






随着互联网的发展,我们逐渐从信息匮乏的时代进入了信息过载的时代。在这个海量数据的时代,无论是信息的消费者还是信息生产者都遇到了很大挑战。同样无论是消费者还是生产者都产生了海量的数据,各行各业也越来越意识到数据驱动的重要性,很多互联网企业文化中都有比较重要一条:用数据说话。
数据驱动
主要分为三部分:
数据驱动理念
数据驱动价值
数据驱动实践之数据建模[时序序列算法]
一、数据驱动理念
现在很多互联网从业人员,无论是产品经理的产品设计还是功能上线后的效果评估,又或者是工程师开发的模块性能,都是需要用数据说话。
如果没有数据来支撑,方案是无法通过的,所以需要用科学的数据方法来支撑即数据驱动。
很多人认为,数据驱动就是把一些开源组件凑在一起即可,但是真正在企业实践中,会发现人才储备、数据源、数据流、数据分析等一系列问题就开始凸显出来,并不是技术栈的叠加。
什么是数据驱动?数据驱动是通过移动互联网或者其他的相关软件为手段采集海量的数据,将数据进行组织形成信息,之后对相关的信息进行整合和提炼,在数据的基础上经过训练和拟合形成自动化的决策和智能模型。
现在企业聚焦点逐步向如何将企业内外部产生的数据高效应用,从而让企业决策不再依赖“拍脑袋”,而是转向依靠“数据驱动”。
二、数据驱动的价值
数据是信息的一种存储形式,而信息是消除不确定性的东西。我们需要将信息转化为企业有用的价值,即将离散元素(数据)->信息(连接元素)->知识(组织信息)->智慧(应用知识)。
数据驱动的价值主要分为:
驱动决策
- 驱动产品智能

那么数据驱动如何实践?数据驱动是一种流式和自助式的闭环驱动,主要的过程:
数据采集
(mobile/pc/sensor等)
数据建模
(supervised/unsupervised/reinforcement/semi-supervisedlearning/time series等)
数据分析
(下钻/留存/属性/用户分群分析等)
数据反馈
(check/review等)

三、时间序列算法
由于数据驱动整个闭环比较复杂,只应用数据驱动环节中一小部分实践-数据建模。
简单介绍一下时间序列算法分析,时间序列三大“组件”:Trend(趋势)、Seasonal(周期)和Random(随机波动)。(编程语言R,公式MathJax)
1、趋势
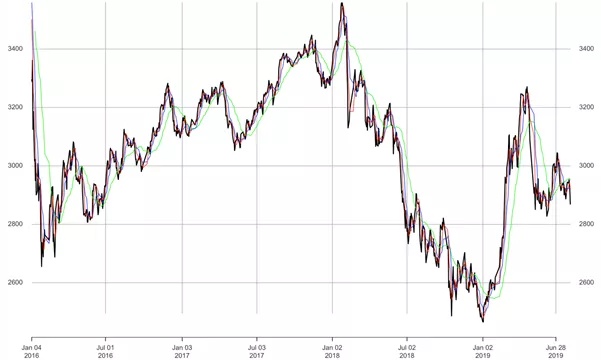
发现数据的趋势是我们作为算法工程师最基本的要求,最容易的分析就是smoothing method。
plot(Data['2016/'])
#green最近30个交易日的smoothingmethod
lines(SMA(Data['2015-12-01/'],n=30),col= "green")
#blue最近10个交易日的smoothingmethod
lines(SMA(Data['2015-12-15/'],n=10),col= "blue")
#red 最近5个交易日的smoothingmethod
lines(SMA(Data['2015-12-20/'],n=5),col= "red")
如下图所示:
2、周期
比如气温等时间序列数据是带有周期性的,我们以北京地区每日最高气温,呈现波形趋势,基本上也是以年作为周期的。
beijing = xts(data, sep = ",",fileEncoding = "GBK"), order.by = seq.Date(as.Date("2011-02-01"), as.Date("2017-01-31"), "day"))
class(beijing)
plot(beijing)
3、随机波动
一个时间序列可以不存在周期性、也可以不存在趋势,但肯定存在不规则的波动。理论上数据应该符合正太分布的。
4、时间序列预测分析
我们常用的时间序列分析模型:指数平滑算法和ARIMA算法。
指数平滑算法模型原理

该说明预测值收到序列中每个观测值的影响,可以看出随着n的增大,该项的n次方对预测值是越来越小的。基于该算法衍生了很多models:Holt和Winter等等。
ARIMA(p,d,q)模型原理
ARIMA并不是一个特定的模型,而是一类模型的总称。
p代表预测模型中采用的时序数据本身的滞后数(lags) ,也叫做AR/Auto-Regressive项。d代表时序数据需要进行几阶差分化,才是稳定的,也叫Integrated项。
q代表预测模型中采用的预测误差的滞后数(lags),也叫做MA/MovingAverage项。
ARIMA(p,d,q)序列是阶差分后服从ARMA(p,q)模型的非平稳时间序列。
设d是一个正整数, 如果:
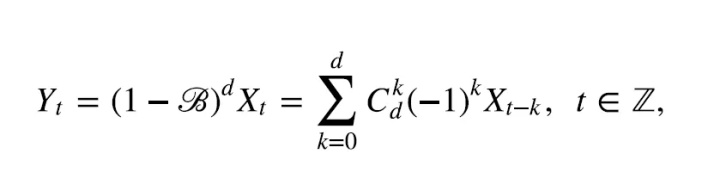
是一个ARMA(p,q)序列, 其模型MA部分的特征多项式没有等于1的特征根,则{X_t}称是一个求和自回归滑动平均(p,d,q)序列. 简称为ARIMA(p,d,q)序列。根据d的取值,其通解形式也是不一样的。
这里就不列出,接下来我们直接整一个股票收盘指数进行预测。
4、时间序列预测Demo
1)首先获得一个平稳的时间序列,我们可以对序列进行差分处理;
plot(diff(timeData,differences=1))plot(diff(timeData,differences=2))
进行了一阶差分和二阶差分处理,通过图像可以看到二阶的相对比较稳定一些即平稳序列。
2)找到合适的ARIMA(p,d,q)模型中p,d,q值;
其中d已经在第一步中得到,我们需要check时间序列的自相关和偏相关得到,即acf和pacf分析。
dataDiff=diff(data,2)acf(dataDiff,lag.max = 30,na.action = na.pass)
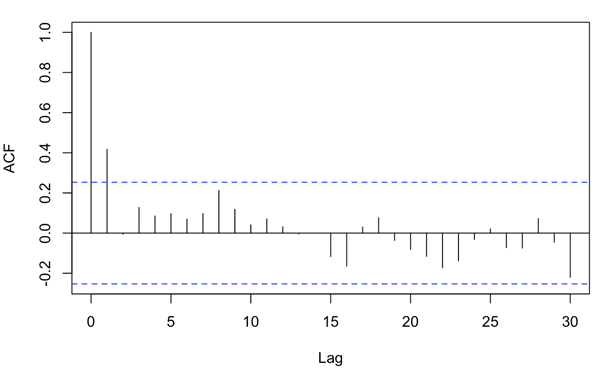
由图中可以看到,自相关显示滞后1阶和7阶自相关值超出边界,1阶比7阶显著,其他值没有超出边界。所以自相关值选择1阶。
pacf(dataDiff,lag.max = 30,na.action = na.pass)
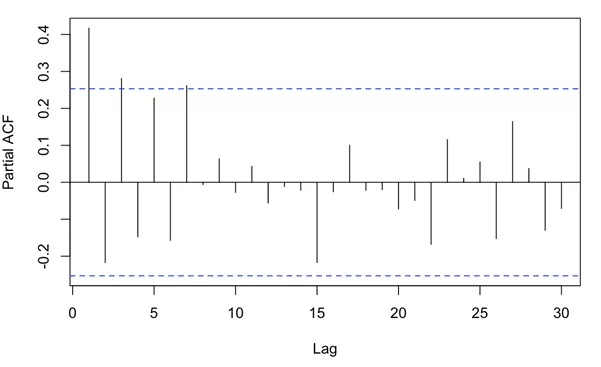
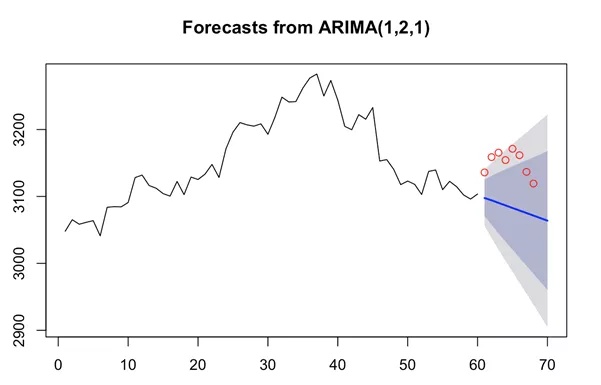
由图可看出,偏相关值选择1阶,综上所述p,d,q分别为1,2,1,ARIMA(1,2,1)。
3)构建arima模型;
arimaModel=arima(data,order =c(1,2,1))
> arimaModel
Call:
arima(x = data, order = c(1, 2, 1))
Coefficients:
ar1 ma1
-0.1941 -0.9142
s.e. 0.1364 0.0657
sigma^2 estimated as 454.8: log likelihood = -260.86, aic = 527.72
4)预测数据并与实际值进行比对;
arima=arima(data,order=c(1,2,1))forecast=forecast(arima,h=8,level=c(99.5))> forecast Point Forecast Lo99.5 Hi99.5613097.6423037.7803157.504623094.2743014.0703174.478633090.3972990.3703190.423643086.6182968.0493205.187653082.8202946.1143219.526663079.0262924.3643233.687673075.2312902.6253247.836683071.4362880.7983262.074observation=data[1:8]points(x=seq(61,68,1),y=obervation,col="red")















 5517
5517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









