





PyTorch入门
关于如何使用PyTorch进行数据分析和推断的实践演练。
介绍
如今,PyTorch是用于深度学习的增长最快的Python框架之一。实际上,该库最初主要是由研究人员用来创建新模型的,但是由于最近的发展,许多公司也引起了很多兴趣。对这个框架感兴趣的一些原因是:
- GPU使用与Numpy极为相似的界面优化了张量计算(类似于矩阵的数据结构),以便于采用。
- 使用自动微分的神经网络训练(以跟踪张量发生的所有操作并自动计算梯度)。(https://pytorch.org/tutorials/beginner/blitz/autograd_tutorial.html#sphx-glr-beginner-blitz-autograd-tutorial-py)
- 动态计算图(使用PyTorch不必像Tensorflow中那样先运行模型来定义整个计算图)。
按照文档说明,可以免费将PyTorch安装在任何操作系统上。构成此库的一些主要元素是:(https://pytorch.org/get-started/locally/)
- Autograd模块:用于记录在张量上执行的操作并向后执行它们以计算梯度(此属性对于加速神经网络操作并允许PyTorch遵循命令式编程范例非常有用)。(https://en.wikipedia.org/wiki/Imperative_programming)
- Optim模块:用于轻松导入各种优化算法并将其应用到神经网络训练中,例如Adam,随机梯度下降等。
- nn模块:提供了一组功能,可以帮助我们快速地逐层设计任何类型的神经网络。
示范
在本文中,我将引导您完成一个实际示例,以开始使用PyTorch。对于此示例,我们完成Kaggle的一项比赛,我们将使用澳大利亚的Kaggle Rain数据集来预测明天是否会下雨。(https://www.kaggle.com/jsphyg/weather-dataset-rattle-package)
导入模块
首先,我们需要导入所有必需的模块。
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset数据预处理
对于此示例,我们将集中精力仅使用RISK_MM和Location指示器作为我们的模型功能(图1)。将数据分为训练集和测试集后,我们可以将Numpy数组转换为PyTorch张量,并创建训练和测试数据加载器以用于将数据馈入神经网络。
df2 = df[['RISK_MM','Location']]
X = pd.get_dummies(df2).values
X = StandardScaler().fit_transform(X)
Y = df['RainTomorrow'].values
Y = LabelEncoder().fit_transform(Y)
X_Train, X_Test, Y_Train, Y_Test = train_test_split(X, Y, test_size = 0.30, random_state = 101)
# Converting data from Numpy to Torch Tensors
train = TensorDataset(torch.from_numpy(X_Train).float(), torch.from_numpy(Y_Train).float())
test = TensorDataset(torch.from_numpy(X_Test).float(), torch.from_numpy(Y_Test).float())
# Creating data loaders
trainloader = DataLoader(train, batch_size=128, shuffle=True)
testloader = DataLoader(test, batch_size=128, shuffle=True)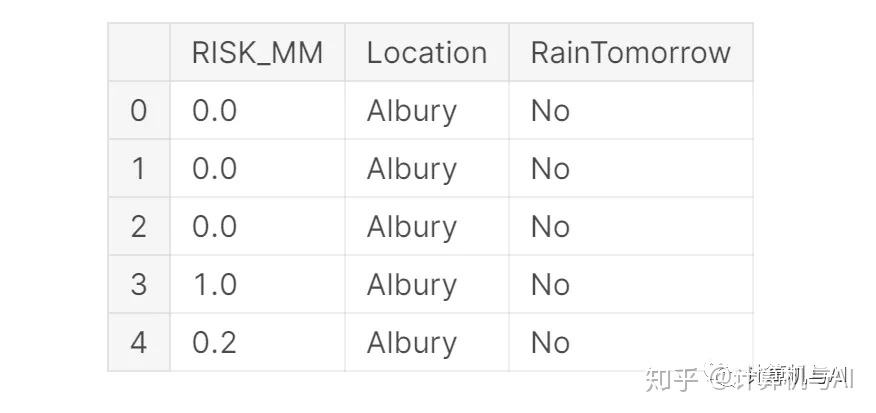
搭建模型
在这一点上,使用PyTorch nn模块,我们可以设计人工神经网络(ANN)。在PyTorch中,神经网络可以定义为由两个主要函数构成的类:__inti __()和forward()。
在__inti __()函数中,我们可以设置网络层,而在forward()函数中,我们可以决定如何将网络的不同元素堆叠在一起。通过这种方式,只需在forward()函数中添加打印语句即可在任何时间检查网络的任何部分,从而可以相对容易地进行调试和实验。
此外,PyTorch还提供了一个顺序接口,该接口可用于以类似于使用Keras Tensorflow API构造模型的方式来创建模型。(https://pytorch.org/docs/stable/nn.html#sequential)
class ANN(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(ANN, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = F.relu(out)
out = self.fc2(out)
if not self.training:
out = F.softmax(out, dim=0)
return out在这个简单的网络中,我们将50个要素作为输入,因为我们之前已使用Pandas get_dummies()功能将输入的分类变量转换为虚拟变量/指标变量。因此,我们的网络将由输入处的50个神经元,20个神经元的隐藏层和单个神经元的输出层组成。隐藏层的大小当然可以变化,并且可以轻松添加更多隐藏层,但是考虑到可用数据量有限,这可能会导致过度拟合我们的数据的风险。将连续的图层放在一起时,我们只需要确保一层的输出要素的数量等于连续图层中的输入要素的数量即可。
一旦实例化了我们的模型,我们就可以打印出网络架构。
# Instatiating the model
人工神经网络训练
现在,我们终于可以训练模型了。在下面的代码片段中,我们首先将Binary Cross Entropy定义为损失函数,将Adam定义为模型参数的优化器。最后,我们创建了一个包含7次迭代的训练循环,并存储了一些关键指标参数,例如每次迭代的总体损失和模型准确性。
# Defying loss function and optimizer
loss_function = nn.BCEWithLogitsLoss()
optimiser = optim.Adam(model.parameters())
# Training loop for each epoch
loss_plot, acc_plot = [], []
for epoch in range(7):
total_loss, correct, total = 0, 0, 0
for x, y in trainloader:
# Zero the parameter gradients
optimiser.zero_grad()
# forward + loss + backward + optimise (update weights)
output = model(x)
outputs = output.squeeze(1)
loss = loss_function(outputs, y)
loss.backward()
optimiser.step()
# Keeping track of the loss
total_loss += loss.item()
output = F.softmax(output, dim=0)
count = [1 for i, j in zip(output, y) if i == j]
correct += sum(count)
total += len(y)
acc = ((100.0 * correct) / total)
print("Epoch: %d, Loss: %4.2f, Accuracy: %2.2f" % (epoch,
total_loss,
acc) + '%')
loss_plot.append(total_loss)
acc_plot.append(acc)
Epoch: 0, Loss: 294.88, Accuracy: 0.13%
Epoch: 1, Loss: 123.58, Accuracy: 6.31%
Epoch: 2, Loss: 62.27, Accuracy: 28.72%
Epoch: 3, Loss: 35.33, Accuracy: 49.40%
Epoch: 4, Loss: 22.99, Accuracy: 64.99%
Epoch: 5, Loss: 16.80, Accuracy: 71.59%
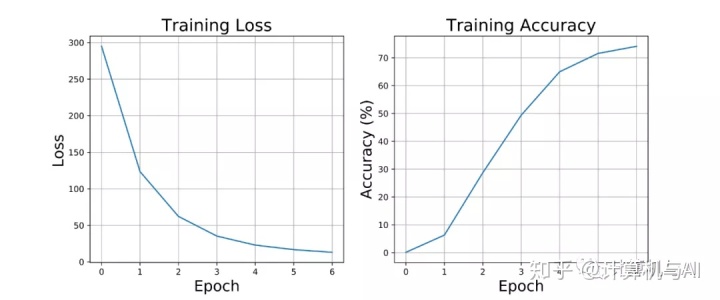
Epoch: 6, Loss: 13.16, Accuracy: 74.13%如下图所示,我们的模型成功地实现了良好的准确性,而没有冒着过度拟合原始数据的风险(训练损失和准确性都即将达到平稳状态)。此外,还可以通过实施训练/验证拆分来训练我们的模型并调整其参数来验证这一点本中所示)。
评价
最后,我们现在可以创建第二个循环以针对一些全新数据测试我们的模型(以确保我们的模型不再训练,并且仅可用于推断,请注意model.eval()语句)。
model.eval()
# Computing the model accuracy on the test set
correct, total = 0, 0
for x, y in testloader:
output = model(x)
count = [1 for i, j in zip(output, y) if i == j]
correct += sum(count)
total += len(y)
print('Test Accuracy: %2.2f %%' % ((100.0 * correct) / total))从打印输出中可以看出,我们的模型测试精度与最终训练精度非常接近(74.66%vs 74.13%)。
结论
如果您有兴趣了解有关PyTorch潜力的更多信息,PyTorch Lighting和Livelossplot是两个不错的软件包,可以帮助您开发,调试和评估PyTorch模型。(https://pytorch-lightning.readthedocs.io/en/latest/)
(https://github.com/stared/livelossplot)
希望您喜欢这篇文章,感谢您的阅读!















 3309
3309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









