







Linux 文本处理-三驾马车
整理自生信技能树Linux课程笔记
grep
- 文本搜索工具,使用正则表达式匹配模式搜索文本,并把匹配的行打印出来
- 格式:grep [options] pattern file
- 常见参数:
- -w:word 精确查找某个关键词 pattern
- -c:统计匹配成功的行的数量
- -v:反向选择,输出没有匹配的行
- -n:显示匹配成功的行所在的行号
- -r:从目录中查找pattern
- -e:指定多个匹配模式
- -f:从指定文件中读取要匹配的pattern
- -i:忽略大小写
正则表达式
- 是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
- ^ 行首
- $ 行尾
- . 换行符之外的任意单个字符
- ? 匹配之前项0次或者一次
- + 匹配1次或者多次
- 通配符* 匹配1次或者多次
- {n} 匹配n次
- {n, } 匹配至少n次
- {m,n} 至少m,最多n
- [] 匹配任意一个
- [^] 排除字符
- | 或者
- 特殊字符用转义符 \ 或者在pattern前加 -E
- 示例
-
- 此处 less -SN -r Data/* 更为准确


- 此处 less -SN -r Data/* 更为准确
-
- 一个字符前加一个**-e**,可以写成文本的形式,grep -w -n -f file
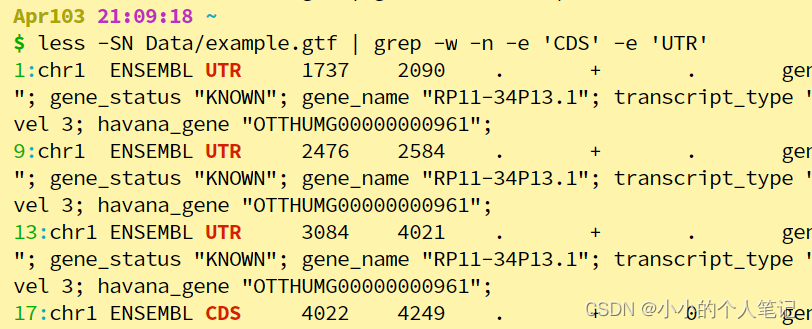
- 一个字符前加一个**-e**,可以写成文本的形式,grep -w -n -f file
-
- 反选


- 反选
-
sed
- 对文本进行增删改查
- 用法:sed [-options] ‘script’ file(s)
- 常见参数:
- -n:禁止显示所有输入内容,只显示经过sed处理的行
- -e:直接在命令模式上进行sed的动作编辑,接要执行的一个或多个命令
- -f:执行含有sed动作的文件
- -r:sed的动作支持的扩展正则
- -i:直接修改读取的文件内容,不输出
- 用法:
- sed [-options] ‘script’ file
- sed [-options] [address] [!] command file
- 常见 ‘script’ address:
- 2:第二行
- 2,4:第 2 行到第 4 行
- 2,$:第 2 行到最后一行
- 2~3:从第 2 行开始,每隔 3 行取一行
- 2,+4:第 2 行到 2+4 行
- /pattern/:匹配上 pattern 的行
- [!]:表示否定,取反。‘2!’ 表示除了第 2 行
- 常见 ‘script’ command : 增删改查
- a:append,在指定行的后增加一行,内容为 a 的后面接的字串
- i:insert,在指定行的前增加一行,内容为 i 的后面接的字串
- d:delete,删除某一行或者某几行,也可以指定删除匹配上的行
- c:change,改变指定行的内容
- s:更改或替换字符串,使用格式为 ‘s/pattern/new/[flags]’
- y:转换,字符一对一
- p:print,把匹配或修改过的行打印出来,通常与**–n**参数合用
- 常见 ‘script’ address:
- 举例
-
- 三种都可
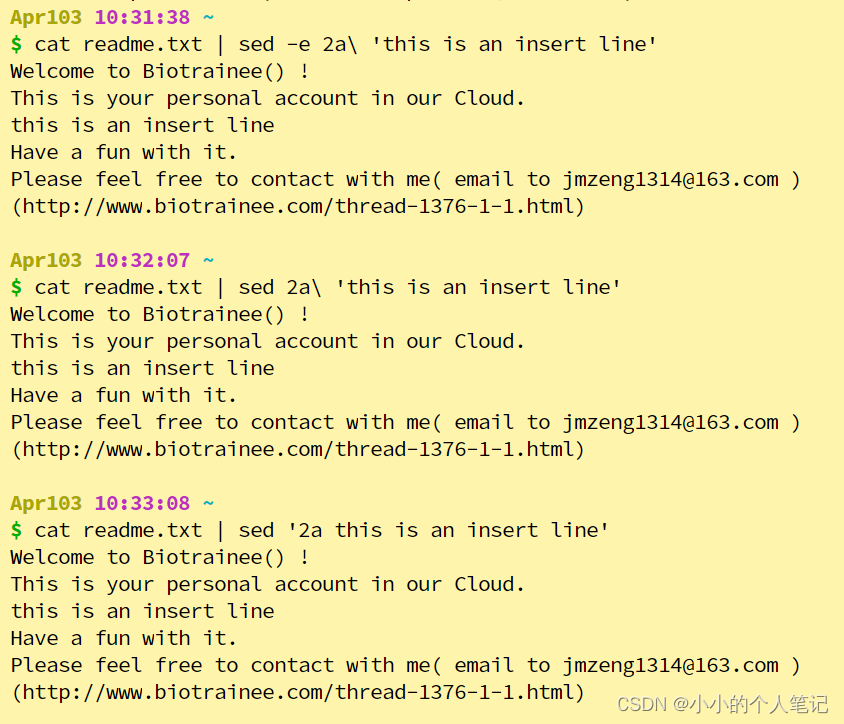
- 三种都可
-
- 指定pattern,不指定行号,默认所有
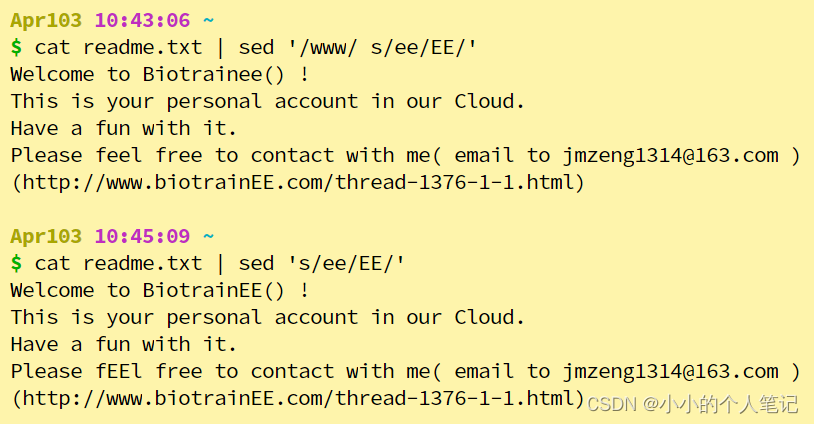
- 指定pattern,不指定行号,默认所有
-
- 指定行号,s/pattern/new/ 中的 /// 可换为其它相同符号
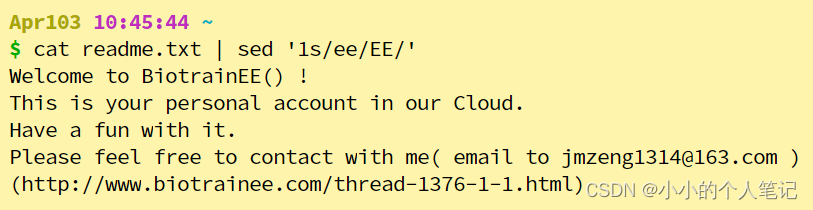
- 指定行号,s/pattern/new/ 中的 /// 可换为其它相同符号
-
- -n和p联用

- -n和p联用
-
- 取反
- 删除带有gi pattern的行并另存


-
awk
也叫gwak,编程语言,可对文本和数据进行处理
- 常见参数:
- -F:fields,设置字段分隔符
- 用法:
- awk [options] ‘{script}’ file
- 基础架构:‘{script}’
- 匹配结构:‘/pattern/{script}’
- 扩展结果:‘BEGIN{script} {script} END{script}’
- 遍历中间的 {script}
- 在读取一行文本时,会用预定义的字段分隔符划分每个数据字段,并分配给一个变量 。
- $0:代表整个文本行
- $1:文本行中的第1个数据字段
- …
- $NF:文本行中的最后1个数据字段
- 默认的字段分隔符是任意空白字符(如空格 or 制表符),也可以用 -F 参数自定义分隔符;默认输出来是空格
- awk 内置变量
- FS:定义输入字段分隔符,Field Separator,同 -F
- RS:定义输入记录分隔符,Record Separator
- OFS:定义输出字段分隔符,Out Field Separator
- ORS:定义输出记录分隔符,Out Record Separator
- NF:数据文件中的字段总数,可以简单理解为列数
- NR:已处理的输入记录数,可以简单理解为行数
- 示例
-
- 设置 OFS 以定义输出字段分隔符:
- less -SN Data/example.gtf | awk ‘BEGIN{OFS=“:”} {print $9}’ | head -5
-
- 使用NR来打印行号:
- less -SN Data/example.gtf | awk ‘BEGIN{FS=“\t”} {print NR,$9}’ | less -S
-
- awk 条件和循环语句
- if:条件判断
- awk ’ { if (判断条件) { yes } else {no} } ’
- less -S Data/example.gtf | awk ‘{if($3==“exon”) {print}}’ | less -S
- for:循环语句
- awk ’ { for (循环条件) {循环语句} } ’
- if:条件判断
- awk 数学运算
- +加、-减、*乘、/除、^幂、%取余
- **平方
- int(x) x的整数部分
- long(x) x的自然对数















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









