







nlp常见的逻辑处理代码
传参问题
如果之后的代码都依赖某一个相同的输入,如某一个文本,那就把这个输入修改为self的全局变量,避免反复传参。
ocr
结构化,因为目前ppocr还只支持英文。对于固定类习的票据。当前ocr是原子级别的,没有把应该在一起的分开。
1.统计所有文本的平均行高。
2.依次遍历,把所有行高差小于一个的认为是一行,按照x顺序拼接起来。
3.使用关键字分开。
会话形式
把相同角色,相邻的话拼接在一起,形成纯对话形式。
实例:
sentences = [{‘C’:‘xxx’},{‘C’:‘yyy’},{‘S’:‘aaa’},{‘C’:‘QQQ’},{‘S’:‘bbb’}]
–>xxxyyyaaaQQQ*bbb
def change(sentences):
role = sentences[0].keys()
res = list(sentences[0].values())[0]
for sentence in sentences[1::]:
if sentence.keys() == role:
res+=list(sentence.values())[0]
else:
res+='*'+list(sentence.values())[0]
role = sentence.keys()
return res
逐对去合并文本,目标是让信息的杂质更少,样本纯度更高
带来的伤害就是文本识别后合并结果很困难,会有矛盾现象而且无法取舍。
实例:
arr = [2,0,1,0,0,1,1,1,2,2,2,1,1,0,0]
目标是2是无意图,跳过,把相邻的0和1合并起来,后面可以形成一个list(tuple),比如[(xxx,0),(yyy,1)]
很显然本质是双指针。求连续一样的内容,拼接起来。
#其实上面的方法也能完成,这给了另一个方法
def help(arr, i, n):
#确定了是双指针,要找到不一样的内容,而且一般只用移动一个指针,即尾部的指针。而且尾部的指针不包含末尾。不论怎么样,尾部结点都要往后走一步。
j = i+1
while j < n and arr[j] == arr[i]:
j += 1
tmp = arr[i:j]
return tmp, j
def solution(arr):
n = len(arr)
res = []
i = 0
while i < n:
if arr[i] == 2:
i += 1
else:
tmp,j = help(arr,i,n)
res.append(tmp)
i = j
return res
依存关系抽取
树和list的展开
for index in range(len(words)):
child_dict = dict()
# arcs的索引从1开始 arc. head 表示依存弧的父结点的索引。 ROOT 节点的索引是 0 ,第一个词开始的索引依次
# 为1,2,3,···arc. relation 表示依存弧的关系。
for arc_index in range(len(arcs)):
if arcs[arc_index].head == index+1:
if arcs[arc_index].relation in child_dict:
child_dict[arcs[arc_index].relation].append(arc_index)#添加
else:
child_dict[arcs[arc_index].relation] = []#新建
child_dict[arcs[arc_index].relation].append(arc_index)
child_dict_list.append(child_dict)# 每个词对应的依存关系父节点和其关系
- 困难点也是要理解这个数据结构,遍历每一个单词,每一个单词的index+1和依存关系的head一样则记录进去。即这个list的序号表示为字典的头结点,内部的每个关系和尾部结点。
- [‘我’, ‘想’, ‘听’, ‘一’, ‘首’, ‘迪哥’, ‘的’, ‘歌’]
- [{}, {‘SBV’: [0], ‘VOB’: [2]}, {‘VOB’: [7]}, {}, {‘ATT’: [3]}, {‘RAD’: [6]}, {}, {‘ATT’: [4, 5]}],第一个位置是root所以没有,而后表示,第一个词。本质是把树的每个节点展开。
rely_id = [arc.head for arc in arcs] # 提取依存父节点id
relation = [arc.relation for arc in arcs] # 提取依存关系
heads = ['Root' if id == 0 else words[id - 1] for id in rely_id] # 匹配依存父节点词语
for i in range(len(words)):
a = [relation[i], words[i], i, postags[i], heads[i], rely_id[i]-1, postags[rely_id[i]-1]]
format_parse_list.append(a)
- arcs的rely_id每一个是原字符的根,[2, 0, 2, 5, 8, 8, 6, 3],注意该list是根。是这样保存一个树结构的。同样relation是每个词的关系。
- 总结一下,每个词都有一个根,一个根右若干个子节点。上面的代码是从根往下找节点(有n个),下面代码是每个叶子节点的根是谁(只有一个)。
正则
查询两个关键字质检的内容
import re
w1 = 'values\("21",'
w2 = ',NULL'
with open('C:\\Users\\wangdi27\\Downloads\\voice_tab_202101_insert_sql_1613985534.txt','r',encoding='utf8') as f:
lines = f.readlines()
res = []
for line in lines:
bs64_str = re.findall(w1+'(.*?)'+w2, line)[0]
res.append(bs64_str)
length = len(set(res))
print(length)
sub
re.sub("[.,!?\-]", ‘’, text.lower())
- 类似于sql中的正则或,把里面的内容或去除掉。
消歧
实体消歧(Disambiguation)
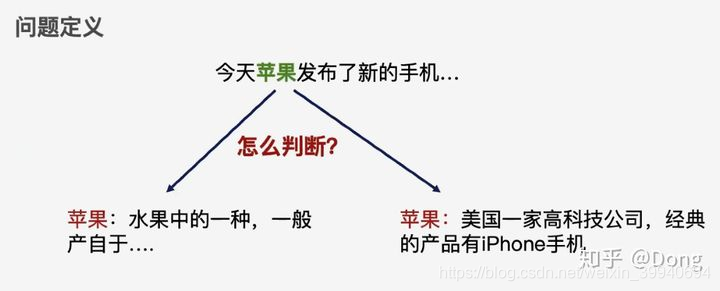
实体统一(Entity Resolution)
不同的公司名其实是一个实体
指代消解(Co-reference Resolution)
其实也可以用相同的框架完成
多目标学习
1.基于贝叶斯估计:
这个代码比较好的是即插即用,函数思想用的很好。
代码里给各个loss上权值,注册到优化器里就可以同时被优化到,简单的优化和加上一个理论之后优化
代码在这里即插即用。(关键字 AutomaticWeightedLoss)
2.各个子任务梯度变化速度和大小都考虑进来,不是即插即用,需要大面积修改代码。但是看懂了其实也不麻烦。
理论在这里
代码在这里















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









