






模型融合
用目前评分最高的模型作为基准模型,和其他模型进行stacking融合,得到最终模型以及评分结果。
考虑到时间问题,最优分箱和IV值计算先过,直接利用随机森林筛选出来的特征进行训练,只是实现整个过程,并不比较哪个模型效果好。
模型融合没有想象的那么复杂,从最简单的Voting说起,也可以说是一种模型融合。假设对于一个二分类问题,有3个基础模型,那么就采取投票制的方法,投票多者确定为最终的分类。
有一个非常经典的图,如下所示:
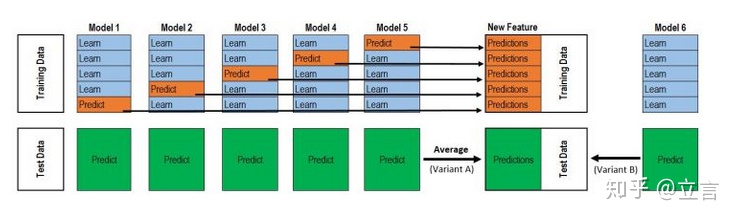
第一次看可能有些迷糊,模型融合看了很多资料,这篇文章讲的最透彻。
引入模型融合模块mlxtend:
from mlxtend.classifier import StackingClassifierStackingClassifier模块说明:
StackingClassifier(classifiers, meta_classifier, use_probas=False, average_probas=False, verbose=0, use_features_in_secondary=False)
参数:
classifiers : 基分类器,数组形式,[cl1, cl2, cl3]. 每个基分类器的属性被存储在类属性 self.clfs_.
meta_classifier : 目标分类器,即将前面分类器合起来的分类器
use_probas : bool (default: False) ,如果设置为True, 那么目标分类器的输入就是前面分类输出的类别概率值而不是类别标签
average_probas : bool (default: False),用来设置上一个参数当使用概率值输出的时候是否使用平均值。
verbose : int, optional (default=0)。用来控制使用过程中的日志输出,当 verbose = 0时,什么也不输出, verbose = 1,输出回归器的序号和名字。verbose = 2,输出详细的参数信息。verbose > 2, 自动将verbose设置为小于2的,verbose -2.
use_features_in_secondary : bool (default: False). 如果设置为True,那么最终的目标分类器就被基分类器产生的数据和最初的数据集同时训练。如果设置为False,最终的分类器只会使用基分类器产生的数据训练。
属性:
clfs_ : 每个基分类器的属性,list, shape 为 [n_classifiers]。
meta_clf_ : 最终目标分类器的属性
方法:
fit(X, y)
fit_transform(X, y=None, fit_params)
get_params(deep=True),如果是使用sklearn的GridSearch方法,那么返回分类器的各项参数。
predict(X)
predict_proba(X)
score(X, y, sample_weight=None), 对于给定数据集和给定label,返回评价accuracy
set_params(params),设置分类器的参数,params的设置方法和sklearn的格式一样
引入相应的包:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from mlxtend.classifier import StackingClassifier
from xgboost import XGBClassifier
将数据三七分,并标准化:
y_lable = data_last.status
x_features = data_last.drop(columns="status")
X_train, X_test, y_train, y_test = train_test_split( x_features, y_lable, test_size=0.3, random_state=2018)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.fit_transform(X_test)代码如下,只是一个大致过程,没有用循环试着比较每个模型融合效果:
LG_modle = LogisticRegression(class_weight="balanced",solver="liblinear",max_iter=200)
svm_modle = SVC(class_weight="balanced",gamma='auto', probability=True)
tree_modle = DecisionTreeClassifier(class_weight="balanced")
RF_modle = RandomForestClassifier(class_weight="balanced",n_estimators=200)
GBDT_modle = GradientBoostingClassifier(n_estimators=200)
LGB_modle = LGBMClassifier(n_estimators=200)
XGB_modle = XGBClassifier(n_estimators=200)
# stacking模型
sclf = StackingClassifier(classifiers=[LGB_model, GBDT_model, RF_model], use_probas=True,
average_probas=False,
meta_classifier=LG_model)电脑安装xgboost、mlxtend一直不成功,有时间接着操作。















 9195
9195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









