







模型路径:
1.架构为扩散模型(diffusion model)+transformer

2.训练时先用预训练模型把大量的大小不一的视频源文件编码转化为统一的 patch 表示,把时空要素提取作为 transfommer的token进行训练。
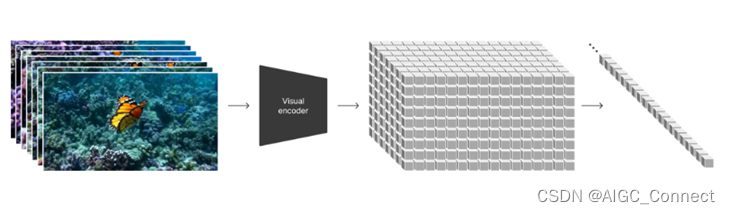
3.模型效果好和超大量的数据集和更多的运算时间息息相关
优势:
1.人物和背景的连贯性,即时人物运动出了相机范国再回来时还保持同样特征
2.自然语言的理解程度很高
3.可以在同一个种子下生成不同尺寸(横向竖向)的视频适配不同设备
4、可以生成长达 1min 高清视频
5.可以以文字,图片,视频作为控制要素控制输出
结果不足:
1.对于物理规则了解较弱,比如吹气后蜡烛不会熄灭,左右不分,玻璃掉落不会碎
2.对于算力要求较高(猜测)
可以实现:
1.文生视频,图生视频,图+文生视频,视频修改
2.视频转绘,视频延伸,视频补全

















 2673
2673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









