







在物理上,如果瞬时频率有意义,那么函数必须是对称的,局部均值为零,并且具有相同的过零点和极值点数目。在此基础上,NordneE.Huang等人提出了本征模函数(Intrinsic Mode Function,简称IMF)的概念。本征模函数任意一点的瞬时频率都是有意义的。Huang等人认为任何信号都是由若干本征模函数组成,任何时候,一个信号都可以包含若干个本征模函数,如果本征模函数之间相互重叠,便形成复合信号。EMD分解的目的就是为了获取本征模函数,然后再对各本征模函数进行希尔伯特变换,得到希尔伯特谱。
Huang认为,一个本征模函数必须满足以下两个条件:
⑴l函数在整个时间范围内,局部极值点和过零点的数目必须相等,或最多相差一个;
⑵在任意时刻点,局部最大值的包络(上包络线)和局部最小值的包络(下包络线) 平均必须为零。
第一个条件是很明显的,它与传统的平稳高斯信号的窄带要求类似。对于第二个条件,是一个新的概念,它把经典的全局性要求修改为局部性要求,使瞬时频率不再受不对称波形所形成的不必要的波动所影响。实际上,这个条件应为“数据的局部均值是零”。但是对于非平稳数据来说,计算局部均值涉及到“局部时间尺度”的概念,而这是很难定义的。因此,在第二个条件中使用了局部极大值包络和局部极小值包络的平均为零来代替,使信号的波形局部对称。Huang等人研究表明,在一般情况下,使用这种代替,瞬时频率还是符合所研究系统的物理意义。本征模函数表征了数据的内在的振动模式。由本征模函数的定义可知,由过零点所定义的本征模函数的每一个振动周期,只有一个振动模式,没有其他复杂的奇波;一个本征模函数没有约束为是一个窄带信号,并且可以是频率和幅值的调制,还可以是非稳态的;单由频率或单由幅值调制的信号也可成为本征模函数。
EMD方法的分解过程
由于大多数所有要分析的数据都不是本征模函数,在任意时间点上,数据可能包含多个波动模式,这就是简单的希尔伯特变换不能完全表征一般数据的频率特性的原因。于是需要对原数据进行EMD分解来获得本征模函数。
EMD分解方法是基于以下假设条件:⑴数据至少有两个极值,一个最大值和一个最小值;⑵数据的局部时域特性是由极值点间的时间尺度唯一确定;⑶如果数据没有极值点但有拐点,则可以通过对数据微分一次或多次求得极值,然后再通过积分来获得分解结果。这种方法的本质是通过数据的特征时间尺度来获得本征波动模式,然后分解数据。这种分解过程可以形象地称之为“筛选(sifting)”过程。
分解过程是:找出原数据序列X(t)所有的极大值点并用三次样条插值函数拟合形成原数据的上包络线;同样,找出所有的极小值点,并将所有的极小值点通过三次样条插值函数拟合形成数据的下包络线,上包络线和下包络线的均值记作ml,将原数据序列X(t)减去该平均包络ml,得到一个新的数据序列h,:
X(t)-ml=hl
由原数据减去包络平均后的新数据,若还存在负的局部极大值和正的局部极小值,说明这还不是一个本征模函数,需要继续进行“筛选”。
经济学论文举例
Oladosu G. Identifying the oil price–macroeconomy relationship: An empirical mode decomposition analysis of US data[J]. Energy Policy, 2009, 37(12): 5417-5426.

图1 Energy Policy论文
选择上面这篇 Energy Policy上的论文,是采用EMD方法对WTI石油价格和美国的Real GDP数据的分析,来Identifying石油价格和宏观之间的Relationship
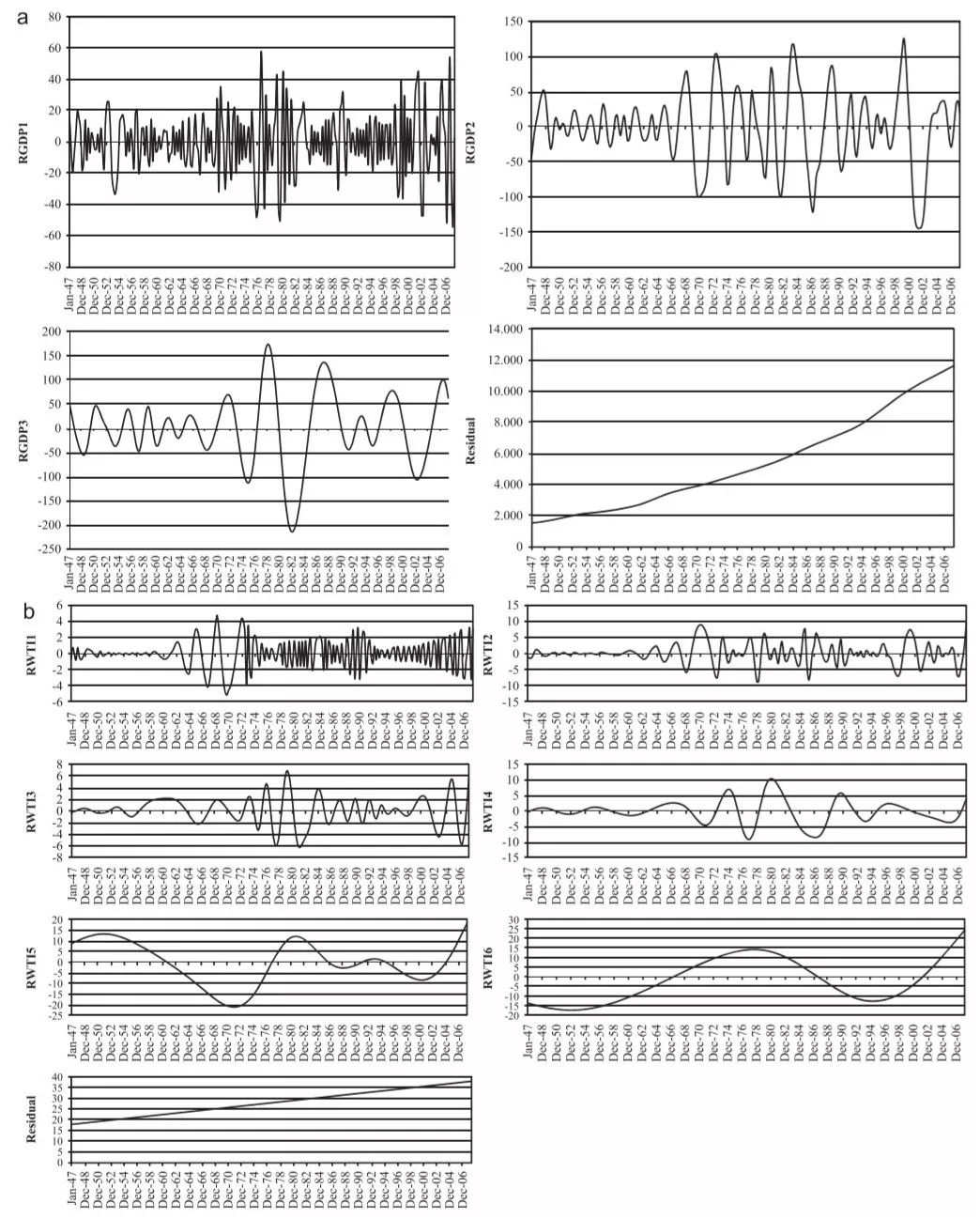
图2 (a) RGDP的非本征模态函数分解
(b)实际WTI油价(RWTI)的内在模态函数分解
表1 RWTI和RGDP固有模态函数的描述性统计
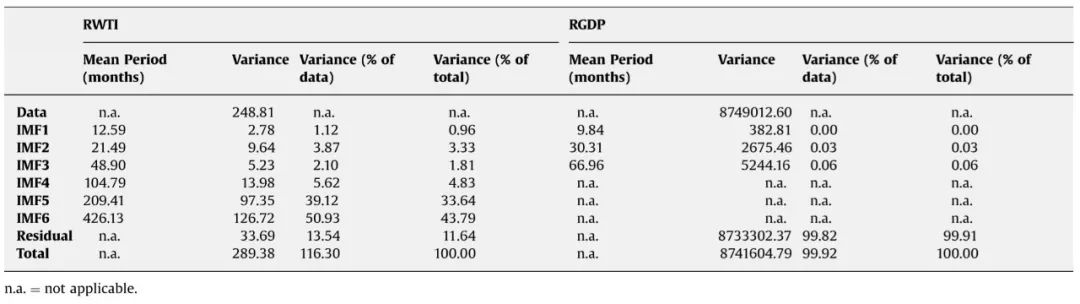
表⒉ WTI与RGDP周期成分的相关分析结果
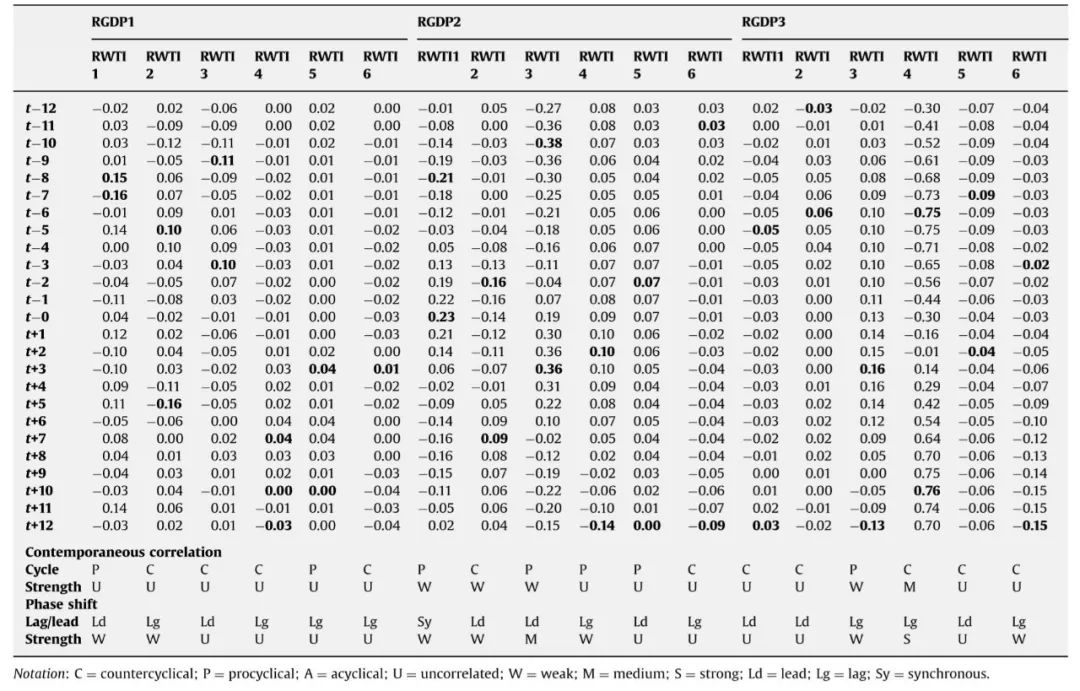
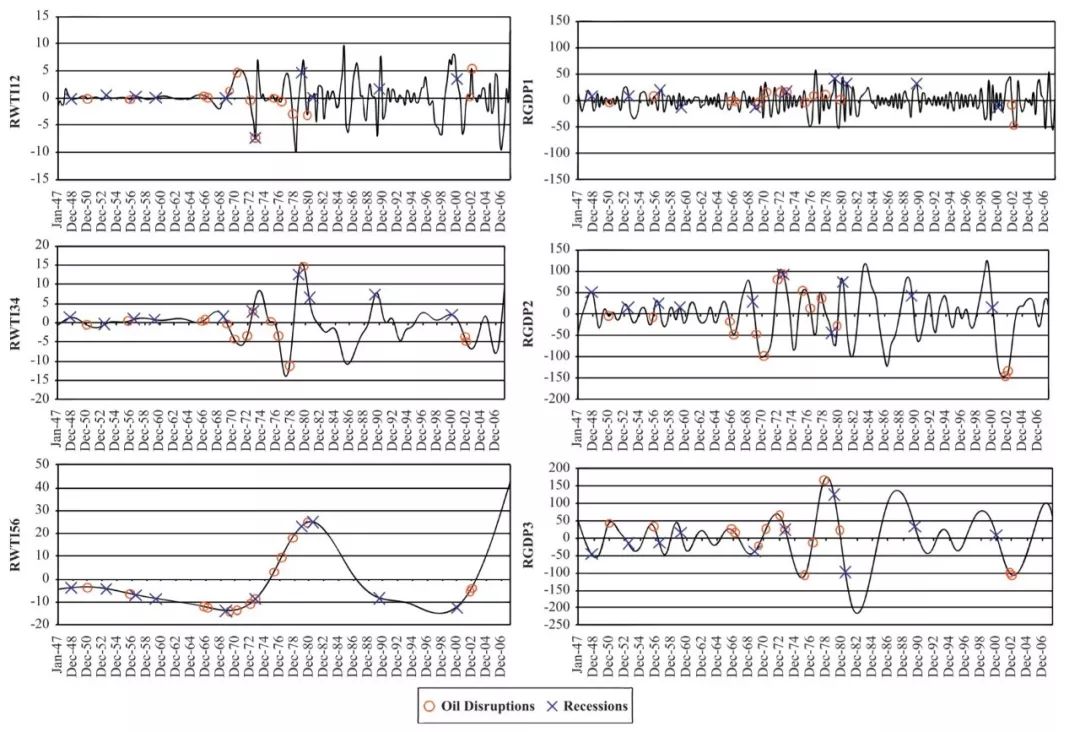
图3 加总RWTI和原始RDP周期成分
表3 RWTI和RGDP加总周期成分与的相关分析结果
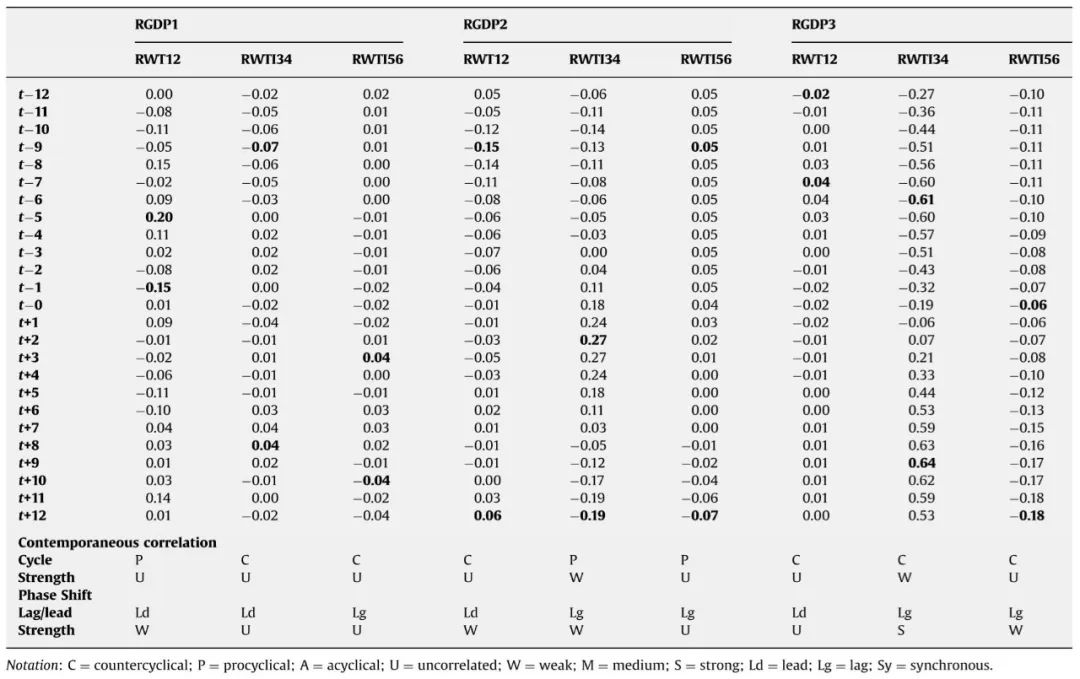
表3 石油供应中断和衰退的开始日期和结束日期
Matlab编程实例
采用的数据是个Noisy序列,你可以理解成一个股票收等等,为了偷懒,本尊用Excel绘制了一副丑丑的图
然后就是执行EMD.m主程序文件(源代码)
%EMD computes Empirical Mode Decomposition
%
%
% Syntax
%
%
% IMF = EMD(X)
% IMF = EMD(X,...,'Option_name',Option_value,...)
% IMF = EMD(X,OPTS)
% [IMF,ORT,NB_ITERATIONS] = EMD(...)
%
%
% Description
%
%
% IMF = EMD(X) where X is a real vector computes the Empirical Mode
% Decomposition [1] of X, resulting in a matrix IMF containing 1 IMF per row, the
% last one being the residue. The default stopping criterion is the one proposed
% in [2]:
%
% at each point, mean_amplitude < THRESHOLD2*envelope_amplitude
% &
% mean of boolean array {(mean_amplitude)/(envelope_amplitude) > THRESHOLD} < TOLERANCE
% &
% |#zeros-#extrema|<=1
%
% where mean_amplitude = abs(envelope_max+envelope_min)/2
% and envelope_amplitude = abs(envelope_max-envelope_min)/2
%
% IMF = EMD(X) where X is a complex vector computes Bivariate Empirical Mode
% Decomposition [3] of X, resulting in a matrix IMF containing 1 IMF per row, the
% last one being the residue. The default stopping criterion is similar to the
% one proposed in [2]:
%
% at each point, mean_amplitude < THRESHOLD2*envelope_amplitude
% &
% mean of boolean array {(mean_amplitude)/(envelope_amplitude) > THRESHOLD} < TOLERANCE
%
% where mean_amplitude and envelope_amplitude have definitions similar to the
% real case
%
% IMF = EMD(X,...,'Option_name',Option_value,...) sets options Option_name to
% the specified Option_value (see Options)
%
% IMF = EMD(X,OPTS) is equivalent to the above syntax provided OPTS is a struct
% object with field names corresponding to option names and field values being the
% associated values
%
% [IMF,ORT,NB_ITERATIONS] = EMD(...) returns an index of orthogonality
% ________
% _ |IMF(i,:).*IMF(j,:)|
% ORT = \ _____________________
% /
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 506
506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









