







目录

BPTT算法推导
对于一个普通的RNN来说,其前向传播过程为:
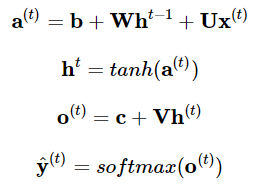
先介绍一下等下计算过程中会用到的偏导数:
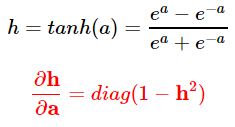
关于tanh求导的过程见下面注1。
![]() indicates the diagonal matrix(对角矩阵) containing the elements
indicates the diagonal matrix(对角矩阵) containing the elements ![]() 。
。
另一个,当y采用one-hot并且损失函数L为交叉熵时:
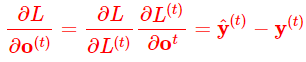
这里涉及到softmax求导的规律,关于softmax求导的过程见下面注2。
(1)接下来从RNN的尾部开始,逐步计算隐藏状态![]() 的梯度。如果
的梯度。如果![]() 是最后的时间步,
是最后的时间步,![]() 就是最后的隐藏输出。
就是最后的隐藏输出。
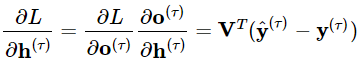
(2)然后一步步往前计算![]() 的梯度,注意
的梯度,注意![]() 同时有
同时有![]() 和
和![]() 两个后续节点,
两个后续节点,

所以:
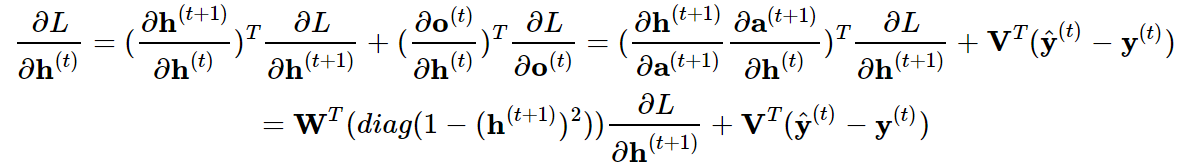
剩下的参数计算起来就简单多了:

损失函数为交叉熵损失函数(二元交叉熵损失函数),输出的激活函数应该为sigmoid函数,隐藏层的激活函数为tanh函数。(二分类问题)

注1:激活函数tanh(x)求导


作用:非常优秀,几乎适合所有的场景。
缺点:该导数在正负饱和区的梯度都会接近于 0 值,会造成梯度消失。还有其更复杂的幂运算。
可视化:

注2 softmax求导
使用交叉熵代价函数(多分类交叉熵形式)+softmax函数进行反向传播:
使用该方法时,应先将真实输出![]() 经过softmax函数进行转换,再带入代价函数中进行计算。即:
经过softmax函数进行转换,再带入代价函数中进行计算。即:
softmax函数:

多分类交叉熵:
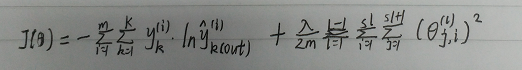

计算误差函数对 求导的导数:
求导的导数:
当我们对分类的Loss进行改进的时候,我们要通过梯度下降,每次优化一个step大小的梯度,这个时候我们就要求Loss对每个权重矩阵的偏导,然后应用链式法则。那么这个过程的第一步,就是对softmax求导。
计算误差函数对未经过softmax函数转化的输出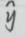 ,即求导的导数,根据链式法则
,即求导的导数,根据链式法则![]() ,可将其转化为误差函数对经过softmax函数转化后的输出求导的导数,再乘以经过softmax函数转化后的输出对求导的导数:
,可将其转化为误差函数对经过softmax函数转化后的输出求导的导数,再乘以经过softmax函数转化后的输出对求导的导数:
忽略样本数量,即:

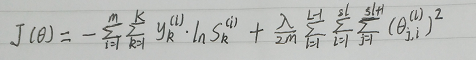
其中,
(1)损失函数对softmax层求导:
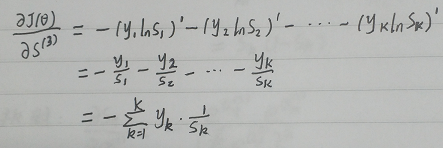
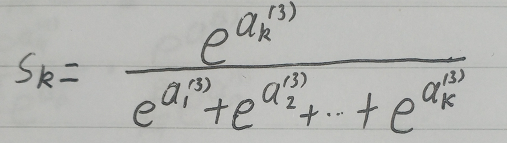
我们对Si求导,其实是对Si中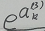 的求导,从公式中可以看出,由于每个Si的分母中都包含
的求导,从公式中可以看出,由于每个Si的分母中都包含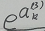 ,因此对所有的Si都要求导。
,因此对所有的Si都要求导。
其中,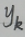 为第k个神经元的期望输出值,
为第k个神经元的期望输出值,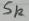 为第k个神经元经过softmax函数转化后的输出,即y_out。
为第k个神经元经过softmax函数转化后的输出,即y_out。
(2)softmax层对输出层求导
分两种情况:
① q = k

② q ≠ k

(3)输出层对隐藏层输出神经元求导
此时我们分别求出了两个偏导数,将两个偏导数合并起来(相乘),因为softmax层对输出层的偏导数有两种情况,因此链式求导的结果也分 q = k 和 q ≠ k 两种情况,加以合并:

由于:
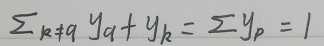
因此:
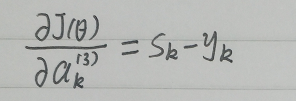
主要:花书BPTT公式推导:https://www.cnblogs.com/zyb993963526/p/13797144.html
https://blog.csdn.net/qq_14962179/article/details/88832275
RNN的简单的推导演算公式(BPTT):https://cloud.tencent.com/developer/article/1074307
RNN详解及BPTT详解:https://blog.csdn.net/zhaojc1995/article/details/80572098















 3211
3211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









