





点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达
国防科大&旷视科技:据我们所知,ThunderNet实现了ARM平台上的第一个实时检测器和最快的单线程速度。本文转载自yuanCruise
[论文地址](https://arxiv.org/pdf/1903.11752.pdf)
代码即将开源
1 .网络整体介绍
ThunderNet的整体架构如下图所示。 ThunderNet使用320×320像素作为网络的输入分辨率。整体的网络结构分为两部分:Backbone部分和Detection部分。网络的骨干部分为SNet,SNet是基于ShuffleNetV2进行修改得到的。 网络的检测部分,利用了压缩的RPN网络,修改自Light-Head R-CNN网络用以提高效率。 并提出Context Enhancement Module整合局部和全局特征增强网络特征表达能力。 并提出Spatial Attention Module空间注意模块,引入来自RPN的前后景信息用以优化特征分布。
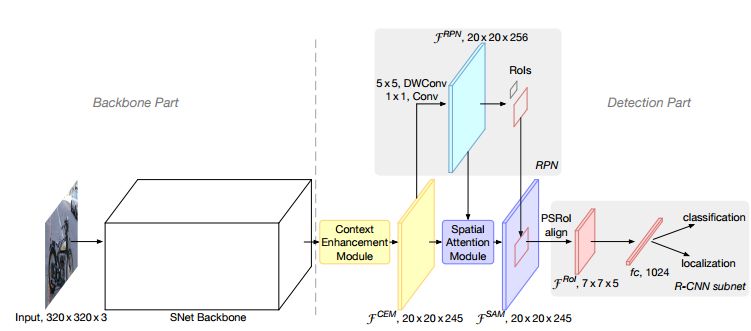
2 .backbone 部分
一:输入分辨率
为了加快推理(前向操作)速度,作者使用320*320大小的输入图像。需要注意的是,在实践中,我们观察到输入分辨率应该与骨干网络的能力相匹配。 具有大输入的小骨干和具有小输入的大骨干都不是最佳的选择。
二:骨干网络(backbone)
骨干网络需要具有两大特点,第一:大的感受野很重要。第二:浅层特征位置信息丰富,深层特征区分度更大,因此需要兼顾这两种特征。而作者认为主流的轻量级网络违法了上述原则,比如ShuffleNetV1/V2限制了感受野。ShuffleNetV2 和MobileNetV2 缺乏浅层特征,而Xception 在计算预算低下的情况下缺乏深层特征。
Note:主流轻量级网络介绍
ShuffleNet V1/V2 | 轻量级深层神经网络
MobileNets V1/V2 | 轻量级深层神经网络
SqueezeNext | 轻量级深层神经网络
SqueezeNet | 轻量级深层神经网络
yuanCruise,公众号:yuanCruiseShuffleNet V1/V2 | 轻量级深层神经网络
基于上述原因,作者在ShufflenetV2的基准下,结合上述特性对ShufflenetV2进行修改并命名为SNet。如下图所示,作者给出了集中不同形式的SNet网络。
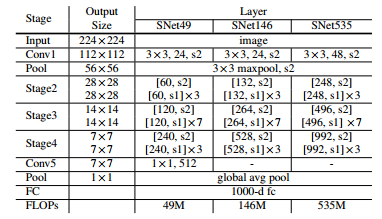
SNet49用于更快的推理,SNet535用于更好的精度,SNet146用于更好的速度/精度权衡。首先,我们用5×5深度可分离卷积替换ShuffleNetV2中的所有3×3深度可分离卷积(来自Mobilenetv1)。在实践中,5×5深度卷积提供与3×3对应物相似的运行速度,同时有效地扩大了感受野。在SNet146和SNet535中,作者删除了Conv5并在浅层特征提取阶段添加了更多通道。此设计可生成更多位置信息,而无需额外的计算成本。在SNet49中,作者将Conv5压缩为512个通道,而不是将其删除,并在浅层特征提取阶段增加通道,以便实现浅层和深层特征间更好的平衡。作者认为删除Conv5,骨干网络就无法提取足够的信息。而且要是保留1024维度的Conv5层,骨干网络就会受到有限的浅层特征的影响。上图显示了主干的整体架构。此外,下文中将Stage3和Stage4的最后输出特征图(SNet49的Conv5)表示为C4和C5。
3 .Detection部分
检测部分沿用了Light-Head R-CNN网络的结构,虽然该网络使用轻量级的检测器,但当与上述的SNet这个更轻量级的骨干网络耦合时它仍然太重,并且会引起骨干网络和检测器之间的不平衡。 这种不平衡不仅导致冗余计算,而且增加了过度拟合的风险。上述骨干网络部分中输入分辨率不匹配也会导致类似问题。
为了解决这个问题,作者使用一个5×5的深度可分离卷积(mobilenetv1中)和1×1卷积,替换原始RPN网络中的3×3的卷积。并且在RPN网络中使用的尺度大小为{32×32,64×64,128×128,256×256,512×512},anchor的长宽比为{1:2,3:4,1:1,4:3,2:1}。其余参数和Light-Head R-CNN中的一致。检测部分主要的创新点是,提出了Context Enhancement Module和Spatial Attention Module这两种策略。
一:Context Enhancement Module
Light-Head R-CNN网络中在骨干网络之后利用GCN:Global Convolutional Network产生更小的特征图,这虽然增加了感受野但却提升了计算复杂度,因此在本文提出的网络中没有使用GCN。然而,感受野小且在没有GCN的情况下网络很难提取到足够的可分辨的特征信息。 为了解决这个问题,本文使用了特征金字塔网络FPN。 然而,原始的FPN结构涉及许多额外的卷积和多个检测分支,这增加了计算成本并且引起了巨大的运行时间延迟。因此,基于FPN,本文提出了Context Enhancement Module (CEM),示意图如下。
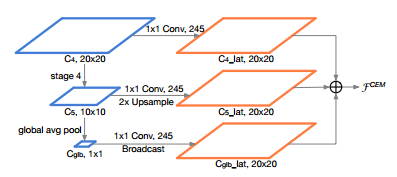
CEM的关键思想是聚合多尺度局部信息和全局信息,以生成区分性更强的特征。在CEM中,合并三个尺度的特征图:C4,C5和Cglb(在C5上应用全局平均池化得到Cglb作为全局特征信息)。
尺度一:C4特征图上应用1×1卷积以将通道数量压缩为α×p×p = 245
尺度二:C5进行上采样 + C5特征图上应用1×1卷积以将通道数量压缩为α×p×p = 245
尺度三:Cglb进行Broadcast + Cglb特征图上应用1×1卷积以将通道数量压缩为α×p×p = 245 。
通过利用局部和全局信息,CEM有效地扩大了感受野,并细化了薄特征图的表示能力。与先前的FPN结构相比,CEM仅涉及两个1×1卷积和fc层,这更加计算友好。
二:Spatial Attention Module
在进行RoI操作的时候,我们期望背景区域中的特征不被关注,且前景物体的特征被强烈关注。 然而,由于本文的检测网络利用的是轻量级骨干网络和小分辨率输入图像,因此很难学习到正确的特征分布。出于这个原因,作者设计了一个计算友好的空间注意模块(SAM),以便在RoI扭曲空间维度之前显式地重新加权特征图,引导网络学习到正确的前景背景特征分布。SAM的关键思想是使用来自RPN学习到的知识来细化特征图的特征分布。因为训练RPN网络时,网络就是以前景目标作为监督来训练的。 因此,RPN网络可以用于区分前景特征和背景特征。
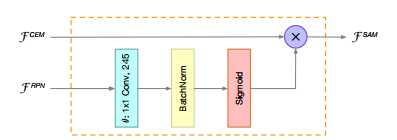
SAM有两个输入,分别来自于CEM和RPN,而输出如下公式所示:
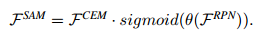
这里θ(·)是一个尺寸变换,以匹配两组特征图中的通道数。 sigmoid函数用于约束[0,1]内的值。 最后,通过生成的特征映射对,使得CEM进行重新加权,以获得更好的特征分布。 为了计算效率,我们将1×1卷积应用于θ(·),因此CEM的计算成本可以忽略不计。 如下图所示,显示了SAM的结构。
4. 网络效果展示
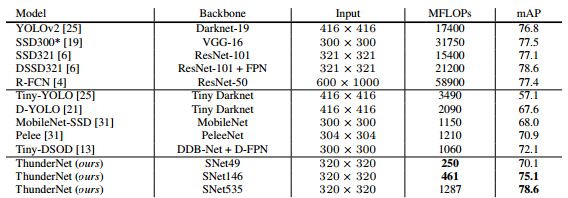
VOC 2007测试的评估结果。 ThunderNet以更低的计算成本超越竞争模型。
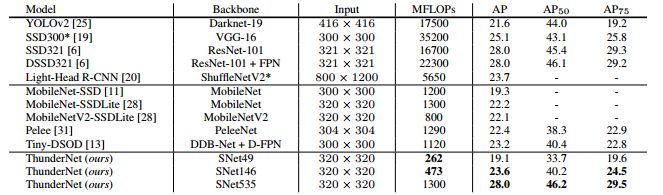
COCO test-dev的评估结果。 采用SNet49的ThunderNet实现了MobileNet-SSD级精度,确快将近五倍。 采用SNet146的ThunderNet与轻型one-stage检测网络相比,具有更高的精度。 采用SNet535的ThunderNet可与大型检测网络相媲美,计算成本显着降低。
CVer目标检测交流群
扫码添加CVer助手,可申请加入CVer-目标检测交流群。一定要备注:目标检测+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群
这么硬的论文速递,麻烦给我一个好看

▲长按关注我们
麻烦给我一个好看!














 488
488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









