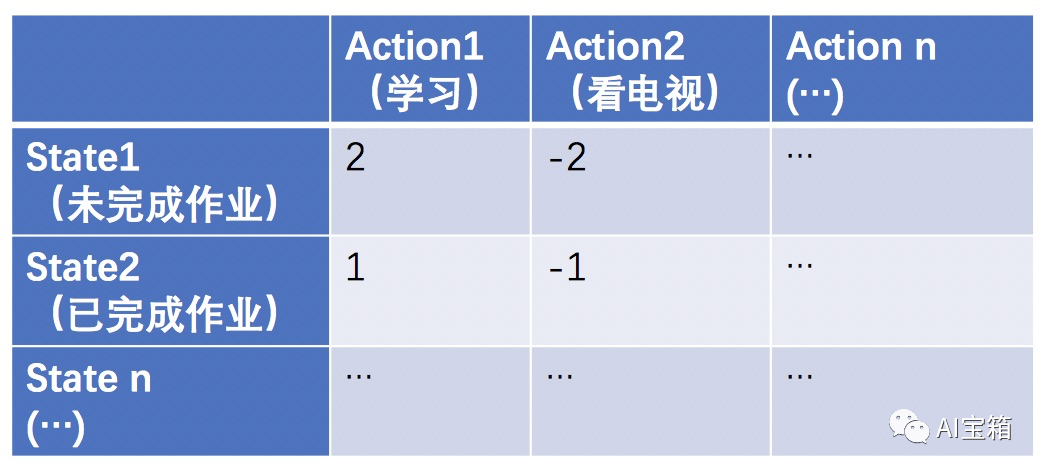
要特别说明的是,Q(s, a)除了代表本次(s, a)操作获得的reward外,还考虑未来的收益。即:Q(s, a) = reward(本次s-a操作) + Q(未来奖励)。
算法思想
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 688
688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









