







为什么有的模型既能做图像分类又能做语义分割?
1.输入和输出:语义分割模型的输入是一张图片,而输出是一个像素级别的标签,指示每个像素属于哪个类别。因此,输入和输出张量的大小需要进行相应调整。
2.网络结构:分类模型的典型结构是一组全连接层,它们将输入转换为一组类别概率。在语义分割模型中,我们需要考虑更多的卷积和上采样层。例如,可以使用卷积神经网络(CNN)中的编码器-解码器结构或U-Net架构。
3.损失函数:分类任务通常使用交叉熵作为损失函数,但是在语义分割中,需要使用像像素级别的损失函数,如交叉熵损失函数和Dice Loss,来确保像素级别的准确性。
4.数据增强:由于语义分割任务需要更多的数据量,因此需要使用数据增强技术,如随机翻转、旋转和缩放等来增加数据的数量,同时保持标签信息的一致性。
5.训练策略:在训练语义分割模型时,可以使用像分段训练和迁移学习这样的技术来加速模型的训练。其中分段训练是将整个训练过程分为多个阶段,每个阶段都使用不同的学习率和数据增强技术。而迁移学习是利用预先训练好的模型,从而快速训练语义分割模型。
语义分割网络在最后做了什么?
前面都是在提取特征,不同的就是下游任务
下面是一个语义分割的标签图像
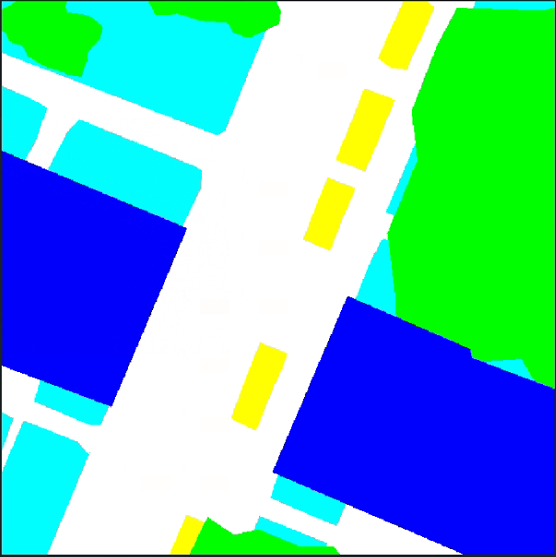
语义分割标签图像,相同颜色(像素值)的像素点代表的是同一类物体。
图中是Potsdam数据集的标签图,有6个类别,
现在假设像我们这个标签图像简单一些,只有3个类别,我们需要分割出来图片中的猫和狗,那对我们的语义分割任务来说就是总共要分3类:0 背景;1 猫;2 狗
因此,我们需要创建一个[Height, Width, N_classes]数组来表示每一个像素点的类别;
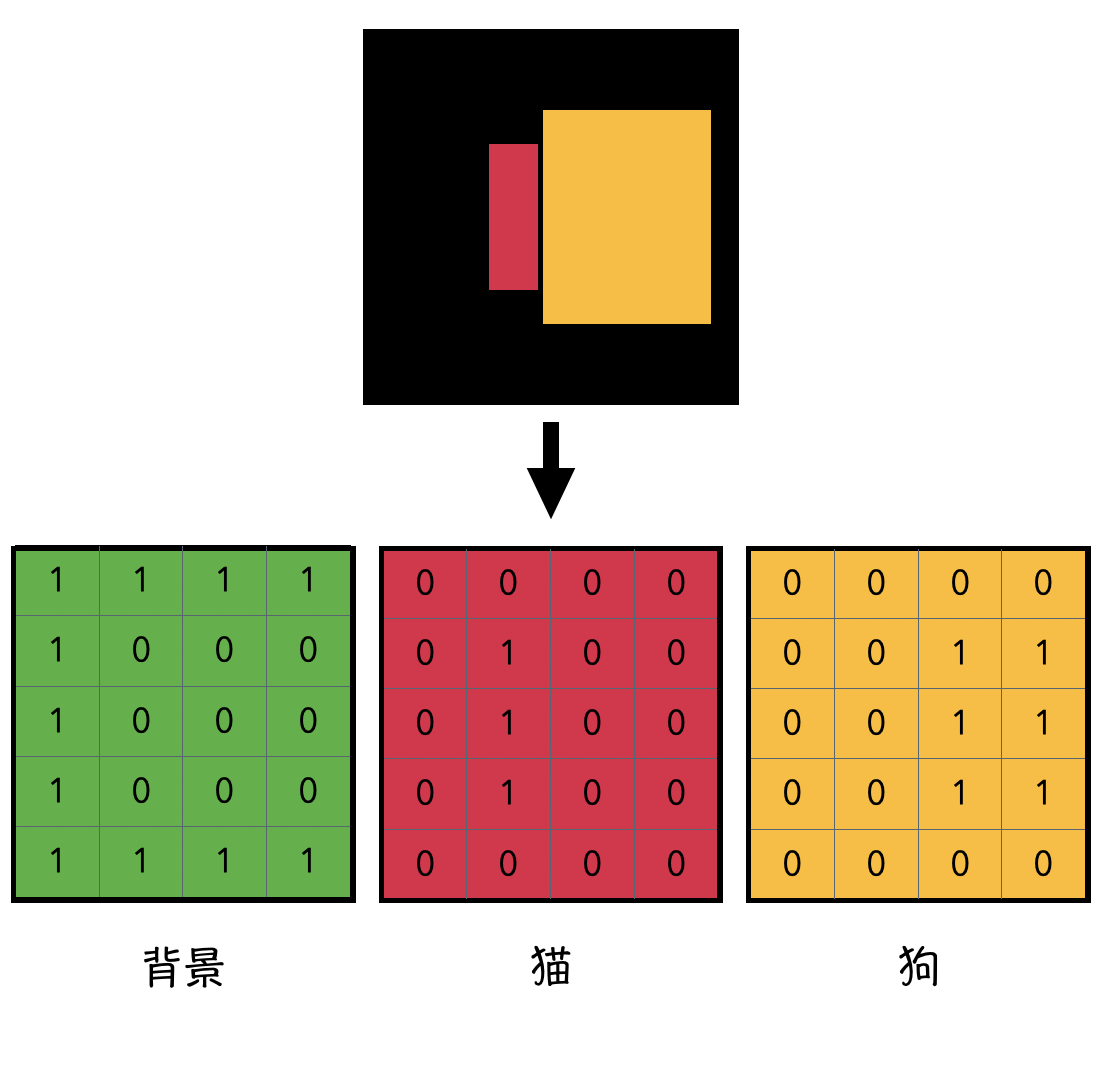
在这里 是一个[4,5,3]的数组
label[0, 0] = [1, 0, 0] 说明[0, 0]位置是背景
label[1, 1] = [0, 1, 0]说明[1, 1]这个像素点属于猫。
- 特别的,加粗的1是一个概率,经过softmax可以确定值大的为所属类别
[1, 0, 0],
[1, 0, 0],
[1, 0, 0],
[1, 0, 0],
[0, 1, 0],
[0, 0, 1],
[0, 0, 1],
...
]
如这样的结果,每一行代表一个像素,每一列代表一个类别,每个元素表示该像素属于对应类别的概率
## 实际上像这样
[[0.4, 0.3, 0.3],
[0.7, 0.2, 0.1],
[0.8, 0.2, 0.0],
[0.8, 0.1, 0.1],
...
]
将我们处理之后的label和预测得到的结果传给我们的损失函数就能计算出loss了,这样我们就实现了像素级的分类(即语义分割)
像素级分类代码
import torch
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self, n_classes):
super(MyModel, self).__init__()
self.conv = nn.Conv2d(in_channels=..., out_channels=n_classes, kernel_size=(1,1))
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = self.conv(x)
# 将输出张量的形状从 [batch_size, n_classes, h, w] 变为 [batch_size, n_classes, h*w]
x = x.view(x.size(0), -1, x.size(-1))
x = self.softmax(x)
return x
- 解释:
这个PyTorch实现中,我们首先定义了一个自定义的神经网络模型 MyModel,其中 nn.Conv2d 表示创建一个二维卷积层,in_channels 表示输入张量的通道数,可以根据具体情况进行设置。
接着,在 forward 方法中,我们通过调用卷积层和softmax层来完成前向传播。x.view(x.size(0), -1, x.size(-1)) 表示将输出张量的形状从 [batch_size, n_classes, h, w] 变为 [batch_size, n_classes, h*w],其中 x.size(0) 表示batch size,x.size(-1) 表示空间维度的长度。
最后,我们将输出张量 x 传入 softmax 层中,得到一个概率分布向量,表示输入样本属于不同类别的概率分布。

















 786
786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









