






Pandas 文本分析指南
长按关注《Python学研大本营》,加入读者群,分享更多精彩 扫码关注《Python学研大本营》,加入读者群,分享更多精彩
关于如何使用 Pandas 对文本数据执行分析的实践指南。
大多数时候,原始数据的形式使分析变得困难。Python 提供了很多内置函数来操作字符串对象。
我们可以编写我们的函数来操作字符串并使用DataFrame.apply()它们来应用它们,但这有时可能会很慢。
相反,我们可以使用 pandas 函数,本文介绍了一些函数,但如果您需要更多函数,可以查看文档。
内容
-
处理大小写
-
拆分字符串
-
替换字符串
-
连接
-
其他方法:
-
从文本中提取信息
1. 处理大小写
Pandas 提供了几个用于字符串操作的函数:
-
.lower():将 DataFrame 中字符串中的所有大写字符转换为小写,并在结果中返回小写字符串。
-
.upper():将 DataFrame 中字符串中的所有小写字符转换为大写,并在结果中返回大写字符串。
-
.strip():如果字符串的开头或结尾有空格,我们应该使用 strip() 修剪字符串以消除空格或删除 DataFrame 中字符串包含的额外空格。
-
.islower():它检查 Index 中的每个字符串中的所有字符是否为DataFrame小写,并返回一个布尔值。
-
.isupper():它检查索引中每个字符串中的所有字符是否为DataFrame大写,并返回一个布尔值。
-
.isnumeric():它检查 Index 中的每个字符串中的所有字符是否DataFrame都是数字,并返回一个布尔值。
-
.swapcase():它将大小写从下调到上调,反之亦然。
import pandas as pd
import numpy as np
serie = pd.Series(['lev gor\'kov', np.nan, 'brillouin', 'albert einstein', 'carl m. bender'])
print(f'Lowercase all letters:\n{serie.str.lower()}\n')
print(f'Uppercase all letters:\n{serie.str.upper()}\n')
# Convert strings in the Series/Index to be capitalized
print(f'Uppercase the first letter:\n{serie.str.capitalize()}\n')
print(f'Uppercase the first letter of each word:\n{serie.str.title()}\n')
Lowercase all letters:
0 lev gor'kov
1 NaN
2 brillouin
3 albert einstein
4 carl m. bender
dtype: object
Uppercase all letters:
0 LEV GOR'KOV
1 NaN
2 BRILLOUIN
3 ALBERT EINSTEIN
4 CARL M. BENDER
dtype: object
Uppercase the first letter:
0 Lev gor'kov
1 NaN
2 Brillouin
3 Albert einstein
4 Carl m. bender
dtype: object
Uppercase the first letter of each word:
0 Lev Gor'Kov
1 NaN
2 Brillouin
3 Albert Einstein
4 Carl M. Bender
dtype: object
2.拆分字符串
.split(‘ ‘):用给定的模式拆分每个字符串。在下面的例子中,我们有 pandas 系列的物理学家名字,我们想将它们分成名字和姓氏,并很好地格式化它们(给它们命名)。使用expand=True将返回DataFrame很容易与另一个 . 连接的结果DataFrame。
import pandas as pd
import numpy as np
serie = pd.Series(['lev gor\'kov', np.nan, 'brillouin', 'albert einstein', 'carl m. bender'])
print(f'Before Splitting:\n{serie}\n')
new_serie = (
serie.str.title()
.str.split(' ', expand=True, n=1)
.rename(columns={0:'First Name', 1:'Last Name'})
)
print(f'After Splitting:\n{new_serie}')
Before Splitting:
0 lev gor'kov
1 NaN
2 brillouin
3 albert einstein
4 carl m. bender
dtype: object
After Splitting:
First Name Last Name
0 Lev Gor'Kov
1 NaN NaN
2 Brillouin None
3 Albert Einstein
4 Carl M. Bender
3.替换字符串
在处理文本数据时,您通常会希望从文本中删除一些字符或单词。.replace(a,b)用值 b 替换值 a。Dr.在下面的示例中,我们将替换Pr.为空字符串。
如果您要删除或替换的文本不清楚,您可以使用正则表达式。
import pandas as pd
import numpy as np
serie = pd.Series(['lev gor\'kov', np.nan, 'Dr. brillouin', 'Pr. albert einstein', 'carl m. bender'])
print(f'Before Replacing:\n{serie}\n')
new_serie = (
serie.str.replace('Dr.', '', regex=False)
.str.replace('Pr.', '', regex=False)
.str.strip()
.str.title()
.str.split(' ', expand=True, n=1)
.rename(columns={0:'First Name', 1:'Last Name'})
)
print(f'After Replacing:\n{new_serie}')
Before Replacing:
0 lev gor'kov
1 NaN
2 Dr. brillouin
3 Pr. albert einstein
4 carl m. bender
dtype: object
After Replacing:
First Name Last Name
0 Lev Gor'Kov
1 NaN NaN
2 Brillouin None
3 Albert Einstein
4 Carl M. Bender
4.连接
如果您正在处理文本数据,则连接两列是一项常见任务。这可以使用.cat()方法来完成。
-
cat(sep=’ ‘):它将DataFrame索引元素或每个字符串DataFrame与给定的分隔符连接起来。在下面的示例中,我们有两个 pandas 系列(名字和姓氏),我们想将它们连接成一个 Pandas 系列。
import pandas as pd
import numpy as np
s_1 = pd.Series(["Albert", "John", "Robert", np.nan, "Jack"], dtype="string")
s_2 = pd.Series(["Doe", "Piter", "David", "Eden", "Carl"], dtype="string")
# We can specify a separator
print(f'Concatinate and ignore missing values:\n{s_1.str.cat(s_2, sep=" ")}\n')
# Missing values are ignored by default,
# use 'na_rep' to catch them
print()
print(f'Concatinate and replace missing values with "-":\n{s_1.str.cat(s_2, sep=" ", na_rep="-")}\n')
Concatinate and ignore missing values:
0 Albert Doe
1 John Piter
2 Robert David
3 <NA>
4 Jack Carl
dtype: string
Concatinate and replace missing values with "-":
0 Albert Doe
1 John Piter
2 Robert David
3 - Eden
4 Jack Carl
dtype: string
5. 附加方法:
-
.startswith(pattern):如果 DataFrame Index 中的元素或字符串以模式开头,则返回 true。
-
.endswith(pattern):如果 DataFrame 索引中的元素或字符串以模式结尾,则返回 true。
-
.repeat(value):它重复每个元素给定的次数,如下例所示,每个字符串在 DataFrame 中有两次出现。
-
.find(pattern):它返回模式第一次出现的第一个位置。
6. 文本信息提取
在处理数据时,尤其是在 NLP 任务中,您需要对数据进行一些基本的数据分析(查找长文本、干净文本、计算单词……)。
-
.len():在 的帮助下,len()我们可以计算 DataFrame 中每个字符串的长度,如果 DataFrame 中有空数据,则返回NaN.
-
.count(pattern):它返回模式在每个元素中出现的次数,DataFrame如下例所示,它计算每个字符串中的空格DataFrame并返回每个字符串中的单词总数。
-
.findall(pattern):它返回所有出现的模式的列表。在下面的示例中,我们通过了一个正则表达式来查找数据中的时间。
import pandas as pd
time_sentences = ["Saturday: Weekend (Not working day)",
"Sunday: Weekend (Not working day)",
"Monday: The doctor's appointment is at 2:45pm.",
"Tuesday: The dentist's appointment is at 11:30 am.",
"Wednesday: At 7:00pm, there is a basketball game!",
"Thursday: Be back home by 11:15 pm at the latest.",
"Friday: Take the train at 08:10 am, arrive at 09:00am."]
df = pd.DataFrame(time_sentences, columns=['text'])
(
df
.assign(text=df.text.str.lower(),
text_len=df.text.str.len(),
word_count=df.text.str.count(" ") + 1,
weekend=df.text.str.contains("saturday|sunday", case=False),
appointment_time=df.text.str.findall(r"(\d?\d):(\d\d)"),
)
)
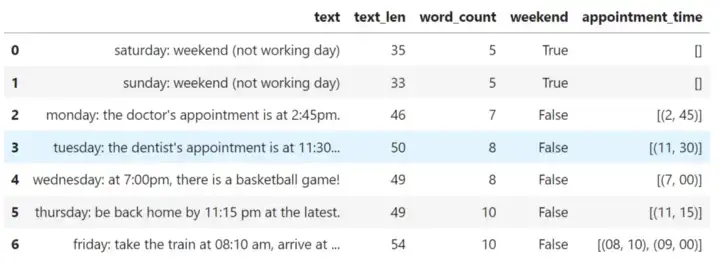
在这里,我们使用链接而不是直接创建新列到DataFrame. 方法链是一种编程风格,它按顺序调用多个方法调用,每个调用对同一对象执行一个操作并返回它。方法链接大大提高了代码的可读性。
结论
-
我们已经介绍了 Pandas 的一些操作文本数据的函数。所有这些都很有用,并且在特定情况下会派上用场。
-
Pandas 是一个强大的数据分析和操作库。它提供了许多函数和方法来处理表格形式的数据。与任何其他工具一样,了解 Pandas 的最佳方式是通过练习。

推荐书单
《PyTorch深度学习简明实战 》

本书针对深度学习及开源框架——PyTorch,采用简明的语言进行知识的讲解,注重实战。全书分为4篇,共19章。深度学习基础篇(第1章~第6章)包括PyTorch简介与安装、机器学习基础与线性回归、张量与数据类型、分类问题与多层感知器、多层感知器模型与模型训练、梯度下降法、反向传播算法与内置优化器。计算机视觉篇(第7章~第14章)包括计算机视觉与卷积神经网络、卷积入门实例、图像读取与模型保存、多分类问题与卷积模型的优化、迁移学习与数据增强、经典网络模型与特征提取、图像定位基础、图像语义分割。自然语言处理和序列篇(第15章~第17章)包括文本分类与词嵌入、循环神经网络与一维卷积神经网络、序列预测实例。生成对抗网络和目标检测篇(第18章~第19章)包括生成对抗网络、目标检测。
本书适合人工智能行业的软件工程师、对人工智能感兴趣的学生学习,同时也可作为深度学习的培训教程。
作者简介:
日月光华:网易云课堂资深讲师,经验丰富的数据科学家和深度学习算法工程师。擅长使用Python编程,编写爬虫并利用Python进行数据分析和可视化。对机器学习和深度学习有深入理解,熟悉常见的深度学习框架( PyTorch、TensorFlow)和模型,有丰富的深度学习、数据分析和爬虫等开发经验,著有畅销书《Python网络爬虫实例教程(视频讲解版)》。
链接:https://item.jd.com/13528847.html
精彩回顾
长按关注《Python学研大本营》
长按二维码,加入Python读者群
扫码关注《Python学研大本营》,加入读者群,分享更多精彩















 475
475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









