







 本文探讨了在大型有向图中删除边的子集来减小对弱连通性影响的方法,通过将图转为无向图并计算edge_betweenness(中介中心性),着重于保留连接性。通过实例展示了如何选择k值进行高效计算,并解释了删除高中介性边对图结构的影响。
本文探讨了在大型有向图中删除边的子集来减小对弱连通性影响的方法,通过将图转为无向图并计算edge_betweenness(中介中心性),着重于保留连接性。通过实例展示了如何选择k值进行高效计算,并解释了删除高中介性边对图结构的影响。
背景
最近需要在一个节点数300+万,边400+万的有向图中删除某一些边的子集,但是又需要尽量减少对图的弱连通性的影响。最后的解决方案中一部分是,先将有向图转为无向图,计算边的betweenness,有时也被翻译成中介中心性,然后删除中介中心性较低的边。
定义
betweenness顾名思义,是它作为中介的一种度量。具体是在所有最短路径中,此边通过的最短路径所占的比例。因此betweenness越高,其中介性越高。
c
B
(
e
)
=
∑
s
,
t
∈
e
σ
(
s
,
t
∣
v
)
σ
(
s
,
t
)
c_B(e) =\sum_{s,t \in e } \frac{\sigma(s, t|v)}{\sigma(s, t)}
cB(e)=s,t∈e∑σ(s,t)σ(s,t∣v)
我认为删除中介性更高的边,对图的连通性影响性更大。
实例
建图
import networkx as nx
G = nx.Graph()
G.add_edges_from([[0, 1], [0, 2], [1, 2], [2,3], [3,4], [4,5], [3,5]])
nx.draw(G, with_labels=True)
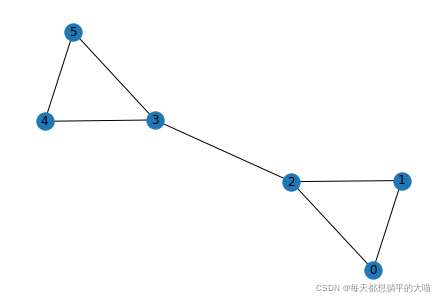
计算
nx.edge_betweenness_centrality(G, k=None)
>>> {(0, 1): 0.06666666666666667,
(0, 2): 0.26666666666666666,
(1, 2): 0.26666666666666666,
(2, 3): 0.6,
(3, 4): 0.26666666666666666,
(3, 5): 0.26666666666666666,
(4, 5): 0.06666666666666667}
可以看到(2, 3)的中介性最高,(0, 1) (4, 5)的中介性最低,其余几条边的中介性相同,跟预期相同。
大规模图上的边介数
既然edge_betweenness的计算涉及了最短路径,因此计算复杂度一定不低,因此在大规模图上有实现难度。不过networkx的edge_betweenness提供了一个k参数,选择sample的节点数目。k越大,其计算的介数准确度越高。
在我的大规模图上,我选择了10,计算时长在一个小时左右。根据返回的edge_betweenness删除边后,图的连通性的影响在可接受范围内。
另外需要注意的是,当设置了k后,返回的edge_betweenness不一定包括所有的边。这里面的具体原理还需要看代码。不过我个人理解,缺失的边的中介性是很低的。

















 1329
1329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









