






目的:使得network变小,用于较小的设备当中。
模型压缩(Network Pruning):因为模型中有的权重或神经元没有起到作用。
1.训练一个大的网络。
2.评价网络中weight和neruon的重要性。
可以利用 L1,L2评价weight。如果该weight接近于0则说明该weight重要性不大。如果神经元的输出为0,也可以理解为该神经元不重要。
3.移除不重要的weight和不重要的neruon。
4.移除之后,拿到原来的数据集下进行fine-tune
神经网络模型可以理解为多个小模型的集合,可以把它看作一个继承模型。大的模型效果好主要是其中存在一个小模型可以实现很好的效果。因此模型压缩可以理解为在找大模型中效果最好的小模型。
知识蒸馏(Knowledge Distillation):一个大的网络(teacher net),一个小的网络(student net).让小网络的输出尽量和大网络的输出相同。
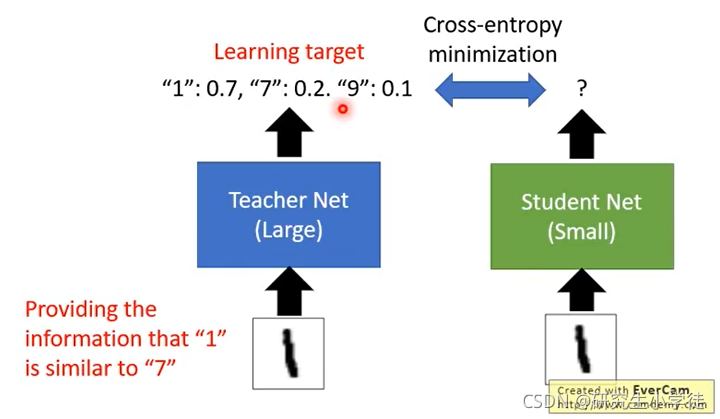
为了让 student net 更轻易的学到 teacher net 的输出分布,在两个网络的最后一层不使用 softmax(因为通过softmax的输出和label一样的,对student net 没有意义)。

减少模型参数的trick: 在两层之间插入一个线性层,但这样可能会限制网络的能力。
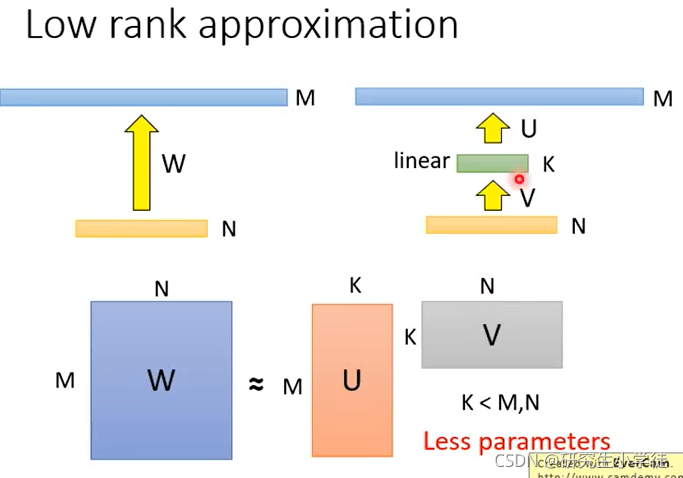
总结:
Network Pruning: 将network不重要的weight和neuron进行删除,再重新train一次。
原因:大的NN有很多冗余的参数,而小的NN很难train,那就用大NN删成小NN就好了。
Knowledge Distillation:利用一个已经学好的大model来教小model如何做好任务。
原因:让学生直接作对题太难,让学生看老师如何做题的
应用:通常只用在classification, 而且学生只能从头学起。
Architecture Design: 利用更少的参数达到原本某些layer的效果。
原因:有些layer可能参数很冗余,比如DNN
应用:直接套新的model,或利用新的layer来模拟旧的layer。
Parameter Quantization(参数量化):将原本NN常用的计算单位:float32/float64压缩为更小的单位。
原因:对于NN来说,小数点后面好多位的数字其实意义不大。

















 374
374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









