






告诉你从Python转换到SQL时经历的5件最难的事情。
扫码关注《Python学研大本营》,加入读者群,分享更多精彩
有15年分析经验的Josh Berry在从Python转换到SQL时经历了5件最难的事情。
我们中的许多人都体验过在云数据仓库内集中计算所带来的速度和效率的核心力量。虽然这是事实,但我们中的许多人也意识到,像任何东西一样,这种价值也有其自身的缺点。
这种方法的主要缺点之一是,你必须学习和执行不同语言的查询,特别是SQL。虽然编写SQL比建立一个二级基础设施来运行python(在你的笔记本电脑或办公室内的服务器上)更快、更便宜,但它也有许多不同的复杂性,取决于数据分析师想从云仓库中提取什么信息。向云数据仓库的转换增加了复杂的SQL与python的效用。我自己也有过这样的经历,我决定记录下在SQL中学习和执行最痛苦的具体转换,并提供实际所需的SQL来为我的读者减轻一些这种痛苦。

为了帮助你的工作流程,你会注意到我提供了转换执行前后的数据结构的例子,这样你就可以跟随并验证你的工作。我还提供了执行5个最难的转换中的每一个所需的实际SQL。当你的数据发生变化时,你将需要新的SQL来在多个项目中执行转换。我们为每个转换提供了动态SQL的链接,这样你就可以根据需要继续捕获你的分析所需的SQL!
日期骨架(Date Spines)
目前还不清楚日期骨架这个术语的起源,但即使那些不知道这个术语的人也可能熟悉它是什么。
想象一下,你正在分析你的日常销售数据,它看起来像这样。
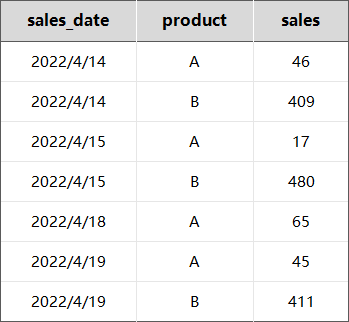
16日和17日没有发生销售,所以行数完全没有。如果我们试图计算平均日销售额,或建立一个时间序列预测模型,这种格式将是一个大问题。我们需要做的是为缺失的那几天插入行。
这里是基本概念:
-
生成或选择唯一的日期
-
生成或选择唯一的产品
-
交叉连接(cartesian product)1和2的所有组合
-
外联#3到你的原始数据
日期骨架的可定制的SQL
WITH GLOBAL_SPINE AS (
SELECT
ROW_NUMBER() OVER (
ORDER BY
NULL
) as INTERVAL_ID,
DATEADD(
'day',
(INTERVAL_ID - 1),
'2020-01-01T00:00' :: timestamp_ntz
) as SPINE_START,
DATEADD(
'day', INTERVAL_ID, '2020-01-01T00:00' :: timestamp_ntz
) as SPINE_END
FROM
TABLE (
GENERATOR(ROWCOUNT => 1097)
)
),
GROUPS AS (
SELECT
product,
MIN(sales_date) AS LOCAL_START,
MAX(sales_date) AS LOCAL_END
FROM
My_First_Table
GROUP BY
product
),
GROUP_SPINE AS (
SELECT
product,
SPINE_START AS GROUP_START,
SPINE_END AS GROUP_END
FROM
GROUPS G CROSS
JOIN LATERAL (
SELECT
SPINE_START,
SPINE_END
FROM
GLOBAL_SPINE S
WHERE
S.SPINE_START >= G.LOCAL_START
)
)
SELECT
G.product AS GROUP_BY_product,
GROUP_START,
GROUP_END,
T.*
FROM
GROUP_SPINE G
LEFT JOIN My_First_Table T ON sales_date >= G.GROUP_START
AND sales_date < G.GROUP_END
AND G.product = T.product;
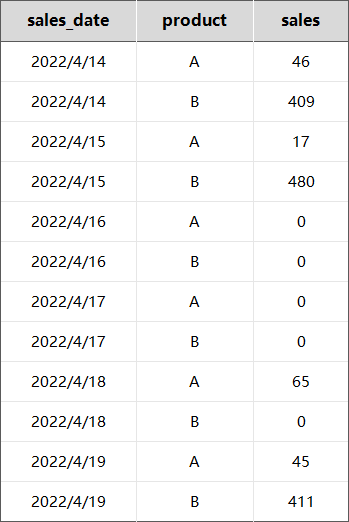
最终的结果将看起来像这样:
枢轴/解除枢轴(Pivot / Unpivot)
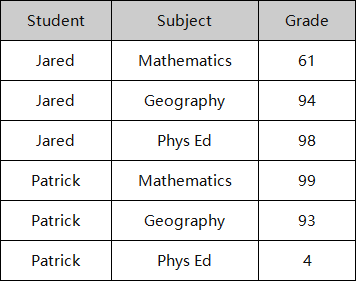
有时,在做分析时,你想重组表。例如,我们可能有一个学生、科目和成绩的列表,但我们想把科目分解到每一列。我们都知道并喜欢Excel,因为它有透视表。但你有没有试过在SQL中这样做?不仅每个数据库在支持PIVOT的方式上有恼人的差异,而且语法也不直观,容易忘记。
之前:
枢轴的可定制的SQL:
SELECT Student, MATHEMATICS, GEOGRAPHY, PHYS_ED
FROM ( SELECT Student, Grade, Subject FROM skool)
PIVOT ( AVG ( Grade ) FOR Subject IN ( 'Mathematics', 'Geography', 'Phys Ed' ) ) as p
( Student, MATHEMATICS, GEOGRAPHY, PHYS_ED );
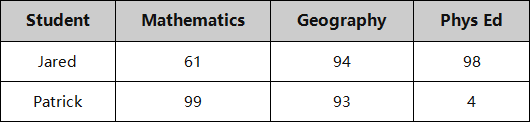
结果:
独热编码(One-hot Encoding)
这个不一定难,但很费时间。大多数数据科学家不考虑在SQL中进行一热编码。虽然语法很简单,但他们宁愿把数据从数据仓库中转移出来,而不是写一个26行CASE语句的繁琐任务。我们不怪他们!
然而,我们建议利用你的数据仓库和它的处理能力。下面是一个使用STATE作为列的例子,来进行独热编码。
之前:
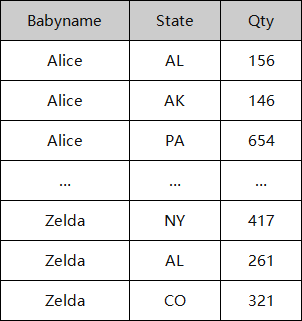
可定制的独热编码SQL:
SELECT *,
CASE WHEN State = 'AL' THEN 1 ELSE 0 END as STATE_AL,
CASE WHEN State = 'AK' THEN 1 ELSE 0 END as STATE_AK,
CASE WHEN State = 'AZ' THEN 1 ELSE 0 END as STATE_AZ,
CASE WHEN State = 'AR' THEN 1 ELSE 0 END as STATE_AR,
CASE WHEN State = 'AS' THEN 1 ELSE 0 END as STATE_AS,
CASE WHEN State = 'CA' THEN 1 ELSE 0 END as STATE_CA,
CASE WHEN State = 'CO' THEN 1 ELSE 0 END as STATE_CO,
CASE WHEN State = 'CT' THEN 1 ELSE 0 END as STATE_CT,
CASE WHEN State = 'DC' THEN 1 ELSE 0 END as STATE_DC,
CASE WHEN State = 'FL' THEN 1 ELSE 0 END as STATE_FL,
CASE WHEN State = 'GA' THEN 1 ELSE 0 END as STATE_GA,
CASE WHEN State = 'HI' THEN 1 ELSE 0 END as STATE_HI,
CASE WHEN State = 'ID' THEN 1 ELSE 0 END as STATE_ID,
CASE WHEN State = 'IL' THEN 1 ELSE 0 END as STATE_IL,
CASE WHEN State = 'IN' THEN 1 ELSE 0 END as STATE_IN,
CASE WHEN State = 'IA' THEN 1 ELSE 0 END as STATE_IA,
CASE WHEN State = 'KS' THEN 1 ELSE 0 END as STATE_KS,
CASE WHEN State = 'KY' THEN 1 ELSE 0 END as STATE_KY,
CASE WHEN State = 'LA' THEN 1 ELSE 0 END as STATE_LA,
CASE WHEN State = 'ME' THEN 1 ELSE 0 END as STATE_ME,
CASE WHEN State = 'MD' THEN 1 ELSE 0 END as STATE_MD,
CASE WHEN State = 'MA' THEN 1 ELSE 0 END as STATE_MA,
CASE WHEN State = 'MI' THEN 1 ELSE 0 END as STATE_MI,
CASE WHEN State = 'MN' THEN 1 ELSE 0 END as STATE_MN,
CASE WHEN State = 'MS' THEN 1 ELSE 0 END as STATE_MS,
CASE WHEN State = 'MO' THEN 1 ELSE 0 END as STATE_MO,
CASE WHEN State = 'MT' THEN 1 ELSE 0 END as STATE_MT,
CASE WHEN State = 'NE' THEN 1 ELSE 0 END as STATE_NE,
CASE WHEN State = 'NV' THEN 1 ELSE 0 END as STATE_NV,
CASE WHEN State = 'NH' THEN 1 ELSE 0 END as STATE_NH,
CASE WHEN State = 'NJ' THEN 1 ELSE 0 END as STATE_NJ,
CASE WHEN State = 'NM' THEN 1 ELSE 0 END as STATE_NM,
CASE WHEN State = 'NY' THEN 1 ELSE 0 END as STATE_NY,
CASE WHEN State = 'NC' THEN 1 ELSE 0 END as STATE_NC,
CASE WHEN State = 'ND' THEN 1 ELSE 0 END as STATE_ND,
CASE WHEN State = 'OH' THEN 1 ELSE 0 END as STATE_OH,
CASE WHEN State = 'OK' THEN 1 ELSE 0 END as STATE_OK,
CASE WHEN State = 'OR' THEN 1 ELSE 0 END as STATE_OR,
CASE WHEN State = 'PA' THEN 1 ELSE 0 END as STATE_PA,
CASE WHEN State = 'RI' THEN 1 ELSE 0 END as STATE_RI,
CASE WHEN State = 'SC' THEN 1 ELSE 0 END as STATE_SC,
CASE WHEN State = 'SD' THEN 1 ELSE 0 END as STATE_SD,
CASE WHEN State = 'TN' THEN 1 ELSE 0 END as STATE_TN,
CASE WHEN State = 'TX' THEN 1 ELSE 0 END as STATE_TX,
CASE WHEN State = 'UT' THEN 1 ELSE 0 END as STATE_UT,
CASE WHEN State = 'VT' THEN 1 ELSE 0 END as STATE_VT,
CASE WHEN State = 'VA' THEN 1 ELSE 0 END as STATE_VA,
CASE WHEN State = 'WA' THEN 1 ELSE 0 END as STATE_WA,
CASE WHEN State = 'WV' THEN 1 ELSE 0 END as STATE_WV,
CASE WHEN State = 'WI' THEN 1 ELSE 0 END as STATE_WI,
CASE WHEN State = 'WY' THEN 1 ELSE 0 END as STATE_WY
FROM BABYTABLE;
结果:

市场篮子分析(Market Basket Analysis)
当进行市场篮子分析或挖掘关联规则时,第一步通常是对数据进行格式化,将每个交易汇总成一条记录。这对你的笔记本电脑来说是个挑战,但你的数据仓库是为了有效地压缩这些数据而设计的。
典型的交易数据:
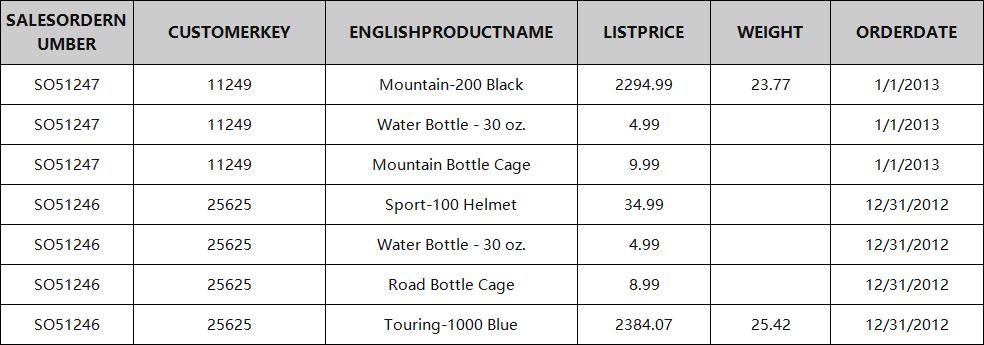
用于市场篮子的可定制的SQL:
WITH order_detail as (
SELECT
SALESORDERNUMBER,
listagg(ENGLISHPRODUCTNAME, ', ') WITHIN group (
order by
ENGLISHPRODUCTNAME
) as ENGLISHPRODUCTNAME_listagg,
COUNT(ENGLISHPRODUCTNAME) as num_products
FROM
transactions
GROUP BY
SALESORDERNUMBER
)
SELECT
ENGLISHPRODUCTNAME_listagg,
count(SALESORDERNUMBER) as NumTransactions
FROM
order_detail
where
num_products > 1
GROUP BY
ENGLISHPRODUCTNAME_listagg
order by
count(SALESORDERNUMBER) desc;
结果:
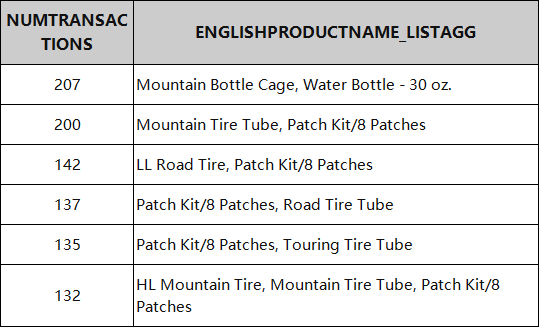
时间序列聚合(Time-Series Aggregations)
时间序列聚合不仅被数据科学家使用,而且也被用于分析。让它们变得困难的是,窗口函数要求数据的格式正确。
例如,如果你想计算过去14天的平均销售金额,窗口函数要求你把所有销售数据分成每天一行。不幸的是,任何曾经与销售数据打过交道的人都知道,这些数据通常存储在交易层面。这就是时间序列汇总的用武之地。你可以在不重新格式化整个数据集的情况下创建汇总的历史指标。如果我们想一次添加多个指标,它也会派上用场。
-
过去14天内的平均销售额
-
过去6个月的最大购买量
-
过去90天内不同产品类型的计数 如果你想使用窗口函数,每个指标都需要通过几个步骤独立建立。
一个更好的处理方法是使用通用表表达式(CTE)来定义每个历史窗口,预先进行汇总。
例如:
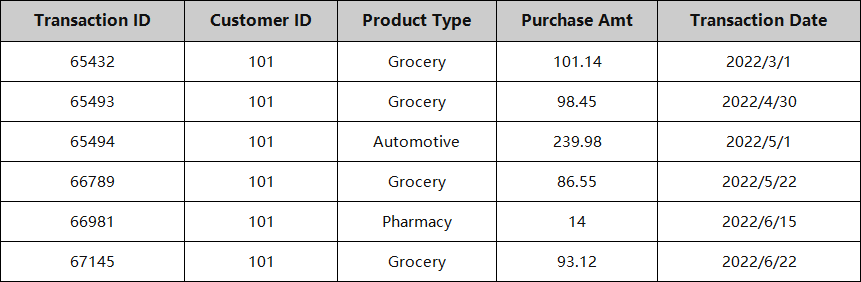
可定制的时间序列聚合SQL:
WITH BASIC_OFFSET_14DAY AS (
SELECT
A.CustomerID,
A.TransactionDate,
AVG(B.PurchaseAmount) as AVG_PURCHASEAMOUNT_PAST14DAY,
MAX(B.PurchaseAmount) as MAX_PURCHASEAMOUNT_PAST14DAY,
COUNT(DISTINCT B.TransactionID) as COUNT_DISTINCT_TRANSACTIONID_PAST14DAY
FROM
My_First_Table A
INNER JOIN My_First_Table B ON A.CustomerID = B.CustomerID
AND 1 = 1
WHERE
B.TransactionDate >= DATEADD(day, -14, A.TransactionDate)
AND B.TransactionDate <= A.TransactionDate
GROUP BY
A.CustomerID,
A.TransactionDate
),
BASIC_OFFSET_90DAY AS (
SELECT
A.CustomerID,
A.TransactionDate,
AVG(B.PurchaseAmount) as AVG_PURCHASEAMOUNT_PAST90DAY,
MAX(B.PurchaseAmount) as MAX_PURCHASEAMOUNT_PAST90DAY,
COUNT(DISTINCT B.TransactionID) as COUNT_DISTINCT_TRANSACTIONID_PAST90DAY
FROM
My_First_Table A
INNER JOIN My_First_Table B ON A.CustomerID = B.CustomerID
AND 1 = 1
WHERE
B.TransactionDate >= DATEADD(day, -90, A.TransactionDate)
AND B.TransactionDate <= A.TransactionDate
GROUP BY
A.CustomerID,
A.TransactionDate
),
BASIC_OFFSET_180DAY AS (
SELECT
A.CustomerID,
A.TransactionDate,
AVG(B.PurchaseAmount) as AVG_PURCHASEAMOUNT_PAST180DAY,
MAX(B.PurchaseAmount) as MAX_PURCHASEAMOUNT_PAST180DAY,
COUNT(DISTINCT B.TransactionID) as COUNT_DISTINCT_TRANSACTIONID_PAST180DAY
FROM
My_First_Table A
INNER JOIN My_First_Table B ON A.CustomerID = B.CustomerID
AND 1 = 1
WHERE
B.TransactionDate >= DATEADD(day, -180, A.TransactionDate)
AND B.TransactionDate <= A.TransactionDate
GROUP BY
A.CustomerID,
A.TransactionDate
)
SELECT
src.*,
BASIC_OFFSET_14DAY.AVG_PURCHASEAMOUNT_PAST14DAY,
BASIC_OFFSET_14DAY.MAX_PURCHASEAMOUNT_PAST14DAY,
BASIC_OFFSET_14DAY.COUNT_DISTINCT_TRANSACTIONID_PAST14DAY,
BASIC_OFFSET_90DAY.AVG_PURCHASEAMOUNT_PAST90DAY,
BASIC_OFFSET_90DAY.MAX_PURCHASEAMOUNT_PAST90DAY,
BASIC_OFFSET_90DAY.COUNT_DISTINCT_TRANSACTIONID_PAST90DAY,
BASIC_OFFSET_180DAY.AVG_PURCHASEAMOUNT_PAST180DAY,
BASIC_OFFSET_180DAY.MAX_PURCHASEAMOUNT_PAST180DAY,
BASIC_OFFSET_180DAY.COUNT_DISTINCT_TRANSACTIONID_PAST180DAY
FROM
My_First_Table src
LEFT OUTER JOIN BASIC_OFFSET_14DAY ON BASIC_OFFSET_14DAY.TransactionDate = src.TransactionDate
AND BASIC_OFFSET_14DAY.CustomerID = src.CustomerID
LEFT OUTER JOIN BASIC_OFFSET_90DAY ON BASIC_OFFSET_90DAY.TransactionDate = src.TransactionDate
AND BASIC_OFFSET_90DAY.CustomerID = src.CustomerID
LEFT OUTER JOIN BASIC_OFFSET_180DAY ON BASIC_OFFSET_180DAY.TransactionDate = src.TransactionDate
AND BASIC_OFFSET_180DAY.CustomerID = src.CustomerID;
结语
我希望这篇文章能帮助阐明数据从业者在现代数据栈中操作时遇到的不同问题。当涉及到查询云仓库的时候,SQL是一把双刃剑。虽然在云数据仓库中集中计算可以提高速度,但有时需要一些额外的SQL技能。我希望这篇文章能帮助回答问题,并提供解决这些问题所需的语法和背景。
参考文章:https://www.kdnuggets.com/2022/07/5-hardest-things-sql.html
推荐书单
《SQL数据分析》

购买链接:https://item.jd.com/12889962.html
理解并发现数据中的模式已是改进业务决策的重要方式之一。如果读者具备SQL方面的基础知识,但却不了解如何从数据中获得业务洞察结果,那么本书将十分适合你。
本书涵盖了读者需要的一切内容,包括SQL基础知识、讲述故事和识别数据中的“趋势”,进而能够通过识别模式和揭示更深入的洞察结果开始研究数据。除此之外,读者还将获得在SQL中使用不同类型数据的经验,包括时间序列、地理空间和文本数据。最后,读者还将了解如何在分析和自动化的帮助下提高SQL的生产效率,从而更快地获得洞察结果。
在阅读完本书后,读者将能够在日常业务场景中高效地使用SQL,并以分析专家的批判性眼光看待数据。
本书详细阐述了与SQL数据分析相关的基本解决方案,主要包括理解和描述数据、数据分析与SQL基础知识、SQL数据准备、数据分析的聚合函数、数据分析的窗口函数、导入和导出数据、利用复杂数据类型进行分析、高性能SQL、利用SQL获取洞察结果等内容。此外,本书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。
本书适合作为高等院校计算机及相关专业的教材和教学参考书,也可作为相关开发人员的自学教材和参考手册。

精彩回顾
扫码关注《Python学研大本营》,加入读者群,分享更多精彩















 889
889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









