






上期讲解了语义分割模型的基本架构和常用数据集,这期就讲解一下语义分割数据集的制作,追下去吧~
图像分割系列 <-> 语义分割mp.weixin.qq.com制作总体步骤:
1.使用lableme对图片数据进行标注,生成对应图片的x.json文件。
2.执行lableme下的内置函数labelme_json_to_dataset,依次手动生成图片对应的x_json文件(或者使用代码一次性处理生成)。
3.对第二步生成文件夹中的文件进行处理,生成语义图片label.png
4.将语义图片转换为类别灰度图图片-最终训练标签文件。
一、文件目录结构:
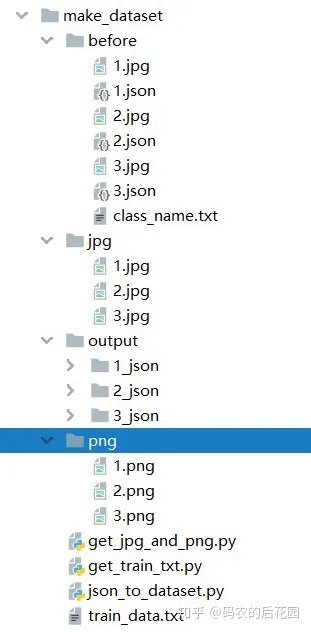
二、正式开始制作
第一步:标注软件的安装
1.Anaconda Prompt中创建一个环境conda create --name=labelImg python=3.6
2.激活进入刚建立的新环境,conda activate labelImg
3.安装界面支持pyqt5包pip install pyqt5 -i https://pypi.douban.com/simple/
4.下载安装labelmepip install labelme -i https://pypi.douban.com/simple/
5.输入命令labelme,就可以启动程序进行数据标注

第二步:进行标注A.
单类别标注 - 即每一张图片上只有一个目标
【1】在命令行中输入命令 labelme,打开标注界面,然后打开要标注的图片所在的文件夹进行标注Opendir “”Test_Image“” ->Create polygons ->Save->Next Image
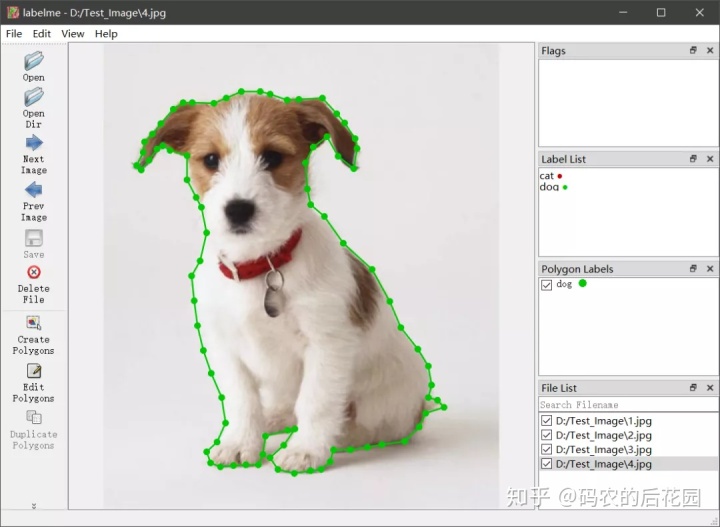
【2】所有图片标注完之后,标注文件以x.json形式文件进行保存,制作完成后放在目录的before文件夹下。
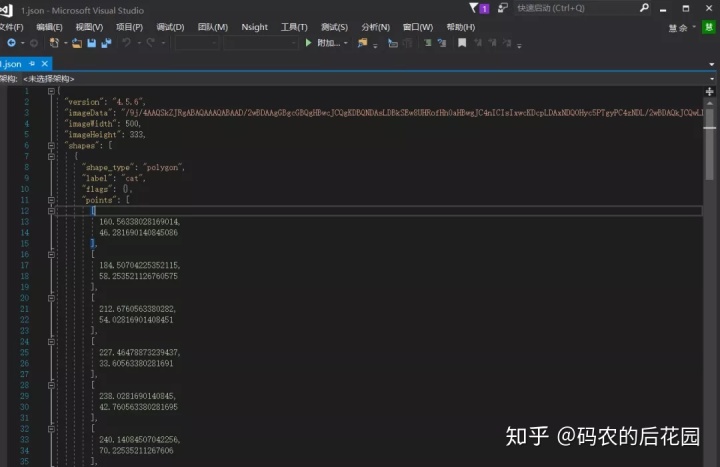
用VS2017可查看Json文件内容,包含信息为我们标注区域内每一个像素点的数据
【3】利用labelme的自带函数labelme_json_to_dataset手动依次将每个json文件格式转换为语义图片的数据。
1.cd 到json文件所在的地方:cmd D:Test_Image
2.查看当前labelme安装所在的环境label并激活
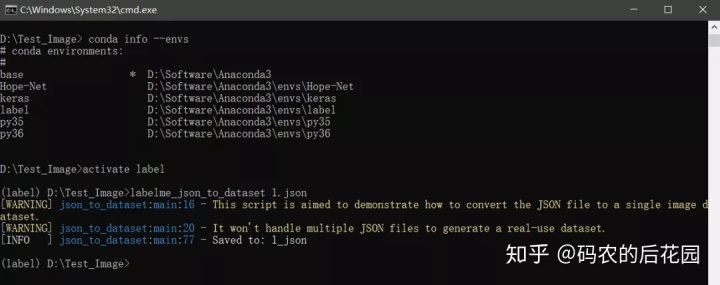
3.利用labelme_json_to_dataset手动依次对每张图片的标注文件x.json格式依次进行处理, 生成得到x_json文件即每张图片的对应的语义图片 - 局部类别标签(这个过程需要手动对每一张图片的x.json文件进行处理,比较麻烦,可以写代码直接一次性转换)
命令:labelme_json_to_data [ x.json ] -> labelme标注生成的json文件名
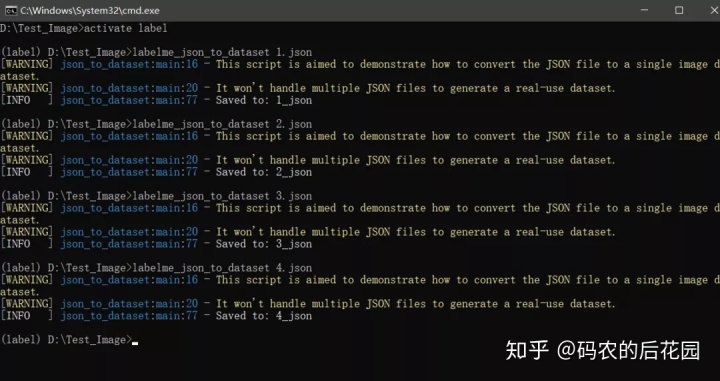
得到每张图片的x.json文件对应的局部类别标签保存在每个x_json文件中,如下所示:
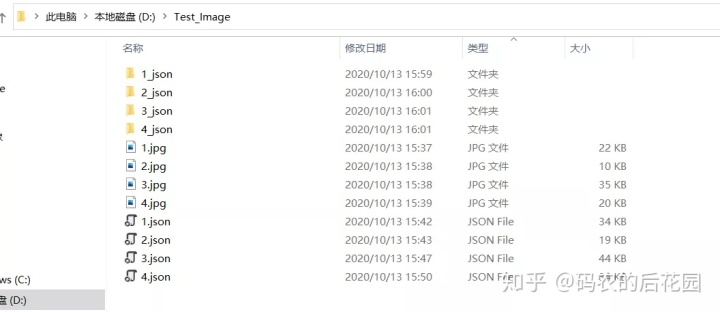
每张图片局部类别标签内容 x_json文件中的内容:
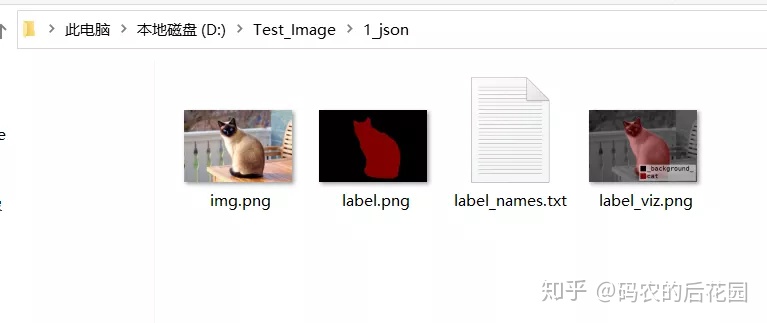
注解:
img.png: 对应的局部的jpg原图文件,训练时要用label.png: 标注语义图像,训练时要用label_names.txt: 在这张图像上目标分类名称label_viz.png: 标签可视化,用于让我们确认是否标记正确
代码一次性转换:json_to_dataset.py
会生成和上述x_json文件下一模一样的文件内容
import 我们得到了每张图片所对应的局部语义类别标签之后(每一张图片,灰度类别转换后,属于标记目标,如猫,其所属区域像素点的值均为1,不属于标记目标的图片区域(背景)像素点值为0)。
如果数据集新增图片,这张图片上也只有一个目标狗,为了将目标狗这个类别加入到训练集中,则需要将狗这个局部类别标签进行转换为全局类别标签,即在训练时,背景的像素点值为0,猫的像素点值为1,狗的像素点值为2,依次类推).
【4】局部类别标签—>全局类别标签(类别灰度转换)
将得到的每张图片所对应的局部训练标签文件label.png转换为全局训练标签文件,放在了png文件夹下,这个过程中还涉及了类别灰度化操作。
进行get_jpg_and_png.py操作即可得到每张图片的全局类别标签文件和类别灰度转换,即一张图片中背景的像素点的值为0,若目标是猫,则其像素点的值为1,若目标是狗,则其像素点的值为2。
这里最终的全局训练标签是灰度图,是单通道的,像素点的取值范围为0~255,这里全黑是因为,像素点值为1和2,在灰度图中,值比较小,区别比较小,所以显示都是黑的。
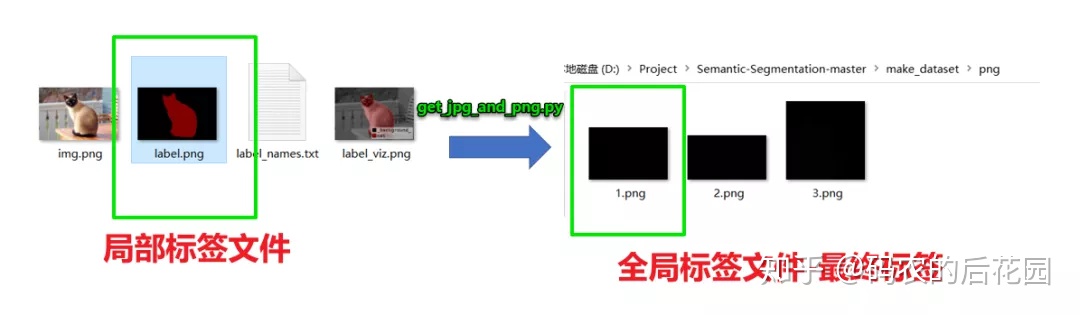
类别灰度图图片:
我们可以看到,猫这张图片对应的类别灰度图图片所在区域的像素点的值均为 1,而背景所对应的像素点的值均为0
1. 这里我们需要首先新建一个包含全局类名称的class_name.txt

2.借助class_name.txt文件,将图片局部类别标签文件转换成全局类别标签文件,转换代码:get_jpg_and_png.py
import os
from PIL import Image
import numpy as np
def main():
# 读取原文件夹
count = os.listdir("./before/")
for i in range(0, len(count)):
# 如果里的文件以jpg结尾
# 则寻找它对应的png
if count[i].endswith("jpg"):
path = os.path.join("./before", count[i])
img = Image.open(path)
img.save(os.path.join("./jpg", count[i]))
# 找到对应的png
path = "./output/" + count[i].split(".")[0] + "_json/label.png"
img = Image.open(path)
# 找到全局的类
class_txt = open("./before/class_name.txt","r")
class_name = class_txt.read().splitlines()
# ["bk","cat","dog"] 全局的类
# 打开x_json文件里面存在的类,称其为局部类
with open("./output/" + count[i].split(".")[0] + "_json/label_names.txt","r") as f:
names = f.read().splitlines()
# ["bk","dog"] 局部的类
# 新建一张空白图片
new = Image.new("RGB",[np.shape(img)[1],np.shape(img)[0]])
# 找到局部的类在全局中的类的序号
for name in names:
# index_json是x_json文件里存在的类label_names.txt,局部类
index_json = names.index(name)
# index_all是全局的类,
index_all = class_name.index(name)
# 将局部类转换成为全局类
# 将原图img中像素点的值为index_json的像素点乘以其在全局中的像素点的所对应的类的序号 得到 其实际在数据集中像素点的值
# 比如dog,在局部类(output/x_json/label_names)中它的序号为1,dog在原图中的像素点的值也为1.
# 但是在全局的类(before/classes.txt)中其对应的序号为2,所以在新的图片中要将局部类的像素点的值*全局类的序号,从而得到标签文件
new = new + np.expand_dims(index_all*(np.array(img) == index_json),-1)
new = Image.fromarray(np.uint8(new))
# 将转变后的得到的新的最终的标签图片保存到make_dataset/png文件夹下
new.save(os.path.join("./png", count[i].replace("jpg","png")))
# 找到新的标签文件中像素点值的最大值和最小值,最大值为像素点对应的类在class_name.txt中的序号,最小值为背景,即0
print(np.max(new),np.min(new))
if __name__ == '__main__':
main()3.最后我们利用get_train_txt.py对上述得到的jpg文件下和png文件下的内容进行数据集原图和标签的一一对应的关系,将其train_data.txt中
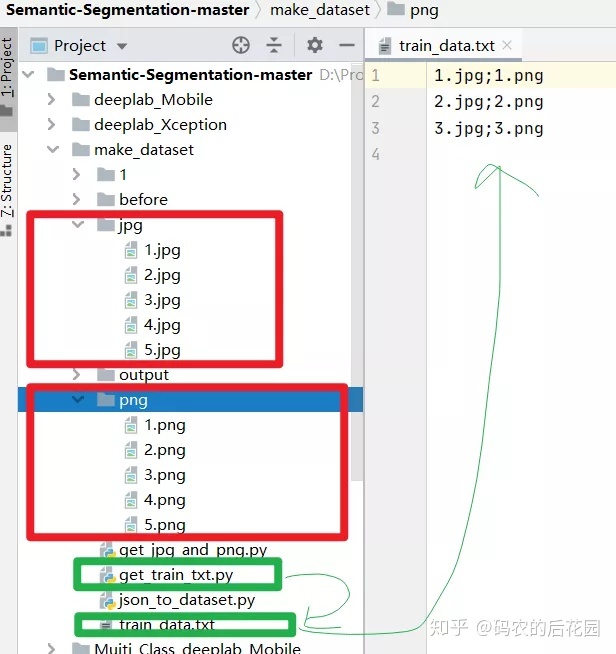
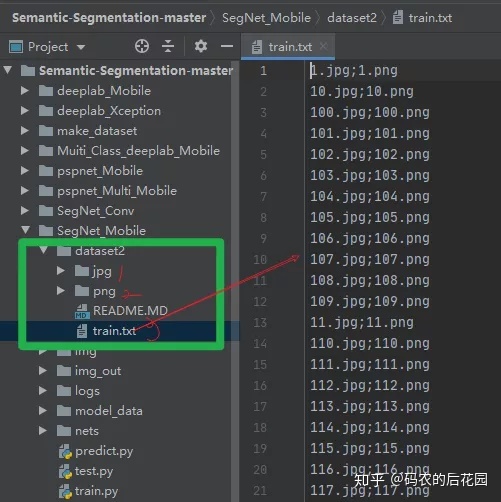
【4】最终训练模型数据集的样式:jpg文件夹(原图)+png文件夹(全局灰度类别标签) + train_data.txt(原图和标签的对应关系),放入模型当中即可训练了,下期讲解基于MobileNet的SegNet的语义分割模型。
B.多类别标注- 即一张图片上有多个目标
标注过程和上述类似,对图片上的多目标依次进行标注,生成的x_json文件内容和单目标标注一样。


新建一个包含全局类名称的class_name.txt,然后类别灰度转换, 利用get_jpg_and_png.py进行转换,我们可以看到猫对应的区域像素点的值为1,对应类别1,同理狗对应区域的像素点的值为2,对应类别2,而背景区域像素点的值为0.
进行类别灰度转换之后,就可以进行模型训练了。
最终训练模型数据集的样式:jpg文件夹(原图)+png文件夹(全局灰度类别标签) + train_data.txt(原图和标签的对应关系),放入模型当中即可训练了,下期讲解基于MobileNet的SegNet的语义分割模型。
好啦,数据标注的部分到这里就结束了,所有处理文件代码,回复关键字:项目实战,即可获取。
新教程之图像分割系列mp.weixin.qq.com














 9507
9507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









