







 DistilBERT是通过知识蒸馏技术将BERT模型压缩至40%参数量,同时提升60%推理速度,保留约97%的性能。它采用三重损失函数,包括有监督MLM损失、蒸馏MLM损失和词向量余弦损失,以教师模型的输出指导学生模型的学习,实现模型压缩与性能保持。
DistilBERT是通过知识蒸馏技术将BERT模型压缩至40%参数量,同时提升60%推理速度,保留约97%的性能。它采用三重损失函数,包括有监督MLM损失、蒸馏MLM损失和词向量余弦损失,以教师模型的输出指导学生模型的学习,实现模型压缩与性能保持。
目录
一、概述
预训练语言模型虽然在众多自然语言任务中取得了很好的效果,但通常这类模型的参数量较大,很难满足实际应用中的时间和空间需求。 下图给出了常见预训练语言模型参数量的发展趋势。可以看到,预训练语言模型的参数量呈加速增大的趋势。这使得在实际应用中使用这些预训练语言模型变得越来越困难。
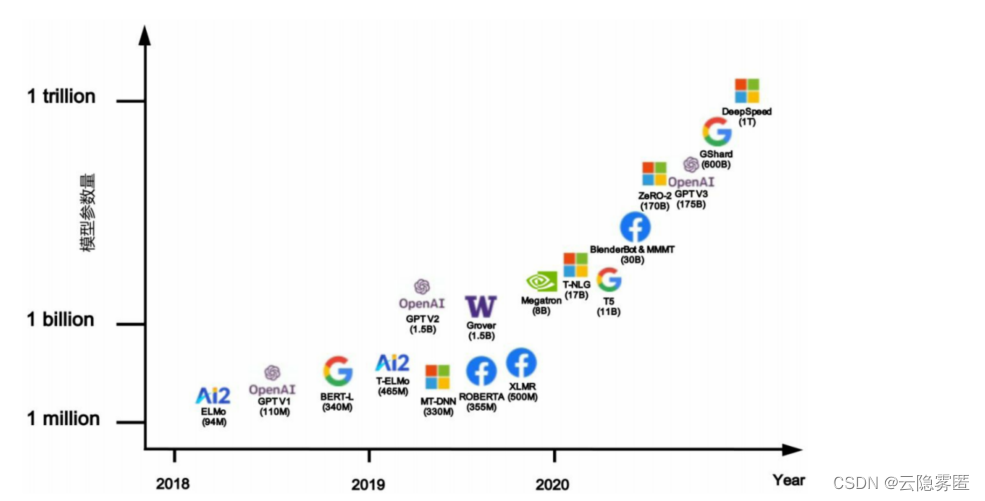
因此,除了优化预训练语言模型的预测精度,如何能够降低预训练语言模型参数量以及加快运行效率也是非常重要的研究方向。目前主流的预训练语言模型压缩方法是知识蒸馏技术。
知识蒸馏
(
Knowledge Distillation,KD)是一种常用的知识迁移方法,通常由教师 (Teacher)模型和学生(Student)模型构成。
知识蒸馏就像老师教学生的过程,将知识从教师模型传递到学生模型,使得学生模型的性能尽量与教师模型接近
。虽然知识蒸馏技术并不要求学生模型的体积(或参数量)一定要比教师模型小,但在实际应用过程中,通常使用该技术将较大的模型压缩到一个较小的模型,同时基本保持原模型的效果。
本文将结合一种十分经典的知识蒸馏模型(
DistilBERT
),简要说明模型的蒸馏与压缩过程。
二、DistilBERT模型介绍
DistilBERT
应用了基于三重损失(Triple Loss)的知识蒸馏方法。相比BERT 模型,DistilBERT 的参数量压缩至原来的40%,同时带来 60%的推理速度提升,并且在多个下游任务上达到BERT模型效果的97%。接下来,针对Dis-tilBERT使用的知识蒸馏方法进行介绍。
2.1 基本结构
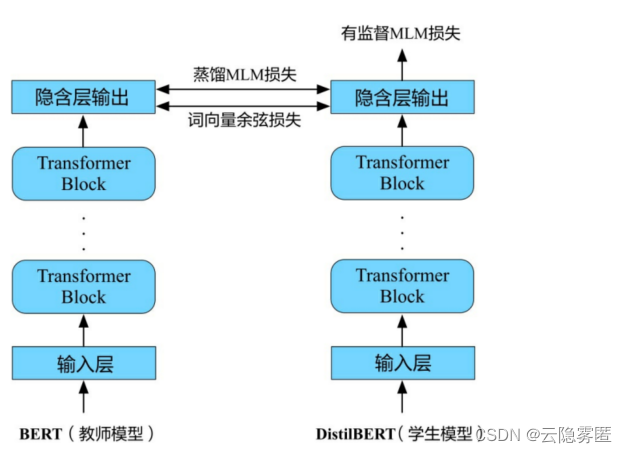
DistilBERT的基本结构如下图所示。学生模型(即DistilBERT)的基本结构是一个六层 BERT 模型,同时去掉了标记类型向量(Token type Embedd-ing)
和池化模块(Pooler)。教师模型是直接使用了原版的BERT-base模型。由于教师模型和学生模型的前六层结构基本相同,为了最大化复用教师模型中的知识,学生模型使用了教师模型的前六层进行初始化。DistilBERT模型的训练方法与常规的BERT训练基本一致,只是在计算损失函数时有所区别,接下来对这部分展开介绍。另外
需要注意的是,DistilBERT只采用了掩码语言模型(MLM)进行预训练,并没有使用预测下一个句子预测(NSP)任务。
2.2 知识蒸馏方法
为了将教师模型的知识传输到学生模型,DistilBERT采用了三重损失:有监督MLM损失、蒸馏MLM损失和词向量余弦损失,如下所示。
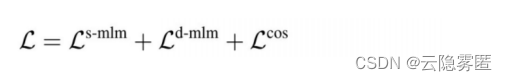
(1)
有监督MLM损失
。
利用掩码语言模型训练得到的损失,即通过输入带有掩码的句子,得到每个掩码位置在词表空间上的概率分布,并利用交叉熵损失函数学习。有监督MLM损失的计算方法为:
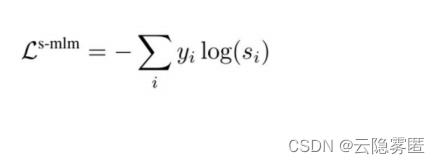
上式中,y
i
表示第 i 个类别的标签;s
i
表示学生模型对该类别的输出概率。
(2)蒸馏MLM损失
。
利用教师模型的概率作为指导信号,与学生模型的概率计算交叉熵损失进行学习。由于教师模型是已经过训练的预训练语言模型,其输出的概率分布相比学生模型更加准确,能够起到一定的监督训练目的。因此,在预训练语言模型的知识蒸馏中,通常将有监督MLM称作
硬标签
(Hard Label)训练方法,将蒸馏MLM称作
软标签
(Soft Label)训练方法。硬标签对应真实的MLM训练标签,而软标签是教师模型输出的概率。蒸馏MLM损失的计算方法为:
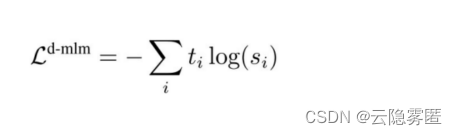
式中,t
i
表示教师模型对第i个类别的输出概率;s
i
表示学生模型对该类别的输出概率。对比上文前两个公式
可以很容易看出有监督MLM损失和蒸馏MLM损失之间的区别。需要注意的是,当计算概率 ti 和 si
时,DistilBERT采用了带有温度系数的Softmax函数。
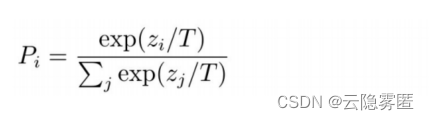
式中,P
i
表示带有温度的概率值(ti
和 s
i
均使用该方法计算);z
i 和 zj
表示未激活的数值;T 表示温度系数。在训练阶段,通常将温度系数设置为T=8。在推理阶段,将温度系数设置为T=1,即还原为普通的 Softmax 函数。
(3)词向量余弦损失
。
词向量余弦损失用来对齐教师模型和学生模型的隐含层向量的方向,从隐含层维度拉近教师模型和学生模型的距离,如下所示:
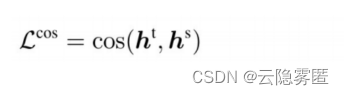
式中,ht 和 hs 分别表示教师模型和学生模型最后一层的隐含层输出。
至此我们对模型的蒸馏和压缩过程有了一个初步的认知,想要深入了解的读者可以自行查阅资料或继续关注作者的其他文章。

















 377
377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









