









ref:https://mp.weixin.qq.com/s?__biz=MzI4MDYzNzg4Mw==&mid=2247489055&idx=2&sn=4b9eaa4ee52201384216dcab7e365d65&chksm=ebb42ecbdcc3a7dd040d7c30fda53ce5ebe591024db8cd8c18fe28eac58977a7ffe7b685c41d&scene=27
一、介绍语言模型
什么是语言模型?简单地说,语言模型就是用来计算一个句子的概率的模型,也就是判断一句话是否合理的概率?说说其应用,一直以来,如何让计算机可以理解我们人类的语言,都是人工智能领域的大问题。而机器翻译,问答系统,语音识别,分词,输入法,搜索引擎的自动补全等也都应用到了语言模型。当然,一开始人们都是进行基于规则的语言模型的研究,但这样往往有很大的问题,后来有人发明了基于统计的语言模型,并发现了其巨大的效果,而今天我们要讲的N-gram语言模型,也正是一种于基于统计的语言模型
N-gram语言模型可以说是当下应用最广的语言模型,当然了,随着深度学习的发展,现在也有用RNN/LSTM这样的神经网络语言模型,效果比N-gram有时候要更好一些,但RNN解码出每一个词都得现算语言模型分数,有较慢的劣势。
二、N-Gram模型详解
既然要做语言模型,基于统计概率来说,我们需要计算句子的概率大小:
P(S) = P(w1,w2,w3,…,wn)
,这个也就是最终要求的一句话的概率了,概率大,说明更合理,概率小,说明不合理,不是人话。。。。
因为是不能直接计算,所以我们先应用条件概率得到
p(w1,w2,…,wn) = p(w1)*p(w2|w1)*p(w3|w1,w2)…p(wn|w1,…,wn-1)
中间插入下条件概率: P(B|A):A 条件下 B 发生的概率。从一个大的空间进入到一个子空间(切片),计算在子空间中的占比。
p(B/A) = P(A,B)/P(A);
然而,如果直接算条件概率转化后的式子的话,对每个词要考虑它前面的所有词,这在实际中意义不大,显然并不好算。那这个时候我们可以添加什么假设来简化吗?可以的,我们可以基于马尔科夫假设来做简化。
什么是马尔科夫假设?
马尔科夫假设是指,每个词出现的概率只跟它前面的少数几个词有关。比如,二阶马尔科夫假设只考虑前面两个词,相应的语言模型是三元模型。引入了马尔科夫假设的语言模型,也可以叫做马尔科夫模型。
马尔可夫链(Markov chain)为状态空间中经过从一个状态到另一个状态的转换的随机过程。该过程要求具备“无记忆”的性质:下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。
也就是说,应用了这个假设表明了当前这个词仅仅跟前面几个有限的词相关,因此也就不必追溯到最开始的那个词,这样便可以大幅缩减上述算式的长度。即式子变成了这样:
p(w1,w2,…,wn) = p(wi|wi-m+1,…,wi-1)
注意:这里的m表示前面m个词相关
然后,我们就可以设置m=1,2,3…得到相应的一元模型,二元模型,三元模型了,关于当m=1,一个一元模型(unigram model)即为:
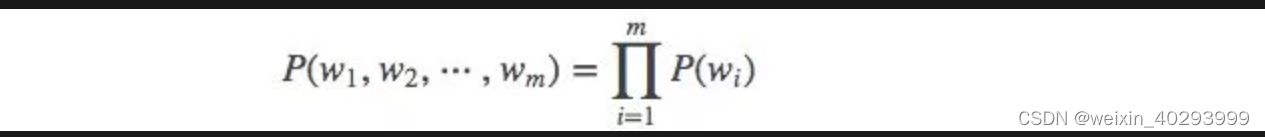
当 m=2, 一个二元模型(bigram model)即为 :
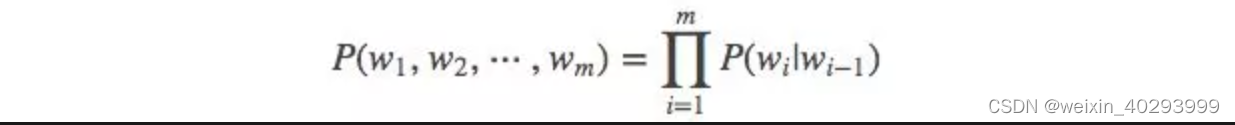
当 m=3, 一个三元模型(trigram model)即为
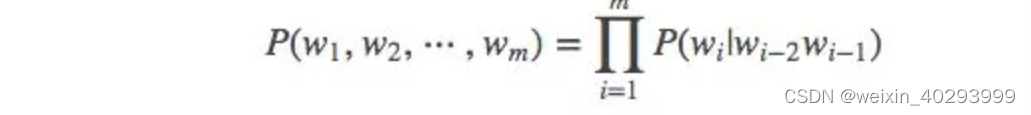
而N-Gram模型也就是这样,当m=1,叫1-gram或者unigram ;m=2,叫2-gram或者bigram ;当 m=3叫3-gram或者trigram ;当m=N时,就表示的是N-gram啦。
说明了什么是N-Gram模型之后,下面说说N-Gram经典应用,同时更深入的理解下:
三、利用N-Gram模型评估语句是否合理
假设现在有一个语料库,我们统计了下面的一些词出现的数量

下面的这些概率值作为已知条件:

p(want|) = 0.25
下面这个表给出的是基于Bigram模型进行计数之结果

例如,其中第一行,第二列 表示给定前一个词是 “i” 时,当前词为“want”的情况一共出现了827次。据此,我们便可以算得相应的频率分布表如下。
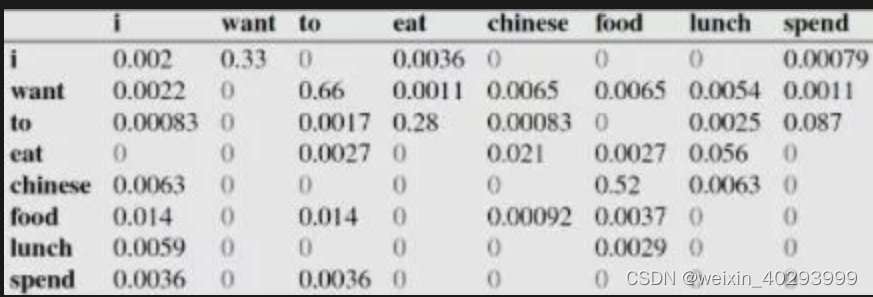
比如说,我们就以表中的p(eat|i)=0.0036这个概率值讲解,从表一得出“i”一共出现了2533次,而其后出现eat的次数一共有9次,p(eat|i)=p(eat,i)/p(i)=count(eat,i)/count(i)=9/2533 = 0.0036
下面我们通过基于这个语料库来判断s1=“ i want english food” 与s2 = " want i english food"哪个句子更合理:
首先来判断p(s1)
P(s1)=P(i|)P(want|i)P(english|want)P(food|english)P(|food)
=0.25×0.33×0.0011×0.5×0.68=0.000031
再来求p(s2)?
P(s2)=P(want|)P(i|want)P(english|want)P(food|english)P(|food)
=0.250.00220.00110.50.68 = 0.00000002057
通过比较我们可以明显发现0.00000002057<0.000031,也就是说s1= "i want english food"更合理。
当然,以上是对于二元语言模型(bigram model)的,大家也可以算下三元,或者1元语言模型的概率,不过结果都应该是一样的。
再深层次的分析,我们可以发现这两个句子的概率的不同,主要是由于顺序i want还是want i的问题,根据我们的直觉和常用搭配语法,i want要比want i出现的几率要大很多。所以两者的差异,第一个概率大,第二个概率小,也就能说的通了。
注意,以上的例子来自网上
四、n-gram 模型其他应用举例
n-gram模型也有其他很多应用,以下一一举例:
1.研究人类文明:n-gram模型催生了一门新学科(Culturomics)的成立,通过数字化的文本,来研究人类行为和文化趋势。《可视化未来》这本书有详细介绍,也可以通过知乎上的问答(https://www.zhihu.com/question/26166417),还有就是TED上的视(https://www.ted.com/talks/what_we_learned_from_5_million_books)
2.搜索引擎:当你在谷歌或者百度的时候,输入一个或几个词,搜索框通常会以下拉菜单的形式给出几个像下图一样的备选,这些备选其实是在猜想你想要搜索的那个词串。如下图:
实际上这些都是根据语言模型得出。比如使用的是二元语言模型预测下一个单词:排序的过程就是:
p(”不一样“|“我们”)>p(”的爱“|“我们”)>p(”相爱吧“|“我们”)>…>p(“这一家”|”我们“),这些概率值的求法和上面提到的完全一样,数据的来源可以是用户搜索的log。
3.输入法:比如输入“zhongguo”,可能的输出有:中国,种过,中过等等…这背后的技术就要用到n-gram语言模型了。item就是每一个拼音对应的可能的字。
…(还有很多,只有有关语言模型,都可以应用)
五、总结
以上就是今天我们了解的所有内容了。当然,对于n-gram,我们可能需要知道语料库的规模越大,做出的n-gram对统计语言模型才更有用,或者n-gram的n大小对性能的影响也是很大的,比如n更大的时候对下一个词出现的约束性信息更多,有更大的辨别力,n更小的时候在训练语料库中出现的次数更多,有更高的可靠性 ,等等,这些有兴趣的童鞋就自己去查查吧,最后推荐一些书籍:
吴军. 2012. 《数学之美》.
关毅. 2007. 哈工大:统计自然语言处理.
fandywang, 2012,《NLP&统计语言模型》.
等等,都有对n-gram或者语言模型的讲述,值得一看的!
















 207
207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









