






解决Python编码面试问题是为面试做准备的最好方式。本文将带领你了解这些问题所涉及的15个例子和五个概念。
关注《Python学研大本营》
最近不仅北上广的互联网大厂在裁员,美国科技企业也开始了裁员潮。这时刻提醒我们,在这个大环境大趋势之下,永远保持自己的学习力和战斗力,才是一个人的核心竞争力。
如果你正在准备求职或面试,那么关于Python的这五个方面,15个例子,你不得不看。
这篇文章的作者是 Nate Rosidi,发布于KDnuggets。
五个主题
了解Python是每个数据科学家应该磨练的关键技能之一。这并不是没有原因的。Python的能力,结合Pandas库,以多种不同方式处理和分析数据,使其成为数据科学工作的理想工具。
毫不奇怪,所有寻找数据科学家的公司都会在求职面试中测试他们的Python技能。
我们来看看,为了找到一份数据科学工作,你应该熟悉哪些技术概念,以及Python/Pandas函数。
这就是我们要讨论的五个主题。
-
聚合、分组和数据排序
-
连接表
-
过滤数据
-
文本操作
-
日期时间操作
不言而喻,这些概念很少被单独测试,所以通过解决一个问题,你必须展示你对多个Python主题的知识。
1.聚合、分组和排序数据
聚合、分组和数据排序,这三个技术性话题经常出现在一起,它们是创建报告和进行任何形式的数据分析的基础。
它们允许你进行一些数学运算,并以一种可表现的和用户友好的方式展示你的发现。
下面我们将向你展示几个实际例子。
Python编码面试问题#1:类性能
这个盒子面试问题问你。
"你得到一个包含班级学生作业分数的表格。写一个查询,找出所有作业中总分的最大差异。只输出两个学生之间的总分差。"
该问题的链接:https://platform.stratascratch.com/coding/10310-class-performance?python=1
你需要使用的表是box_scores,它有以下几列。

表中的数据看起来是这样的。

作为回答问题的第一步,你应该把所有作业的分数加起来。
import pandas as pd
import numpy as np
box_scores['total_score'] = box_scores['assignment1']+box_scores['assignment2']+box_scores['assignment3']
这一部分代码将给你带来这个结果。
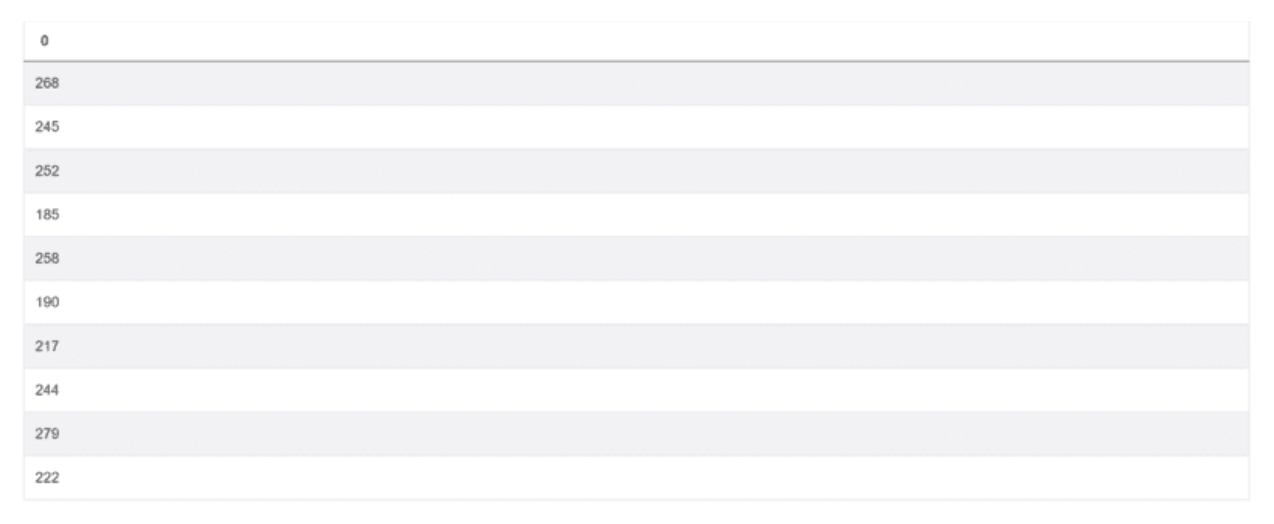
现在你知道了,下一步是找到总分之间的最大差异。你需要使用max()和min()函数来做到这一点。或者,更具体地说,这两个函数的输出之间的差值。把这个加入到上面的代码中,你就得到了一个最终的答案。
import pandas as pd
import numpy as np
box_scores['total_score'] = box_scores['assignment1']+box_scores['assignment2']+box_scores['assignment3']
box_scores['total_score'].max() - box_scores['total_score'].min()
这就是你要寻找的输出。
这个问题要求只输出这个差异,所以不需要其他列。
Python编码面试题#2:企业的检查分数
前一个问题不需要任何数据分组和排序,不像下面这个旧金山市的问题。
"找出每个企业的检查分数中值,并将结果与企业名称一起输出。根据检查得分,按降序排列记录。试着想出你自己精确的中位数计算。在Postgres中,有percentile_disc函数可用,但它只是近似值。"
该问题的链接:https://platform.stratascratch.com/coding/9741-inspection-scores-for-businesses?python=1
在这里,你应该使用notnull()函数来确保你只得到有检查分数的企业。此外,你必须对企业名称的数据进行分组,并计算出检查分数的中位数。使用median()函数。另外,使用sort_values()函数将输出结果按降序排序。
Python编码面试题#3:按品种分类的记录数
看一下这个微软的问题。
"在数据集中找到属于每个品种的记录总数。输出品种和相应的记录数。将记录按品种以升序排列。"
该问题的链接。https://platform.stratascratch.com/coding/10168-number-of-records-by-variety?python=1
经过前两个例子,这应该不难解决。首先,你应该按variety 和sepal_length这两列分组。为了找到每个品种的记录数,使用count()函数。最后,使用sort_values按照字母顺序对variety进行排序。
2.连接表
在前面所有的例子中,我们只得到一个表。我们选择这些例子,是为了让你更容易理解Python中的聚合、分组和数据排序是如何工作的。
然而,作为一个数据科学家,你更经常需要知道如何写一个从几个表中提取数据的查询。
Python编码面试问题#4:最低价订单
在Python中连接两个表最简单的方法之一是使用merge()函数。我们将这样做来解决亚马逊的问题。
"找到每个客户的最低订单费用。输出客户的ID以及名字和最低订单价格"。
该问题的链接:https://platform.stratascratch.com/coding/9912-lowest-priced-orders?python=1
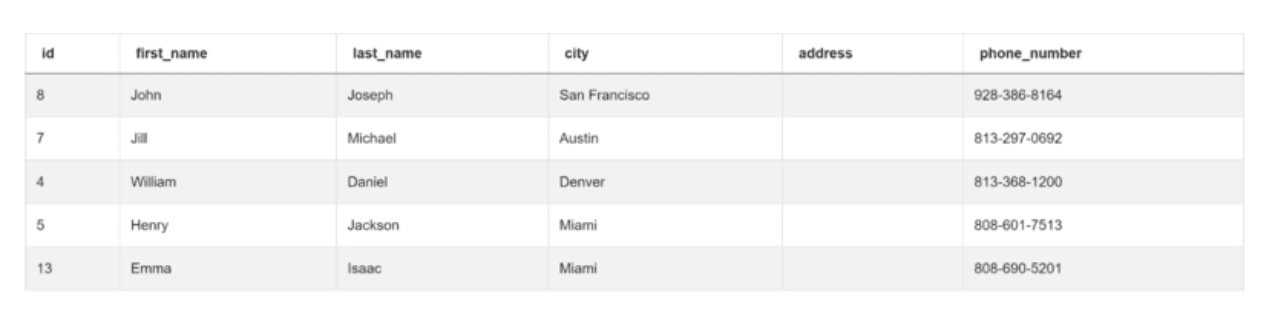
你有两个表要处理。第一个表是客户。

以下是数据。
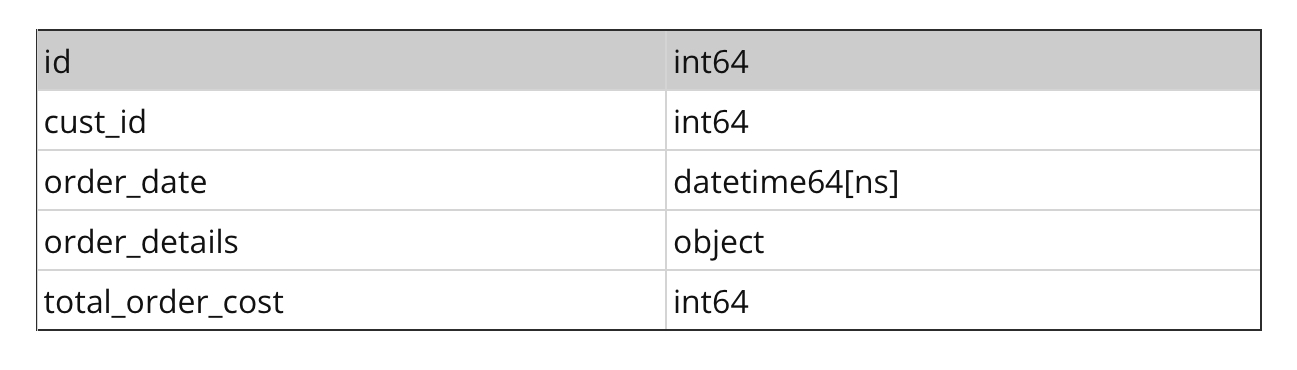
第二个表被命名为订单,有以下几列。
以下是数据。
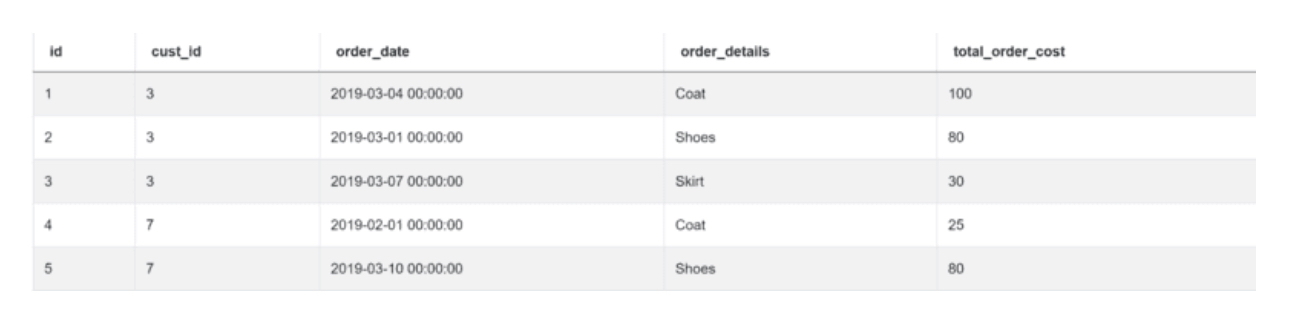
由于需要两个表的数据,必须将它们合并或内联。
import pandas as pd
import numpy as np
merge = pd.merge(customers, orders, left_on="id", right_on="cust_id")
你对客户表中的列id和表顺序中的列cust_id进行操作。结果显示两个表是一个。
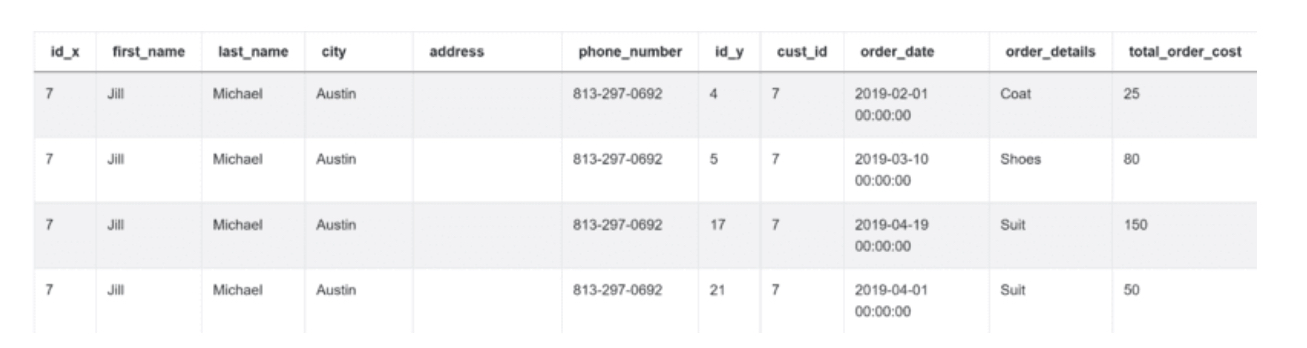
一旦你完成了这个工作,使用groupby()函数按cust_id和first_name对输出进行分组。这些是问题要求你显示的列。你还需要显示每个客户的最低订单成本。你可以用min()函数来做。
完整的答案是这样的。
import pandas as pd
import numpy as np
merge = pd.merge(customers, orders, left_on="id", right_on="cust_id")
result = merge.groupby(["cust_id", "first_name"])["total_order_cost"].min().reset_index()
该代码返回所需的输出。
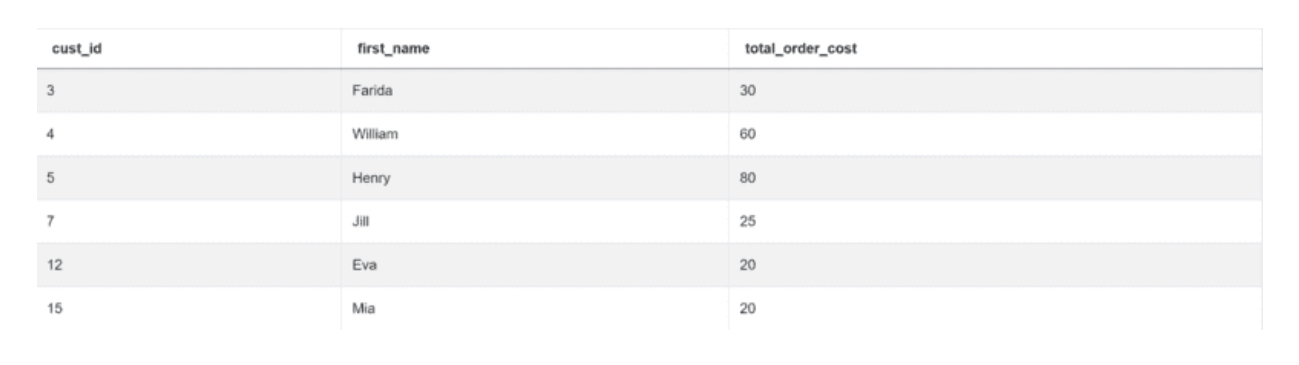
Python编码面试问题#5:按职称和性别划分的收入
这里,我们有另一个来自旧金山市的问题。
“根据雇员的职称和性别,找出平均总报酬。总薪酬的计算方法是将每个员工的工资和奖金加在一起。 但是,并不是每个员工都能得到奖金,所以在计算时,不考虑没有奖金的员工。雇员可以获得一个以上的奖金。 输出员工的头衔,性别(即性别),以及平均总报酬。”
问题链接。https://platform.stratascratch.com/coding/10077-income-by-title-and-gender?python=1
在回答这个问题时,第一步应该是按工人和奖金分组,同时使用sum()函数来获得每个工人id的奖金。然后你应该合并你所掌握的表。这也是一个内部连接。一旦你这样做了,你就可以通过增加工资和奖金得到总的报酬。最后一步是输出雇员的头衔、性别和平均总报酬,你可以通过使用mean()函数得到。
Python编码面试问题#6:产品交易数
这里有一个微软的问题。
“找出每个产品发生的交易数量。输出产品名称以及相应的交易数量,并按产品ID以升序排列记录。你可以忽略没有交易的产品。” 该问题的链接。https://platform.stratascratch.com/coding/10163-product-transaction-count?python=1
这里有一些写代码的提示。首先,你应该使用notnull()函数来获取至少有一个交易的产品。接下来,使用merge()函数将此表与excel_sql_inventory_data表进行内联。使用groupby()和transform()来获得交易的数量。然后去掉重复的产品,显示每个产品的交易数量。最后,按产品ID对输出进行排序。
3.数据过滤
当你使用Python时,你通常会在大量的数据上使用它。然而,你不会被要求输出所有的数据,因为那根本毫无意义。
分析数据还包括设置某些标准,只拉出你想在输出中看到的数据。为此,你应该使用某些过滤数据的方法。
虽然merge()也有过滤数据的方式,但这里我们说的是使用比较运算符(==, <, >, <=, >=),between(),或其他一些方式来限制输出中的行数。让我们看看这在Python中是如何实现的!
Python编码面试问题#7。找到2010年排名前10的歌曲
这是一个在Spotify面试时可能会被问到的问题。
"2010年排名前10位的歌曲是什么?输出排名、组合名称和歌曲名称,但不要两次显示同一首歌。根据year_rank以升序对结果进行排序。"
该问题的链接:https://platform.stratascratch.com/coding/9650-find-the-top-10-ranked-songs-in-2010?python=1
要解决这个问题,你只需要billboard_top_100_year_end表。

表格中的数据是这样的。
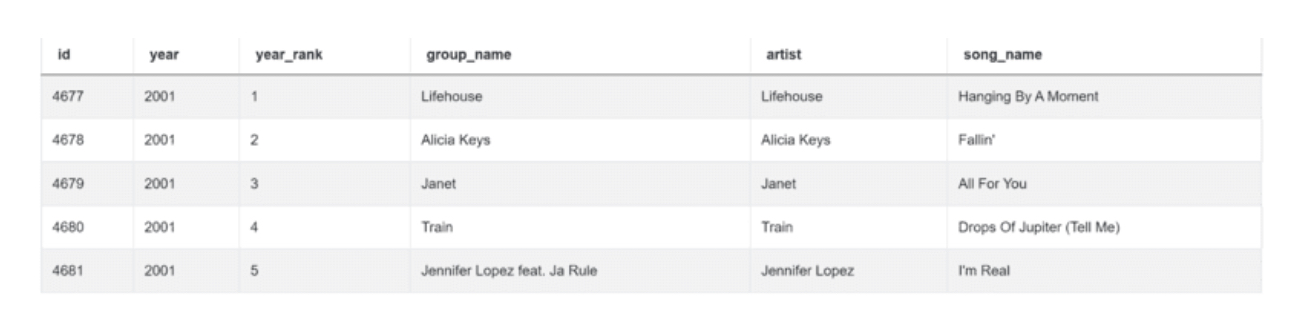
下面是我们回答这个问题的方法。
import pandas as pd
import numpy as np
conditions = billboard_top_100_year_end[(billboard_top_100_year_end['year'] == 2010) & (billboard_top_100_year_end['year_rank'].between(1,10))]
上面的代码设置了两个条件。第一个是使用' == '操作符。通过使用它,我们只选择2010年出现的歌曲。第二个条件只选择排名在1到10之间的歌曲。 运行此代码返回:
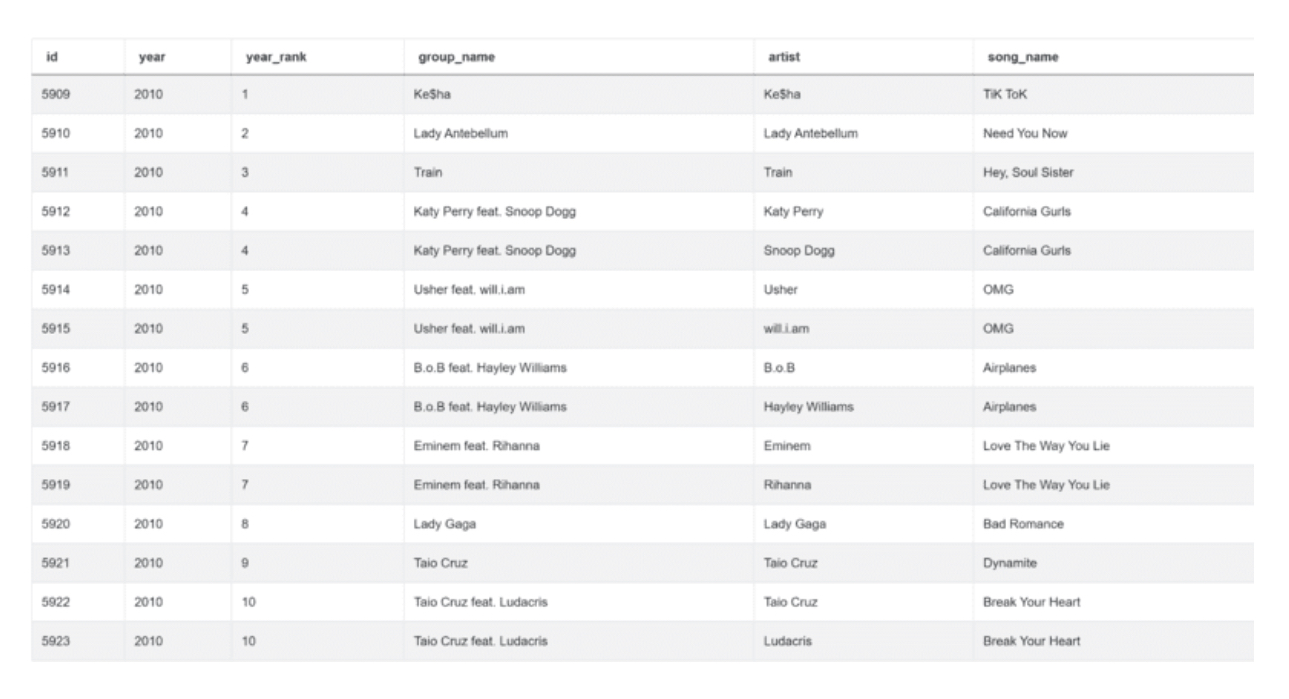
在此之后,我们只需要选择三个列:year_rank、group_name和song_name。我们还将使用drop_duplices()函数来删除重复项。这样代码就完整了:
import pandas as pd
import numpy as np
conditions = billboard_top_100_year_end[(billboard_top_100_year_end['year'] == 2010) & (billboard_top_100_year_end['year_rank'].between(1,10))]
result = conditions[['year_rank','group_name','song_name']].drop_duplicates()
它会给你2010年排名前10的歌曲。

Python编码面试题#8:纽约市和哈林区的公寓
尝试解决Airbnb的问题。
"找到50个公寓搜索纽约市哈莱姆区的细节。"
该问题的链接:https://platform.stratascratch.com/coding/9616-apartments-in-new-york-city-and-harlem?python=1)
这里有一些提示。你需要设置三个条件,只得到公寓类别,只得到哈林区的公寓,而且城市必须是纽约市。这三个条件都将使用'=='运算符来设置。你不需要显示所有的公寓,所以使用head()函数来限制输出中的行数。
Python 编码面试问题 #9: 重复的电子邮件
最后一个问题侧重于过滤数据是由Salesforce。
"找到所有有重复的电子邮件"。
该问题的链接。https://platform.stratascratch.com/coding/9895-duplicate-emails?python=1
这个问题相当简单。你需要使用groupby()函数,按电子邮件分组,并找出每个电子邮件地址出现的次数。然后在电子邮件地址的数量上使用'>'运算符,以获得重复的邮件。
4.文本操作
在处理数据时,你必须对其进行处理,使其更适合于你的分析。文本数据往往就是这种情况。它包括根据存储的文本为数据分配新的数值,解析和合并文本,或查找其长度、某个字母、符号的位置等。
Python编码面试问题#10:评论数的评论仓
下一个问题是由Airbnb提出的。
“为了更好地了解评论数对住宿价格的影响,将评论数与价格一起归入以下几组。
0条评论:NO
1至5条评论:FEW
6到15条评论:SOME
16到40条评论:MANY
超过40条评论:A LOT
输出价格和其分类。在住宿级别上进行分类。”
该问题的链接:https://platform.stratascratch.com/coding/9628-reviews-bins-on-reviews-number?python=1
你只用了一个表,但这个表有相当多的列。这个表是airbnb_search_details,列是。
下面是该表的第一行:

编写代码的第一步应该是获得评论的数量。
import pandas as pd
import numpy as np
num_reviews = airbnb_search_details['number_of_reviews']
你会得到:
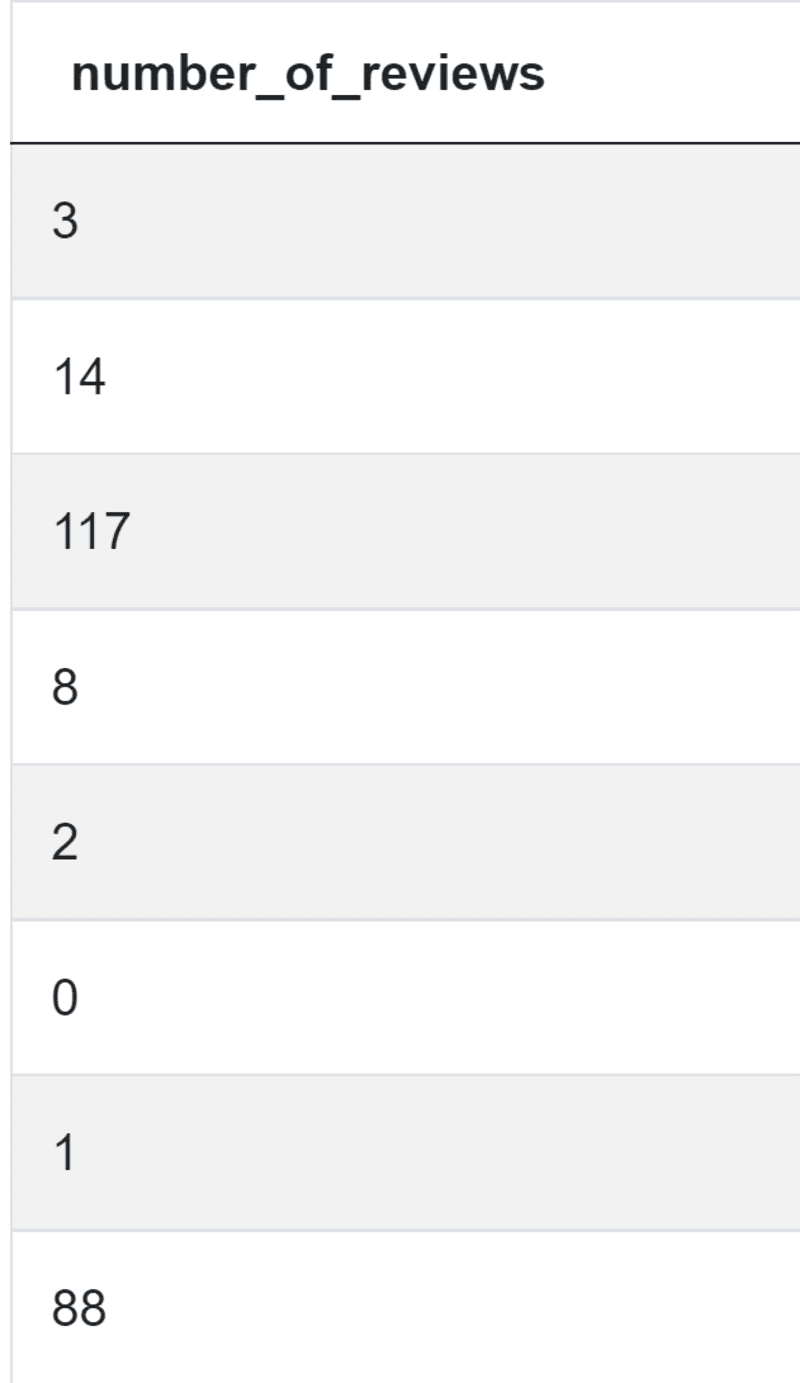
接下来,你想得到有0条评论的住宿,然后是1-5条,6-15条,16-40条,以及40条以上的评论。为了得到这些,你需要'=='和'>'运算符的组合,以及between()函数。
import pandas as pd
import numpy as np
num_reviews = airbnb_search_details['number_of_reviews']
condlist = [num_reviews == 0, num_reviews.between(1,5),num_reviews.between(5,15),num_reviews.between(15,40),num_reviews>40]
下面是你目前的输出应该是什么样子。
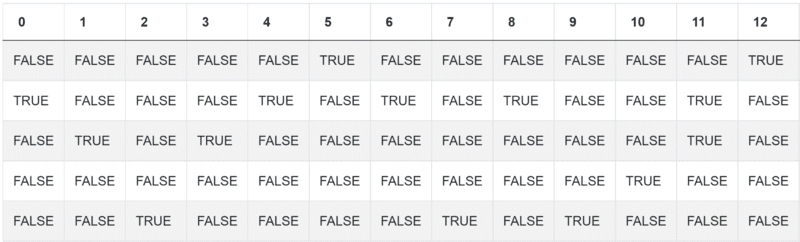
现在是以分配类别的形式来处理文本。这些是 没有、少数、一些、许多、很多。你的代码到现在为止是。
import pandas as pd
import numpy as np
num_reviews = airbnb_search_details['number_of_reviews']
condlist = [num_reviews == 0, num_reviews.between(1,5),num_reviews.between(5,15),num_reviews.between(15,40),num_reviews>40]
choicelist = ['NO','FEW','SOME','MANY','A LOT']
好了,这里是你的分类。
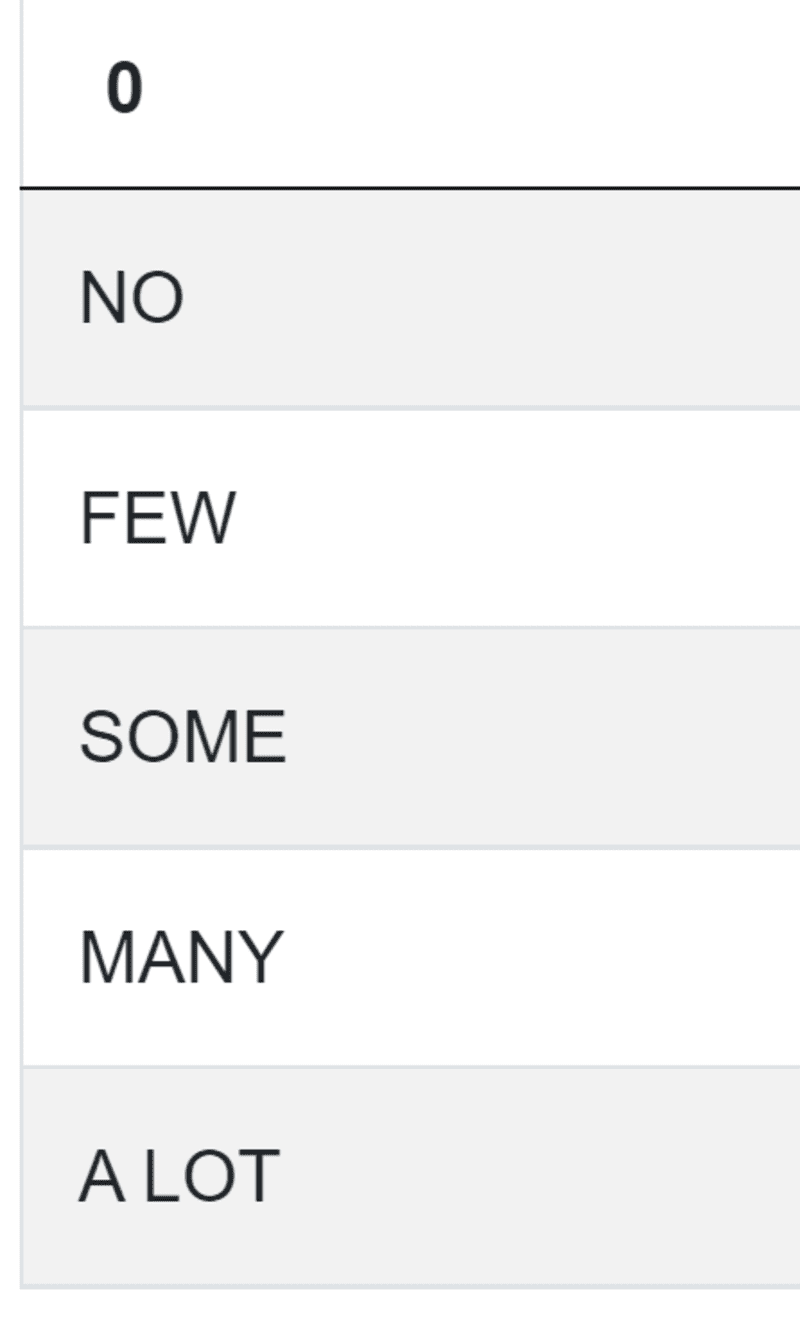
最后一步是将这些类别分配给住宿,并列出其价格。
import pandas as pd
import numpy as np
num_reviews = airbnb_search_details['number_of_reviews']
condlist = [num_reviews == 0, num_reviews.between(1,5),num_reviews.between(5,15),num_reviews.between(15,40),num_reviews>40]
choicelist = ['NO','FEW','SOME','MANY','A LOT']
airbnb_search_details['reviews_qualification'] = np.select(condlist,choicelist)
result = airbnb_search_details[['reviews_qualification','price']]
这段代码会让你得到所需的输出。
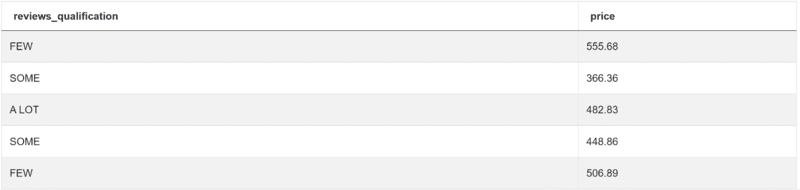
Python编码面试问题#11:企业名称长度
下一个问题是由旧金山市提出的。
"找出每个企业名称中的字数。避免将特殊符号算作单词(如&)。输出企业名称和它的字数"。
该问题的链接。https://platform.stratascratch.com/coding/10131-business-name-lengths?python=1
在回答这个问题时,你应该首先使用drop_duplicates()函数只找到不同的企业。然后使用replace()函数将所有的特殊符号替换为空白,这样你以后就不会计算它们。使用split()函数将文本分割成一个列表,然后使用len()函数来计算字数。
Python编码面试题#12:字母'a'的位置
亚马逊的这个问题要求你:
"找出工人的名字'Amitah'中字母'a'的位置。使用基于1的索引,例如,第二个字母的位置是2"。
该问题的链接。https://platform.stratascratch.com/coding/9829-positions-of-letter-a?python=1
该解决方案有两个主要概念。第一个是使用'=='运算符过滤工作者'Amitah'。第二个是在一个字符串上使用find()函数来获得字母'a'的位置。
5.日期时间操作
作为一名数据科学家,你会经常与日期打交道。根据可用的数据,你可能会被要求将数据转换为日期时间,提取某个时间段(如月或年),或以任何其他合适的方式操作日期时间。
Python编码面试题#13:过去30天内每个用户的评论数
这里有一个Meta/Facebook的问题。
"返回每个用户在过去30天内收到的评论总数。不要输出在定义时间段内没有收到任何评论的用户。假设今天是2020-02-10"。
该问题的链接。https://platform.stratascratch.com/coding/2004-number-of-comments-per-user-in-past-30-days?python=1
你可以在表fb_comments_count中找到数据。
数据也在这里:
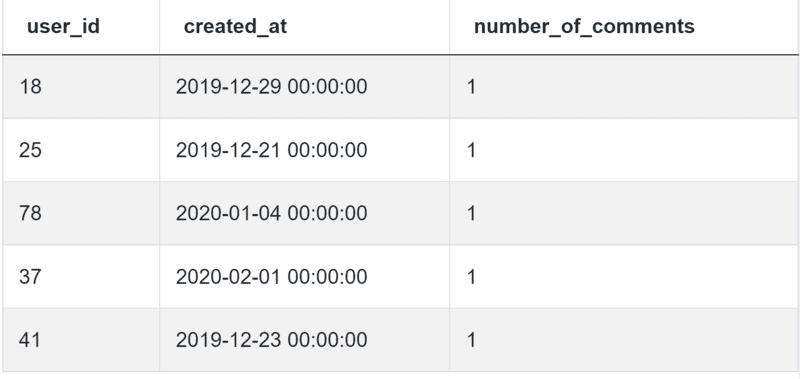
看看解决方案,然后我们将在下面解释:
import pandas as pd
from datetime import timedelta
result = fb_comments_count[(fb_comments_count['created_at'] >= pd.to_datetime('2020-02-10') - timedelta(days=30)) & (
fb_comments_count['created_at'] <= pd.to_datetime('2020-02-10'))].groupby('user_id')[
'number_of_comments'].sum().reset_index()
要找到从2020-02-10开始不超过三十天的评论,你首先需要用to_datetime()函数把这个日期转换成数据时间。为了得到你感兴趣的评论的最新日期,用timedelta()函数从今天减去30天。所有你感兴趣的评论的日期都等于或大于这个差值。另外,你想排除所有在2020-02-10之后发布的评论。这就是为什么有第二个条件的原因。最后,通过用户ID分组,并使用sum()函数来获得每个用户的评论。
如果你做对了一切,你会得到这样的输出。
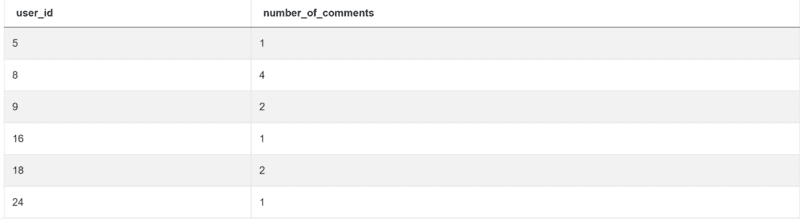
Python编码面试问题#14:寻找用户购买的东西
这是亚马逊的问题。
"写一个查询,以识别返回的活跃用户。一个返回的活跃用户是指在他们购买的任何其他产品的7天内进行了第二次购买的用户。输出这些返回的活跃用户的user_ids的列表"。
该问题的链接。https://platform.stratascratch.com/coding/10322-finding-user-purchases?python=1
要解决这个问题,你需要使用strftime()函数来获得MM-DD-YYY格式的购买日期。然后使用sort_values()函数,根据用户的ID和购买日期,以升序排序输出。为了得到前一个顺序,应用shift()函数,按用户ID分组,并显示购买日期。
使用to_datetime转换订单和前一个订单的日期,然后找出这两个日期之间的差异。最后,对结果进行过滤,使其只输出第一次和第二次购买之间相隔7天或更短的用户,并使用unique()函数,只获得不同的用户。
Python编码面试题#15:3月份的客户收入
最后一个问题是由Meta/Facebook提出的。
"计算2019年3月每个客户的总收入。只包括在2019年3月活跃的客户。
将收入与客户ID一起输出,并根据收入按降序对结果进行排序。"
该问题的链接:https://platform.stratascratch.com/coding/9782-customer-revenue-in-march?python=1
你需要在列order_date上使用to_datetime()。然后从同一列中提取3月和2019年。最后,按cust_id分组,并对列total_order_cost求和,这将是你要找的收入。使用sort_values()将输出结果按照收入降序排序。
结论
通过向你展示来自顶级公司的15个面试问题,我们涵盖了面试官在测试你的Python技能时感兴趣的五个主要话题。
我们以数据的聚合、分组和排序为开端。然后我们向你展示了如何连接表格和过滤你的输出。最后,你学会了如何处理文本和日期时间数据。
当然,这些并不是你应该知道的唯一概念。但它应该为你准备面试和回答一些更多的Python面试问题打下良好的基础。
要练习更多的Python Pandas函数,请查看我们的文章《数据科学的Python Pandas面试问题》(https://www.stratascratch.com/blog/python-pandas-interview-questions-for-data-science/),它将给你一个关于用Pandas进行数据操作的概述以及在数据科学面试中提出的Pandas问题类型。
该文的作者是 Nate Rosidi, 2022年4月27日发布于KDnuggets。
Nate Rosidi是一名数据科学家,并从事产品策略。他也是教授分析学的兼职教授,并且是StrataScratch的创始人,该平台通过顶级公司的真实面试问题帮助数据科学家准备面试。感兴趣的读者,可以在Twitter、内特-罗西迪是一名数据科学家,并从事产品策略。他也是教授分析学的兼职教授,并且是StrataScratch的创始人,该平台通过顶级公司的真实面试问题帮助数据科学家准备面试。感兴趣的读者,可以在Twitter或LinkedIn上(StrataScratch)与他联系。
推荐书单
最后,附上有关Python的必读书单,轻松搞定有关Python问题。

精彩回顾
关注《Python学研大本营》















 353
353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









