





ISLR(6)-线性模型选择与正则化
乱花丛中过,只沾我爱的,信用卡最优模型的变量筛选
笔记要点:
0.线性模型选择
1.最优子集选择(6.1.1)
2.逐步选择
-- 正向逐步
-- 反向逐步
3.选择最优模型
--
-- 验证与交叉验证
0. 基于信用卡的线性模型选择方法介绍
回顾信用数据集的十个变量
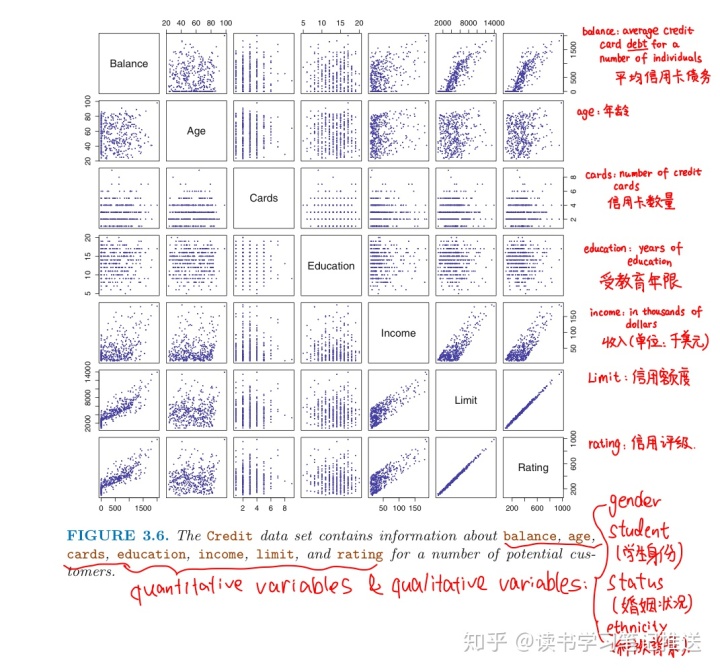
这篇笔记将总结筛选预测变量子集的三种方法
1. 最优子集选择(枚举法)
❝ Backward Stepwise Selection:
- Let
null model, which contains no predictors. This model simply predicts the sample mean for each observation.
denote the
- For k = 1, ..., p:
(a) Fit allmodels that contains exactly k predictors
(b) Choose the best model among thesemodels, and call it
.
- best is defined as having 「smallest RSS」 or 「highest
」
- Select a single best model among
using cross validated prediction error,
(AIC), BIC, or adjusted
❞
「优点:简单直观」
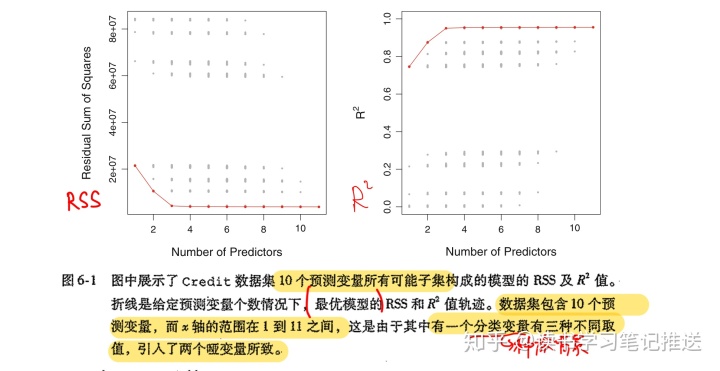
上图中每一个点对应一个信用数据集11个预测变量的不同子集建立的最小二乘模型对应的RSS和
「缺点:计算效率不高」
- p = 10 ==> 1024个可选模型
- p = 20 ==> 可选模型数量超过100万个
- p = 40 ==> 最优子集选择不具有计算可行性
尽管存在一些提升运算效率的算法「e.g.分支定界方法」可以缩小选择范围, 但是:
- p 增大时,该算法也存在缺陷
- 方法只对「最小二乘线性回归」模型有效
随着搜索空间(n)增大,通过最优子集选择方法找到的模型虽然在训练数据上有很好的表现,但对新数据并不具备良好的预测能力。
- 从一个巨大搜索空间中得到的模型通常会有「过拟合」和「系数估计方差高」的问题
2. 逐步选择 (P207 - 210)
针对最优子集方法的问题,逐步选择方法可以限制搜索空间,从而提高运算效率
2.1 正向逐步选择
特点:从k=0开始,每k次只将(p-k)个模型中能够最大限度提升模型效果的变量加入模型, 总共拟合了
- 当p=20,正向逐步选择只需要拟合211个模型, 而最优子集选择需要拟合1048567个模型
❝ Forward Stepwise Selection:
- Let
null model, which contains no predictors
denote the
- For k = 0, 1, ..., p:
(a) Consider allmodels that augment the predictors inwith one additional predictor
(b) Choose the best model among thesemodels, and call it
.
- best is defined as having 「smallest RSS」 or 「highest
」
- Select a single best model among
using cross validated prediction error,
(AIC), BIC, or adjusted
❞
「缺点」
无法保证最优: 如果最优单变量模型包含

在高维数据中, 甚至 「
- however, in this case, it is possible to construct submodels
only,
- since each submodel is fit using least squares, which is NOT yield a unique solution if 「
」
- since each submodel is fit using least squares, which is NOT yield a unique solution if 「
2.2 反向逐步选择
以包含全部
❝ Backward Stepwise Selection:
- Let
full model, which contains all
denote the
predictors
- For k = p, p-1, ..., 1:
(a) Consider all k models that contain all but onepredictors in
(b) Choose the best model among thesemodels, and call it
.
- best is defined as having 「smallest RSS」 or 「highest
」
- Select a single best model among
using cross validated prediction error,
(AIC), BIC, or adjusted
❞
反向逐步同样搜索了
「条件」
需要满足 「
- 当
时只能选择正向逐步选择
2.3 混合方法
与正向逐步选择类似, 该方法逐次从零将变量加入模型
- 在加入新变量的同时, 该方法也「移除」不能提升模型拟合效果的变量
混合方法可以更接近「最优」子集的同时保留计算效率的优势
3.选择最优模型的两种方式
因为训练集的均方误差(MSE = RSE/n)通常比测试集的均方误差低, 训练误差可能是测试误差的一个较差估计
- 和训练误差有关的 RSS 和
值并不适用于对包含不同个数预测变量的模型进行模型选择
估计测试误差选择最优模型:
- 根据过拟合导致的偏差对训练误差进行调整, 「间接」估计测试误差
- 验证集方法&CV 「直接」估计测试误差
方式一:4 statistics to judge the quality of model
「
采用最小二乘法拟合一个包含 「
- typically,
is estimated using the full model containing all predictors
The
- to adjust for the fact that the training error tends to 「underestimate」 the test error
- the penalty 「increases」 as the number of predictors(d) in the model increases
- to adjust for the corresponding 「decrease in training RSS」
【知识点】: 如果
测试误差较低的模型
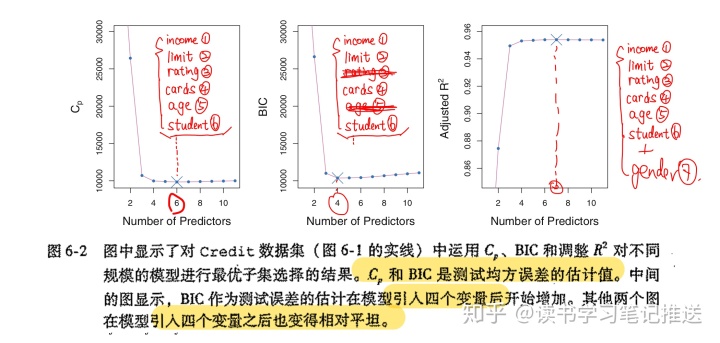
- 六个变量:
income,limit,rating,cards,ageandstudent- 收入, 额度, 信用评分, 信用卡数量, 年龄和学生身份
「AIC:Akaike Information Criterion」
赤池信息量准则适用于许多使用极大似然法进行拟合的模型
- 如果多元线性回归模型的
「高斯分布」
服从
- 极大似然估计和最小二乘估计是等价的
- 对于最小二乘模型,
和AIC彼此成比例
「BIC:Bayesian Information Criterion」 BIC从贝叶斯观点中衍生出来, 最终与
- 测试误差较低的模型BIC统计量较低
- 通常选择具有最低BIC的模型作为最低模型
BIC将
- n为观测数量, 当 n>7, log(n)>2
- BIC统计量给包含多个变量的模型更重的惩罚
- 与
相比, 得到的模型更小(精度差不多)
- 四个变量:
income,limit,cards、student,rating,age
- 与
「Adjusted
由于RSS随着模型的变量个数增加而降低,
当模型包含了所有正确的变量, 再增加其他冗余变量只会导致RSS小幅度的减小,同时d的增加导致
- 因此最大
的模型只包含所有正确的变量并且对于加入冗余变量的模型引入惩罚
- 七个变量:
(AIC)基础模型 +
gender
「对比」
- 证明涉及当样本量n十分大时参数的渐进性质(big-O)
方式二:Validation and CV(ch5)
和方式一相比, 方式二给出了测试误差的直接估计, 并且对真实的潜在模型有较少的假设
- 即便在很难确定模型的「自由度」、难以估计「误差方差
的情况下仍然可以使用
」
图6.3
「One-standard-error Rule」
如果对不同的训练集和验证集重复使用验证集方法, 或者对于不同的交叉验证折数重复使用交叉验证方法,会得到不同的具有最低测试误差的精确模型
一倍标准误差可以针对不同精确模型进行模型选择
- 首先, 计算不同规模下模型的「estimated test MSE」的标准误差,
- 然后, select the 「smallest model」 for which the estimated test error is 「within one standard error」 of the lowest point on the curve
- 原因:在效果近似相同的模型中, 总是倾向于选择最简单(具有最少预测变量)的模型
对验证集方法和交叉验证方法使用「一倍标准误差准则」选择出模型包含三个变量
4. 参考:
- Introduction to Statistical Learning (ISL)
- 《老董聊卡》
- 校对:Wendy(Tiantian) Wang














 8641
8641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









