






使用Python和Beautiful Soup进行网页抓取的分步指南,学习网页抓取(Web Scraping)的基础知识及其Python实现,并了解Beautiful Soup库的各种方法。
微信搜索关注《Python学研大本营》,加入读者群,分享更多精彩
网页抓取是一种用于从不同网站提取HTML内容的技术。这些网页抓取工具主要是计算机程序,可以使用HTTP协议直接访问网络,并在各种应用中使用这些信息。这些数据是以非结构化的格式获得的,然后在执行多个预处理步骤后被转换成结构化的方式。用户可以将这些数据保存在表格中或通过API导出。

对于小型网页,也可以通过简单地复制和粘贴网页上的数据来手动进行网页抓取。但是,如果需要大规模的、来自多个网页的数据,这种复制和粘贴就不灵了。在这里,自动网页抓取工具应运而生。它们使用智能算法,可以在较短的时间内从众多网页中提取大量的数据。
网页抓取的用途
网页抓取是企业在在线收集和分析信息的一个强大工具。它在各个行业有多种应用。以下是一些例子:
-
市场营销:许多公司利用网页抓取从各种社会媒体网站收集有关其产品或服务的信息,以了解公众情绪。此外,他们还从各种网站上提取电子邮件ID,然后向这些电子邮件ID的所有者批量发送促销电子邮件。
-
内容创作:网页抓取可以从多个来源收集信息,如新闻文章、研究报告和博客文章等。它可以帮助创作者创造高质量的流行内容。
-
价格比较:网页抓取可以用来提取一个特定产品在多个电子商务网站的价格,为用户提供一个公平的价格比较。它还可以帮助公司确定其产品的最佳定价,以便与竞争对手竞争。
-
职位发布:网页抓取也可以用来收集多个招聘门户网站上的各种职位空缺数据,以便这些信息可以帮助许多求职者和招聘者。
现在,我们就使用Python和Beautiful Soup库创建一个简单的网页抓取工具,解析HTML页面并从中提取有用的信息。
代码实现
实现包括四个步骤,如下所示:

图1 教程步骤
-
设置环境。
-
获取HTML。
-
解析HTML。
-
HTML树结构。
设置环境
为该项目创建一个单独的目录,并使用命令提示符安装以下库。先创建一个虚拟环境是比较好的,但也可以全局地安装它们。
$ pip install requests
$ pip install bs4
requests模块从URL中提取HTML内容。它将所有数据以原始格式提取为需要进一步处理的字符串。
bs4是Beautiful Soup模块。它把从request模块获得的原始HTML内容解析成结构良好的格式。
获取HTML
在该目录内创建一个Python文件,并粘贴以下代码:
import requests
url = "https://www.kdnuggets.com/"
res = requests.get(url)
htmlData = res.content
print(htmlData)
输出:

这个脚本将从URLhttps://www.kdnuggets.com/中提取所有的原始HTML内容。这个原始数据包含所有的文本、段落、锚点标签、div等。下一个任务是解析这些数据并分别提取所有的文本和标签。
解析HTML
在这里,Beautiful Soup的作用就体现出来了。它是用来解析和美化上面获得的原始数据的。它为DOM创建了一个树状结构,可以沿着树的分支进行遍历,并能够找到目标标签和对象。
import requests
from bs4 import BeautifulSoup
url = "https://www.kdnuggets.com/"
res = requests.get(url)
htmlData = res.content
parsedData = BeautifulSoup(htmlData, "html.parser")
print(parsedData.prettify())
输出:
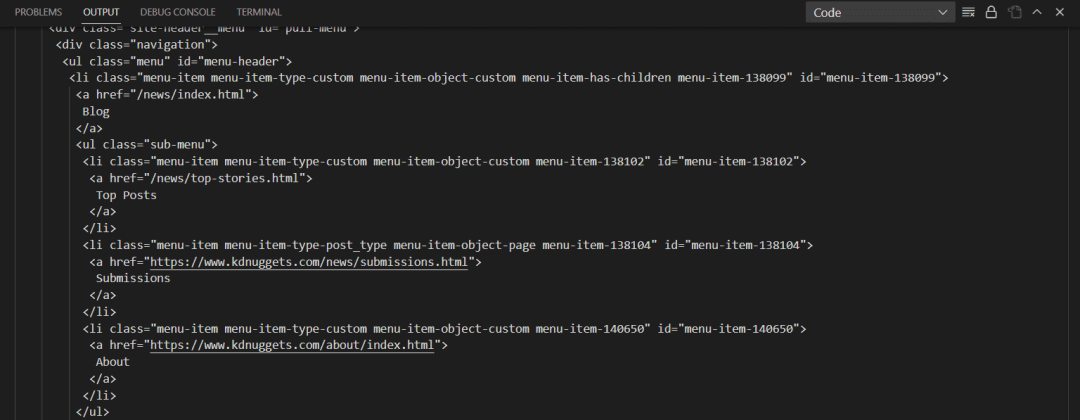
在上面的输出中,可以看到Beautiful Soup以更有条理的格式和适当的缩进来呈现内容。BeautifulSoup()函数需要两个参数,一个是输入的HTML,另一个是解析器。目前使用的是html.parser,但也有其他解析器,比如lxml或html5lib。它们都有各自的优点和缺点。有些有更好的宽松性,而有些则非常快。解析器的选择完全取决于用户的选择。下面是分析器的列表,以及它们的优点和缺点,图2进行了比较。

图2 解析器列表
HTML树形遍历
在本节中,将了解HTML的树状结构,然后使用Beautiful Soup从解析的内容中提取标题、不同的标签、类、列表等。

图 3 HTML树状结构
HTML树代表一个分层的信息视图。根节点是<html>标签,它可以有父节点、子节点和兄弟节点。Head标签和body标签跟在HTML标签之后。head标签包含元数据和标题,body标签包含div、段落、标题等。
当HTML文档通过Beautiful Soup时,它将复杂的HTML内容转换为四个主要的Python对象;这些对象是:
1. BeautifulSoup:
它代表了整个已解析的文档。这是要试图抓取的完整文档。
soup = BeautifulSoup("<h1> Welcome to KDnuggets! </h1>", "html.parser")
print(type(soup))
输出:
<class 'bs4.BeautifulSoup'>
可以看到整个html内容都是一个Beautiful Soup类型的对象。
标记对象对应于HTML文档中的特定标记。如果DOM中存在多个具有相同名称的标签,它可以从整个文档中提取标签并返回第一个找到的标签。
2. Tag:
标签对象对应于HTML文档中的一个特定标签。它可以从整个文档中提取一个标签,如果DOM中存在多个同名的标签,则返回第一个找到的标签。
soup = BeautifulSoup("<h1> Welcome to KDnuggets! </h1>", 'html.parser')
print(type(soup.h1))
输出:
<class 'bs4.element.Tag'>
3. NavigableString:
它包含一个标签内的字符串格式的文本。Beautiful Soup使用NavigableString对象来存储标签的文本。
soup = BeautifulSoup("<h1> Welcome to KDnuggets! </h1>", "html.parser")
print(soup.h1.string)
print(type(soup.h1.string))
输出:
Welcome to KDnuggets!
<class 'bs4.element.NavigableString'>
4. Comments:
它读取标签内存在的HTML注释。它是NavigableString的一种特殊类型。
soup = BeautifulSoup("<h1><!-- This is a comment --></h1>", "html.parser")
print(soup.h1.string)
print(type(soup.h1.string))
输出:
This is a comment
<class 'bs4.element.Comment'>
现在,将从解析的HTML内容中提取标题、不同的标签、类、列表等。
1. 标题
获取HTML页面的标题。
print(parsedData.title)
输出:
<title>Data Science, Machine Learning, AI & Analytics - KDnuggets</title>
或者也可以只输出标题字符串。
print(parsedData.title.string)
输出:
Data Science, Machine Learning, AI & Analytics - KDnuggets
2. 查找和查找所有
当想在HTML内容中搜索一个特定的标签时,这些函数很有用。Find()将只给出该标签的第一次出现,而find_all()将给出该标签的所有出现次数。还可以对它们进行遍历。通过下面的例子来看看。
find():
h2 = parsedData.find('h2')
print(h2)
输出:
<h2>Latest Posts</h2>
find_all():
H2s = parsedData.find_all("h2")
for h2 in H2s:
print(h2)
输出:
<h2>Latest Posts</h2>
<h2>From Our Partners</h2>
<h2>Top Posts Past 30 Days</h2>
<h2>More Recent Posts</h2>
<h2 size="+1">Top Posts Last Week</h2>
这将返回完整的标签,但如果想只输出字符串,可以这样写。
h2 = parsedData.find('h2').text
print(h2)
还可以得到一个特定标签的类、id、类型、href等。例如,获取所有存在的锚点标签的链接。
anchors = parsedData.find_all("a")
for a in anchors:
print(a["href"])
输出:

还可以获得每个div的类。
divs = parsedData.find_all("div")
for div in divs:
print(div["class"])
3. 使用ID和类名查找元素
也可以通过给出一个特定的ID或一个类名来寻找特定的元素。
tags = parsedData.find_all("li", class_="li-has-thumb")
for tag in tags:
print(tag.text)
这将输出属于li-has-thumb类的所有li的文本。但是,如果不确定的话,写标签名称并不总是必要的。也可以这样写。
tags = parsedData.find_all(class_="li-has-thumb")
print(tags)
它将获取所有具有该类名称的标签。
现在将讨论Beautiful Soup的一些更有趣的用法。
Beautiful Soup的其他一些用法
在本节中,将讨论Beautiful Soup的一些其他功能,这些功能将使工作更容易和更快。
1. select()
select()函数允许根据CSS选择器来寻找特定的标签。CSS选择器是可以根据某些HTML标签的类别、id、属性等选择它们的一种模式。
下面是查找alt属性以KDnuggets开头的图片的例子。
data = parsedData.select("img[alt*=KDnuggets]")
print(data)
输出:

2. parent
该属性返回给定标签的父级。
tag = parsedData.find('p')
print(tag.parent)
3. contents
该属性返回所选标签的内容。
tag = parsedData.find('p')
print(tag.contents)
4. attrs
该属性用于在字典中获取一个标签的属性。
tag = parsedData.find('a')
print(tag.attrs)
5. has_attr()
此方法检查一个标签是否有特定的属性。
tag = parsedData.find('a')
print(tag.has_attr('href'))
如果该属性存在,它将返回True,否则返回False。
6. find_next()
此方法在一个给定的标签之后找到下一个标签。它采用接下来需要查找的输入标签的名称。
first_anchor = parsedData.find("a")
second_anchor = first_anchor.find_next("a")
print(second_anchor)
7. find_previous()
此方法用于查找给定标签的前一个标签。它采用接下来需要查找的输入标签的名称。
second_anchor = parsedData.find_all('a')[1]
first_anchor = second_anchor.find_previous('a')
print(first_anchor)
它将再次输出第一个锚点标签。
还有许多其他用法,可以试一试。可参考Beautiful Soup的文档(https://www.crummy.com/software/BeautifulSoup/bs4/doc/)。
总结
本文主要讨论了网页抓取、它的用途以及它的Python和Beautiful Soup实现。
推荐书单
《Python网络爬虫从入门到精通》
《Python网络爬虫从入门到精通》从初学者角度出发,通过通俗易懂的语言、丰富多彩的实例,详细介绍了使用Python实现网络爬虫开发应该掌握的技术。全书共分19章,内容包括初识网络爬虫、了解Web前端、请求模块urllib、请求模块urllib3、请求模块requests、高级网络请求模块、正则表达式、XPath解析、解析数据的BeautifulSoup、爬取动态渲染的信息、多线程与多进程爬虫、数据处理、数据存储、数据可视化、App抓包工具、识别验证码、Scrapy爬虫框架、Scrapy_Redis分布式爬虫、数据侦探。书中所有知识都结合具体实例进行介绍,涉及的程序代码给出了详细的注释,读者可轻松领会网络爬虫程序开发的精髓,快速提高开发技能。

精彩回顾
《精美绝伦,用Stable Diffusion和Dreambooth为宠物创建艺术照(下)》
《精美绝伦,用Stable Diffusion和Dreambooth为宠物创建艺术照(上)》
《知识图谱并不难,用Neo4j和Python打造社交图谱(下)》
《知识图谱并不难,用Neo4j和Python打造社交图谱(中)》
微信搜索关注《Python学研大本营》,加入读者群
访问【IT今日热榜】,发现每日技术热点














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









