





Logistic回归是最常用的机器学习分类方法之一。在大多数的教程和文章中,人们通常解释逻辑回归的概率解释。在这篇文章中,我将尝试给出逻辑回归的几何直觉。本文章将介绍的主题
- Logistic回归的几何意义
- 优化函数
- Sigmoid函数
- 过度拟合和欠拟合
- 正则化 - L2和L1
直觉

从上面的图像中我们可以简单地将Logistic回归看作是找到一个平面的过程,Logistic回归可以证明这些类是线性可分的。
现在我们需要一个分类器来分离这两个类。从图1中我们可以观察到,W^T * Xi > 0 代表正类,W^T * Xi < 0 代表负类。
所以我们的分类器是 -
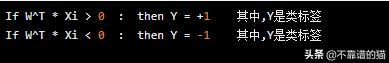
寻找合适的平面
为了测量任何东西,我们需要一个值,我们将通过定义一个优化函数得到这个值,这个函数的结果将用于确定哪个平面是最好的。这是非常模糊和抽象的,但是我想用一些例子来解释它。
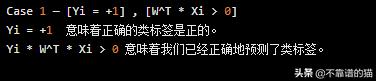
示例 - W ^ T * Xi = 5(5> 0)且Yi = +1。
这里,Yi * W ^ T * Xi = 5
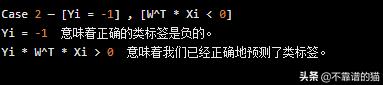
示例 - W ^ T * Xi = -5(-5 <0)并且Yi = -1。
这里,Yi * W ^ T * Xi =( - 1)( - 5)= 5
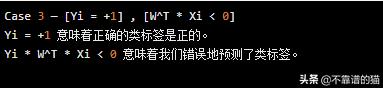
示例 - W ^ T * Xi = -5(5 <0)并且Yi = +1。
这里,Yi * W ^ T * Xi =(1)( - 5)= -5
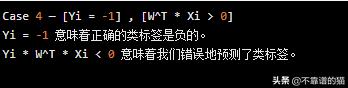
示例 - W ^ T * Xi = 5(5 <0)并且Yi = -1。
这里,Yi * W ^ T * Xi =( - 1)(5)= -5
如果仔细观察这些情况,那么您将观察到这Yi * W^T*Xi > 0 意味着我们已经正确地对点进行了分类,Yi * W^T * Xi < 0 意味着我们错误地对点进行了分类。
看起来我们已经找到了我们期待已久的优化函数。
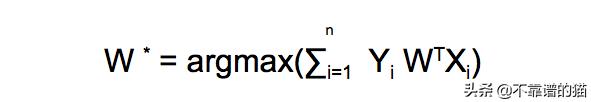
优化函数
因此这个函数最大值的平面将作为决策面(最佳分隔我们的点的平面)。
分析优化函数 -
让我们先分析这个函数并确保无论机器学习数据集如何,此函数都能正常工作。

正如您可能已经猜到的那样,我们的优化函数不够强大,无法处理任何异常值。直观地看,如果你看一下上图,你就会发现ㄫ1是一个比ㄫ2更好的平面,因为ㄫ1正确分类了14个数据点而ㄫ2只能正确地分类一个数据点但是根据我们的优化函数ㄫ2更好。
有多种方法可以从机器学习数据集中删除异常值,但是没有这样的方法可以消除100%的异常值,正如我们上面所看到的,即使是单个异常值也会严重影响我们对最佳平面的搜索。
那么我们如何处理这些异常值问题呢?Sigmoid函数。
Sigmoid函数
Sigmoid函数背后的基本思想是squishing。Squishing可以解释如下 -

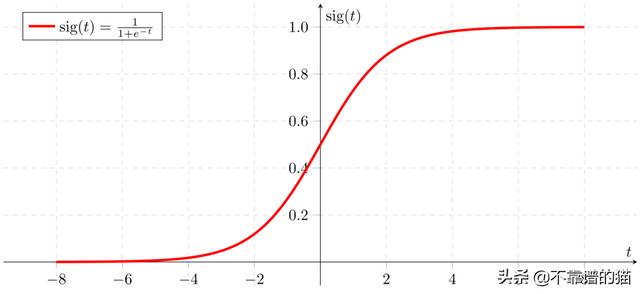
Sigmoid函数
Sigmoid函数搜索较大的值,所有值将介于0和1之间。
现在你一定在想,还有很多其他的函数可以同样的作用在一定范围内,限制我们的函数值,那么,关于sigmoid函数,有什么特别的呢。
为什么Sigmoid? -
选择sigmoid函数的原因有多种,它提供了一个很好的概率解释。例如 - 如果一个点位于决策面(d = 0),那么凭直觉它的概率应该是1/2,因为它可以属于任何类,在这里我们也可以看到 - Sigma(0)= 1/2。
所以我们新的优化函数是 -
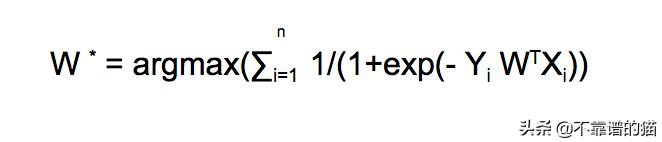
我们可以通过对这个函数取对数来进一步修改它来简化数学运算。因为对数函数是单调递增的,所以它不会影响我们的机器学习模型。如果你不知道单调递增函数是什么,那么这里有一个简单的概述-
函数g(x)称为单调递增函数
当x增加时g(x)也增加
如果x1 > x2则 g(x1) > g(x2) --如果g(x)是一个单调递增的函数。
转换优化函数 -
在得到优化函数的最佳版本之前,仍然需要进行一些转换。
- 取对数
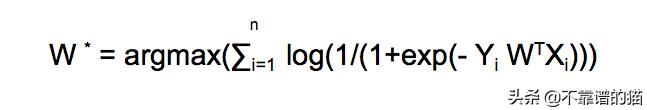
2. 使用Log属性进行转换 - log(1 / x)= -log(x)
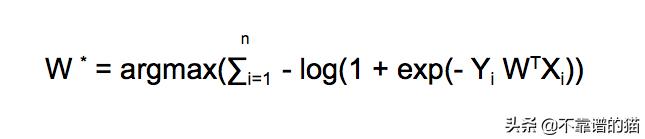
3. 使用属性 - argmax(-f(x))= argmin(f(x))
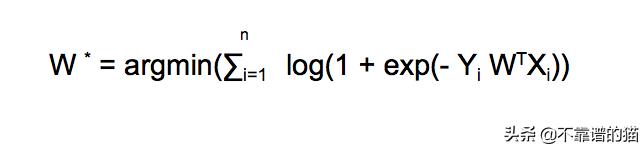
最小化的策略
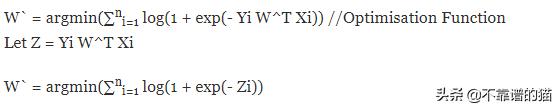
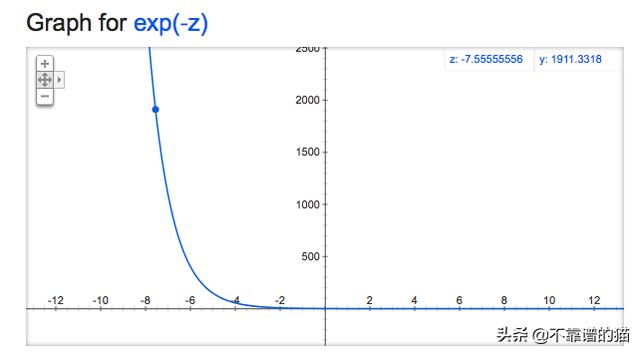
从上图可以看出exp(-Zi)总是正的。我们希望最小化优化函数,exp(-Zi)的最小值是0。
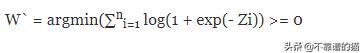
优化函数的最小值为0,当exp(-Zi)为0时,log(1+0) = 0。
因此,优化函数的总体最小值将在
Zi -> +∞ for all i
让我们仔细看看Zi。
Z = Yi W^T Xi由于它是一种监督学习算法,因此我们给出了X和Y的值。
- X - 基于我们预测正确类标签的特征
- Y - 正确的类标签
所以我们不能改变Xi或Yi,因此剩下的唯一要处理的项是W。你可以凭直觉知道,如果我们取一个很大的W值,那么只有Z会趋近于无穷。
为了将Zi的值移动到无穷大,我们将为W选择一个非常大的值(+或 - )。
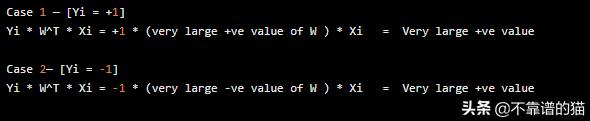
因此,您可以看到我们是否为W选择了一个大值,那么我们就可以实现我们的目标 Zi -> +∞
这个策略的问题 -
通过使用上述策略,一切看起来都很好,因为我们的目标是 -
Zi-> ∞并且log(1 + exp(- Zi)) -> 0 如果我们使用这个策略,那么我们可以成功地做到这一点。
这个策略的唯一问题是我们可以成功地最小化我们对'i'的所有值的优化函数。听起来有点讽刺,因为我们的目标是最小化i的所有值的函数,并且突然间它成为一个问题。如果你感到沮丧,那么这是一个非常好的迹象,这意味着你已经理解了每一个细节。让我们深入研究这个问题。
这里的主要问题是我们过度拟合了我们的机器学习模型。如果你不熟悉过度拟合,那么这里是一个简要的概述-
过度拟合意味着我们的模型在训练数据上运行得很好(因为它只是根据训练数据调整权重),但是结果在测试数据上表现很差
这不是技术上正确的定义,我只想给你一个过度拟合的直觉。
过度拟合
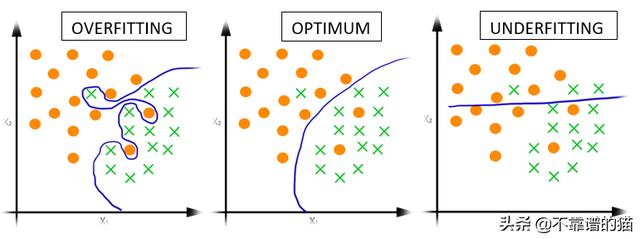
这里的点表示+ ve数据点,叉表示-ve数据点。
正如您在过度拟合的情况下所看到的那样,我们的决策面可以完美地对每个点进行分类,在这种情况下,我们将获得100%准确的训练数据结果。但考虑一下这种情况 -
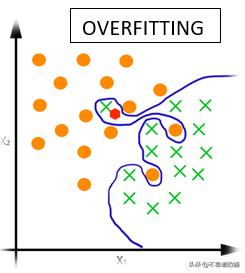
这里红点是我们的测试数据点,我们想要预测它是属于正类还是负类,正如你所看到的,根据我们的决策面,它是一个负的类点,但我们可以看到它很可能是一个正类点,因为它相比负类点更接近正类点。这称为过度拟合。
这就是我们的模型的样子,如果我们遵循上面的策略,总是选择一个大的W值,并使Zi - > +∞
正则化
现在你已经明白了解实际问题是什么,我们可以寻求解决方案,而解决方案就是正则化。
很多人可能对此有一个模糊的想法,你可能听说它用于防止过度拟合和欠拟合,但很少有人真正知道如何通过使用正则化来防止过度拟合和欠拟合。
有两种主要的正则化类型 -
- L2正则化
- L1正则化
L2正则化 -
在L2正则化中,我们引入了一个称为正则化项的附加项,以防止过度拟合。
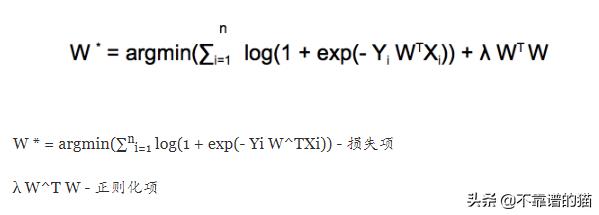
这里'λ'是一个超参数,它将在我们的分类模型中发挥重要作用,但首先让我们关注这个正则化项的影响。
如果你记得我们的目标是制作Zi -> +∞ 并且由于Xi和Yi是固定的,因此我们只能调整W的值,在这里你可以看到我们将W ^ TW与λ相乘。
所以早些时候我们正在增加W的值来实现它,+∞ or -∞ ,但现在如果我们试图这样做,那么我们的正则化项的值将非常大,因此我们的模型将会明白它正在出错,而W的值将会被有效地调整。
正则化项基本上惩罚了我们的模型,用于选择非常大的W值,从而避免过度拟合。
λ的作用 -
λ在优化我们的函数方面起着关键作用。
- 如果我们显著降低λ的值,那么随着正则化项的影响可以忽略不计,模型会过度拟合。
- 如果我们显著增加λ的值,则我们的模型欠拟合,因为损失项变得可以忽略不计,正则化项不包含任何训练数据。
L1正则化 -
L1正则化的目的与L2的目的相同,即在这种情况下避免过度拟合。

L1和L2正则化之间的主要区别在于L1正则化创建稀疏向量。
F = W = 这里,如果我们有一个不重要或不太重要的特征fi,那么如果我们使用L1正则化,那么对应于它的权重将为0,而如果我们使用L2正则化,那么它将是一个很小的值,不一定是0。















 1174
1174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









