










前言
我们之前讲过的模型通常聚焦单个任务,比如预测图片的类别等,在训练的时候,我们会关注某一个特定指标的优化.
但是有时候,我们需要知道一个图片,从它身上知道新闻的类型(政治/体育/娱乐)和是男性的新闻还是女性的.
我们关注某一个特定指标的优化,可能忽略了对有关注的指标的有用信息.具体来说就是训练相关任务所带来的额外信息,通过在多个相关任务中共享表示,我们可以使得模型在我们原本任务上获得更好的泛化能力.这种方法就叫做多任务学习.
1.多任务学习
1.1 定义
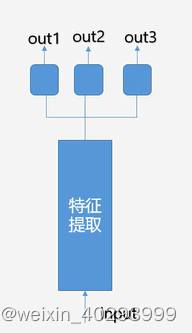
同时完成多个预测,共享表示,共享特征提取.使得模型关注到一些特有的特征.其实一套提取特征的网络,配合多个损失函数,就是多任务损失.
图像定位是单任务,若还需要知道类别,就变成了多任务学习.
1.2 原理
多任务学习的模型通常通过所有任务重共用隐藏层(特征提取层),而针对不同任务使用多个输出层来实现.自动学习到的任务越多,模型就能获得捕捉所有任务的表示,而原本任务上过拟合的风险更小.
多任务学习中,针对一个任务的特征提取,由于其它任务也能对提取的特征做出筛选,所以可以帮助模型将注意力集中到那些真正起作用的特征上.
模型会学习那些尽量表达多个任务的特征,而这些特征泛化能力会很好.
2. 多任务学习code
同时预测一个物品的颜色和类别.
2.1 数据集初探
一个分支用于分类给定输入图像的服装种类(比如衬衫、裙子、牛仔裤、鞋子等);
另一个分支负责分类该服装的颜色(黑色、红色、蓝色等)。
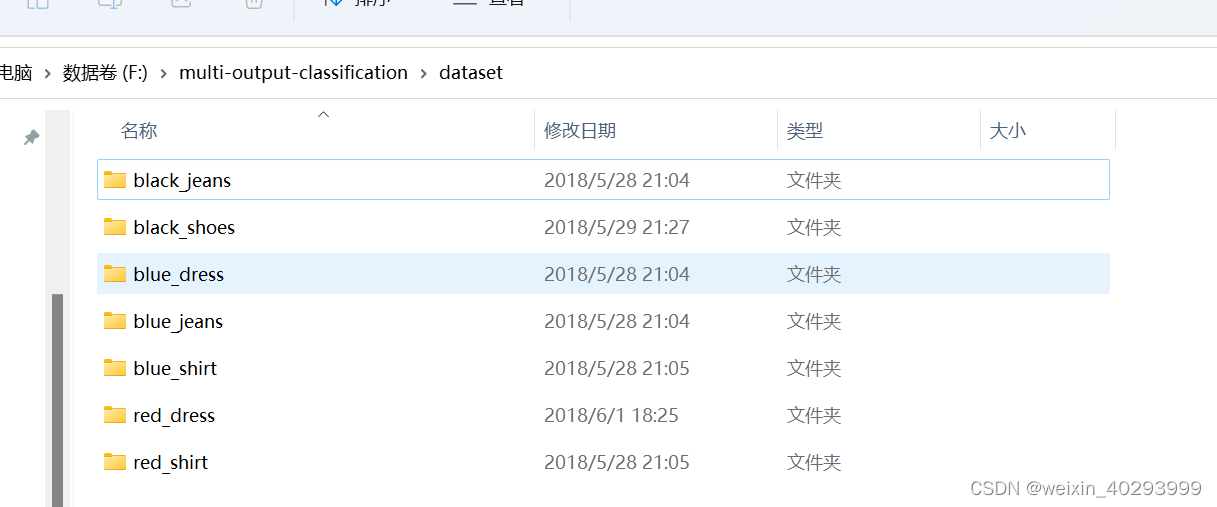
总体而言,我们的数据集由 2525 张图像构成,分为 7 种「颜色+类别」组合,包括:
黑色牛仔裤(344 张图像)
黑色鞋子(358 张图像)
蓝色裙子(386 张图像)
蓝色牛仔裤(356 张图像)
蓝色衬衫(369 张图像)
红色裙子(380 张图像)
红色衬衫(332 张图像)


数据集下载链接:https://pan.baidu.com/s/1JtKt7KCR2lEqAirjIXzvgg 提取码:2kbc
2.2 预处理
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import torchvision
import glob
from torchvision import transforms
from torch.utils import data
from PIL import Image
img_paths = glob.glob(r"F:\multi-output-classification\dataset\*\*.jpg")
img_paths[:5]
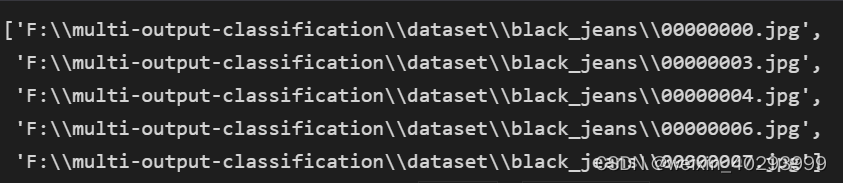
路径文件夹就表示了标签,所以要获取其标签:
label_names = [img_path.split("\\")[-2] for img_path in img_paths]
label_names[:5]

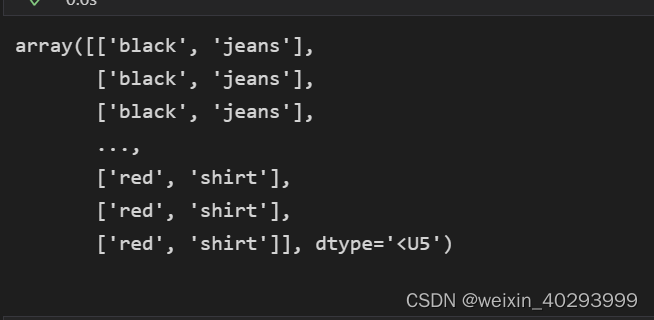
label_array = np.array([la.split("_") for la in label_names])
label_array
label_color = label_array[:,0]
label_color

label_item = label_array[:,1]
label_item

吧他们转成index,因为torch中只认数字
unique_color = np.unique(label_color)
unique_color
unique_item = np.unique(label_item)
unique_item
item_to_idx = dict((v,k) for k, v in enumerate(unique_item))
item_to_idx
color_to_idx = dict((v,k) for k, v in enumerate(unique_color))
color_to_idx
label_item = [item_to_idx.get(k) for k in label_item]
label_color = [color_to_idx.get(k) for k in label_color ]
transform = transforms.Compose([
transforms.Resize((96,96)),
transforms.ToTensor(),
])
自定义数据集
class Multi_dataset(data.Dataset):
def __init__(self,imgs_path, label_color, label_item) -> None:
super().__init__()
self.imgs_path = imgs_path
self.label_color = label_color
self.label_item = label_item
def __getitem__(self, index):
img_path = self.imgs_path[index]
pil_img = Image.open(img_path)
# 防止有图片有黑白图
pil_img = pil_img.convert('RGB')
pil_img = transform(pil_img)
label_c = self.label_color[index]
label_i = self.label_item[index]
return pil_img, (label_c,label_i)
def __len__(self):
return len(self.imgs_path)
划分训练集
count = len(multi_dataset)
count
# 划分训练集 测试集
train_count = int(count*0.8)
test_count = count - train_count
train_ds, test_ds = data.random_split(multi_dataset,[train_count, test_count])
len(train_ds),len(test_ds)
BATCHSIZE = 32
train_dl = data.DataLoader(train_ds,batch_size=BATCHSIZE,shuffle=True)
test_dl = data.DataLoader(test_ds,batch_size=BATCHSIZE)
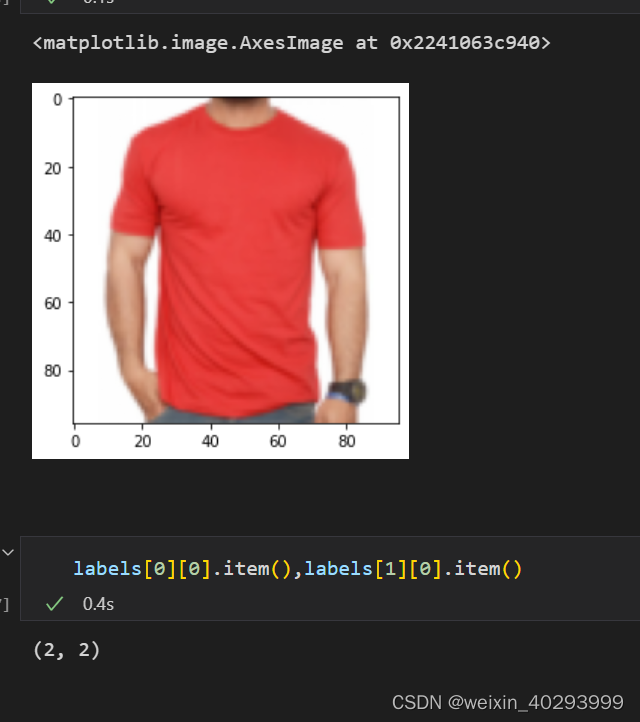
2.3 网络结构设计
## 定义网络
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3,16,3)
self.conv2 = nn.Conv2d(16,32,3)
self.conv3 = nn.Conv2d(32,64,3)
self.fc = nn.Linear(64*10*10, 1024)
self.fc1 = nn.Linear(1024,3)
self.fc2 = nn.Linear(1024,4)
def forward(self,x):
# 3X96X96-->3X48*48--->3X24X24--->3X12X12
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x,2)
x = F.relu(self.conv3(x))
x = F.max_pool2d(x,2)
x = x.view(-1,64*10*10)
c = F.relu(self.fc(x))
i = self.fc2(x)
return c,i
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = Net().to(device)
model
Net(
(conv1): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1))
(conv3): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(fc): Linear(in_features=6400, out_features=1024, bias=True)
(fc1): Linear(in_features=1024, out_features=3, bias=True)
(fc2): Linear(in_features=1024, out_features=4, bias=True)
)
2.4 训练
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0005)
3. 总结
未完待续


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









