










前言
行人重识别是计算机视觉的基本任务之一,首先要有一个detector(检测器来检测到目标),然后将检测到的目标送入到tracker(追踪器)中,完成对相同目标的判别和追踪。
基于此我们可以将这个技术用于:
1.单摄像头车流量、人流量的计算
2.但摄像头的追踪(徘徊检测)
3.跨摄像头的追踪。
很明显,任务3 要难于任务1, 任务2 是任务1的延续,需要引入一点其它技术。
1、知识体系
1.1 前置说明
DeepSort的前身是sort算法,Sort算法的核心是卡尔曼滤波算法和匈牙利算法。
卡尔曼滤波算法作用:是当前的一系列运动变量去预测下一时刻的运动变量,但是第一次的检测结果用来初始化卡尔曼滤波的运动变量。
匈牙利算法:解决分配问题,就是把一群检测框和卡尔曼预测的框做分配,让卡尔曼预测的框找到和自己最匹配的检测框,达到追踪的效果。本质是维护一个状态矩阵,解决预测框的匹配问题。
1.2 Sort的工作流程
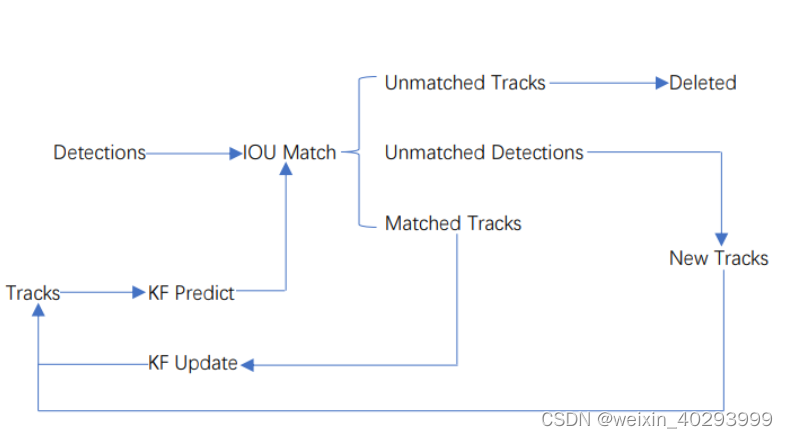
Detections是通过目标检测到的框。Tracks是轨迹信息。
整个算法的工作流程如下:
(1)将第一帧检测到的结果创建其对应的Tracks。将卡尔曼滤波的运动变量初始化,通过卡尔曼滤波预测其对应的框框。
(2)将该帧目标检测的框框和上一帧通过Tracks预测的框框一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(3)将(2)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(4)反复循环(2)-(3)步骤,直到视频帧结束。
印象里这里的预测是线性预测,因为预测器很弱容易产生id switch问题,而且只考虑了运动的关联性特征,没考虑外观特征。这些问题会在deepsort中优化。
1.3 deepsort
。而Deepsort算法在sort算法的基础上增加了级联匹配(Matching Cascade)和新轨迹的确认(confirmed)。Tracks分为确认态(confirmed),和不确认态(unconfirmed),新产生的Tracks是不确认态的;不确认态的Tracks必须要和Detections连续匹配一定的次数(默认是3)才可以转化成确认态。确认态的Tracks必须和Detections连续失配一定次数(默认30次),才会被删除。
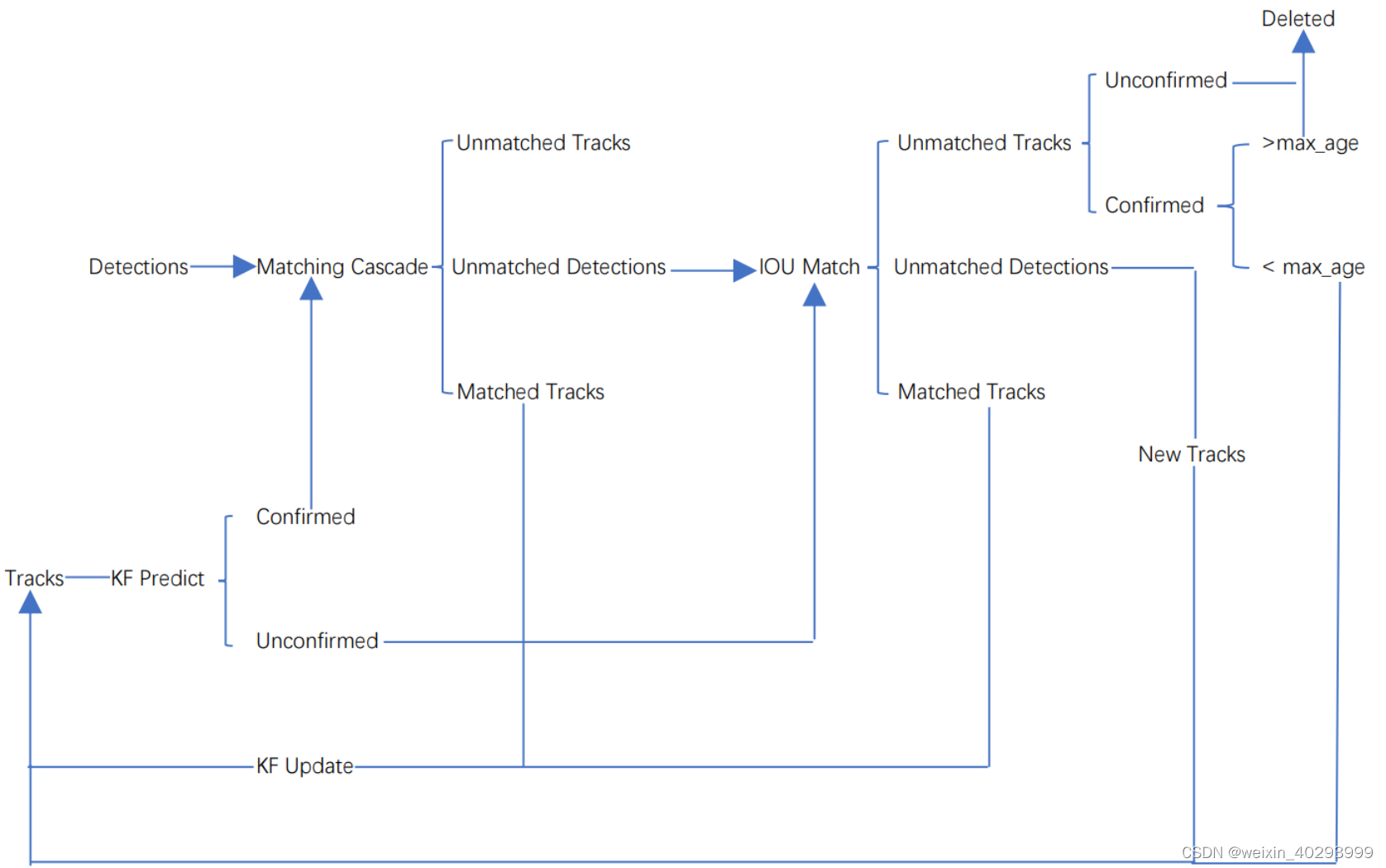
整个算法的工作流程如下:
(1)将第一帧次检测到的结果创建其对应的Tracks。将卡尔曼滤波的运动变量初始化,通过卡尔曼滤波预测其对应的框框。这时候的Tracks一定是unconfirmed的。
(2)将该帧目标检测的框框和第上一帧通过Tracks预测的框框一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(3)将(2)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks(因为这个Tracks是不确定态了,如果是确定态的话则要连续达到一定的次数(默认30次)才可以删除)删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(4)反复循环(2)-(3)步骤,直到出现确认态(confirmed)的Tracks或者视频帧结束。
(5)通过卡尔曼滤波预测其确认态的Tracks和不确认态的Tracks对应的框框。将确认态的Tracks的框框和是Detections进行级联匹配(之前每次只要Tracks匹配上都会保存Detections其的外观特征和运动信息,默认保存前100帧,利用外观特征和运动信息和Detections进行级联匹配,这么做是因为确认态(confirmed)的Tracks和Detections匹配的可能性更大)。
(6)进行级联匹配后有三种可能的结果。第一种,Tracks匹配,这样的Tracks通过卡尔曼滤波更新其对应的Tracks变量。第二第三种是Detections和Tracks失配,这时将之前的不确认状态的Tracks和失配的Tracks一起和Unmatched Detections一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(7)将(6)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks(因为这个Tracks是不确定态了,如果是确定态的话则要连续达到一定的次数(默认30次)才可以删除)删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(8)反复循环(5)-(7)步骤,直到视频帧结束。
2. 实践应用
代码在我的git仓库:https://github.com/justinge/yolov5-deepsort
里面的readyme要看一下,都可以跑的通。 单摄像头的计数很容易的。
还可以配合我之前的文章:https://blog.csdn.net/weixin_40293999/article/details/127811380
3. 干货补充
下面的代码来解析一下,如何实现计数的原理的, 序号 1,2 只是说明了重识别的过程,但没说明计数的原理。

蓝色区域全为 1
黄色区域全为 2
黑色区域全为 0
我以count_person.py 为例子说明这个问题:
import numpy as np
import objtracker
from objdetector import Detector
import cv2
VIDEO_PATH = './video/test_person.mp4'
if __name__ == '__main__':
# 根据视频尺寸,填充供撞线计算使用的polygon
width = 1920
height = 1080
mask_image_temp = np.zeros((height, width), dtype=np.uint8)
# 填充第一个撞线polygon(蓝色)
list_pts_blue = [[204, 305], [227, 431], [605, 522], [1101, 464], [1900, 601], [1902, 495], [1125, 379], [604, 437],
[299, 375], [267, 289]]
ndarray_pts_blue = np.array(list_pts_blue, np.int32)
polygon_blue_value_1 = cv2.fillPoly(mask_image_temp, [ndarray_pts_blue], color=1)
# 增加一个新维度 [height, width, 1]
polygon_blue_value_1 = polygon_blue_value_1[:, :, np.newaxis]
# 填充第二个撞线polygon(黄色)
mask_image_temp = np.zeros((height, width), dtype=np.uint8)
list_pts_yellow = [[181, 305], [207, 442], [603, 544], [1107, 485], [1898, 625], [1893, 701], [1101, 568],
[594, 637], [118, 483], [109, 303]]
ndarray_pts_yellow = np.array(list_pts_yellow, np.int32)
polygon_yellow_value_2 = cv2.fillPoly(mask_image_temp, [ndarray_pts_yellow], color=2)
polygon_yellow_value_2 = polygon_yellow_value_2[:, :, np.newaxis]
# 撞线检测用的mask,包含2个polygon,(值范围 0、1、2),供撞线计算使用
polygon_mask_blue_and_yellow = polygon_blue_value_1 + polygon_yellow_value_2
# 蓝 色盘 b,g,r
blue_color_plate = [255, 0, 0]
# 蓝 polygon图片
blue_image = np.array(polygon_blue_value_1 * blue_color_plate, np.uint8)
# 黄 色盘
yellow_color_plate = [0, 255, 255]
# 黄 polygon图片
yellow_image = np.array(polygon_yellow_value_2 * yellow_color_plate, np.uint8)
# 彩色图片(值范围 0-255)
color_polygons_image = blue_image + yellow_image
# 缩小尺寸,1920x1080->960x540
color_polygons_image = cv2.resize(color_polygons_image, (width//2, height//2))
# list 与蓝色polygon重叠
list_overlapping_blue_polygon = []
# list 与黄色polygon重叠
list_overlapping_yellow_polygon = []
# 下行数量
down_count = 0
# 上行数量
up_count = 0
font_draw_number = cv2.FONT_HERSHEY_SIMPLEX
draw_text_postion = (int((width/2) * 0.01), int((height/2) * 0.05))
# 实例化yolov5检测器
detector = Detector()
# 打开视频
capture = cv2.VideoCapture(VIDEO_PATH)
count_num = 0
while True:
# 读取每帧图片
_, im = capture.read()
if im is None:
break
# 缩小尺寸,1920x1080->960x540
im = cv2.resize(im, (width//2, height//2))
list_bboxs = []
# 更新跟踪器
output_image_frame, list_bboxs = objtracker.update(detector, im)
# 输出图片
output_image_frame = cv2.add(output_image_frame, color_polygons_image)
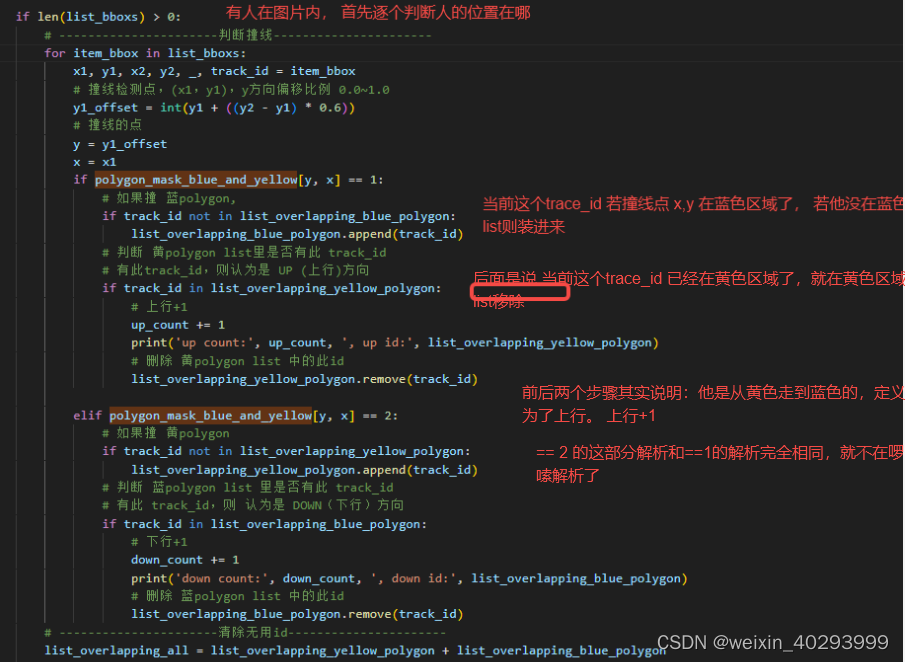
if len(list_bboxs) > 0:
# ----------------------判断撞线----------------------
for item_bbox in list_bboxs:
x1, y1, x2, y2, _, track_id = item_bbox
# 撞线检测点,(x1,y1),y方向偏移比例 0.0~1.0
y1_offset = int(y1 + ((y2 - y1) * 0.6))
# 撞线的点
y = y1_offset
x = x1
if polygon_mask_blue_and_yellow[y, x] == 1:
# 如果撞 蓝polygon,
if track_id not in list_overlapping_blue_polygon:
list_overlapping_blue_polygon.append(track_id)
# 判断 黄polygon list里是否有此 track_id
# 有此track_id,则认为是 UP (上行)方向
if track_id in list_overlapping_yellow_polygon:
# 上行+1
up_count += 1
print('up count:', up_count, ', up id:', list_overlapping_yellow_polygon)
# 删除 黄polygon list 中的此id
list_overlapping_yellow_polygon.remove(track_id)
elif polygon_mask_blue_and_yellow[y, x] == 2:
# 如果撞 黄polygon
if track_id not in list_overlapping_yellow_polygon:
list_overlapping_yellow_polygon.append(track_id)
# 判断 蓝polygon list 里是否有此 track_id
# 有此 track_id,则 认为是 DOWN(下行)方向
if track_id in list_overlapping_blue_polygon:
# 下行+1
down_count += 1
print('down count:', down_count, ', down id:', list_overlapping_blue_polygon)
# 删除 蓝polygon list 中的此id
list_overlapping_blue_polygon.remove(track_id)
# ----------------------清除无用id----------------------
list_overlapping_all = list_overlapping_yellow_polygon + list_overlapping_blue_polygon
for id1 in list_overlapping_all:
is_found = False
for _, _, _, _, _, bbox_id in list_bboxs:
if bbox_id == id1:
is_found = True
if not is_found:
# 如果没找到,删除id
if id1 in list_overlapping_yellow_polygon:
list_overlapping_yellow_polygon.remove(id1)
if id1 in list_overlapping_blue_polygon:
list_overlapping_blue_polygon.remove(id1)
list_overlapping_all.clear()
# 清空list
list_bboxs.clear()
else:
# 如果图像中没有任何的bbox,则清空list
list_overlapping_blue_polygon.clear()
list_overlapping_yellow_polygon.clear()
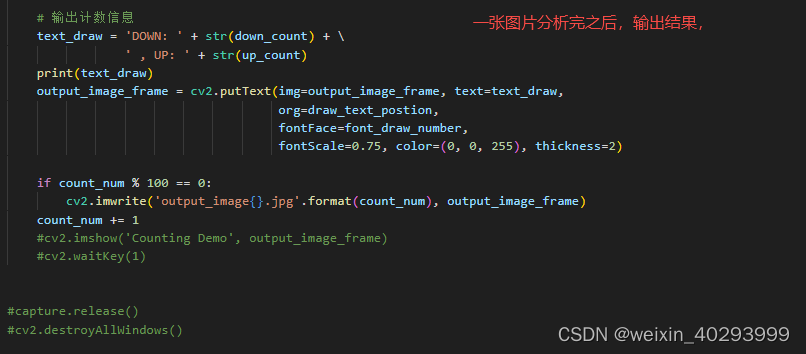
# 输出计数信息
text_draw = 'DOWN: ' + str(down_count) + \
' , UP: ' + str(up_count)
print(text_draw)
output_image_frame = cv2.putText(img=output_image_frame, text=text_draw,
org=draw_text_postion,
fontFace=font_draw_number,
fontScale=0.75, color=(0, 0, 255), thickness=2)
if count_num % 100 == 0:
cv2.imwrite('output_image{}.jpg'.format(count_num), output_image_frame)
count_num += 1
#cv2.imshow('Counting Demo', output_image_frame)
#cv2.waitKey(1)
#capture.release()
#cv2.destroyAllWindows()
while True 之前就是定义了那么三个颜色的mask,
关键是 While True里面
# 更新跟踪器
output_image_frame, list_bboxs = objtracker.update(detector, im)
list_bboxs 这个输出结果要关注一下,是一个列表:
[[x1,y1,x2,y2,‘’,trace_id],..........]
x1,y1, x2,y2 是矩形框的左上和右下角点, trace_id 就是追踪行人的id
在一个大的循环 While True中 对每个人的位置进行遍历:

希望经过上面的分析后,在看下面的图,就容易理解很多了吧
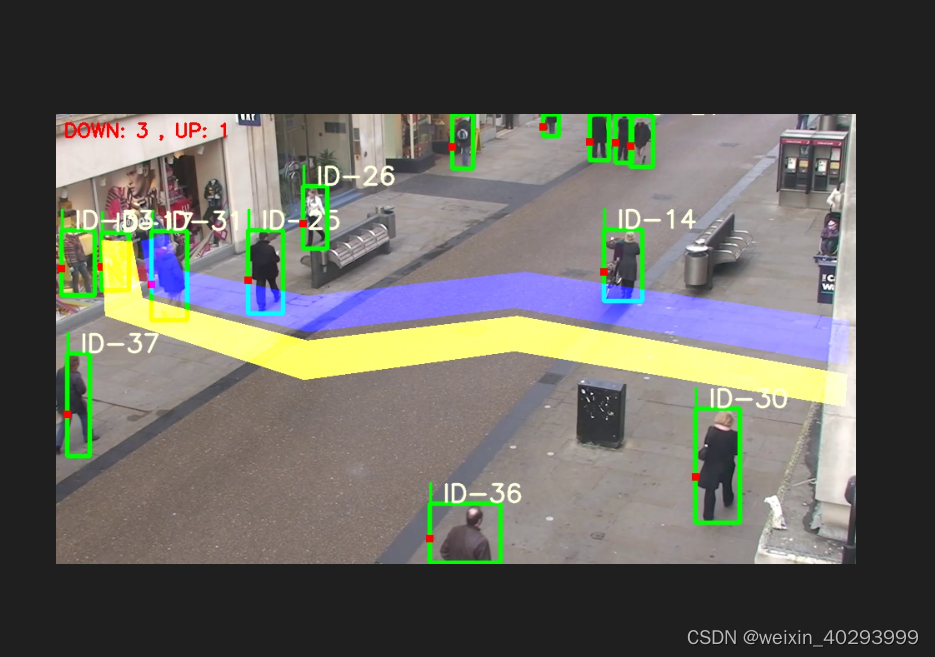
总结
关于跨摄像头的追踪,我还没有想出好办法来,先留个坑。
跨摄像头的追踪 cross domain还是啥,有个专有的名词,是不太行的,是行业不行。搞不定。
通常解决方案是,跨摄像头追踪,追不住。
转成360全景摄像头追的话,太慢。。。一秒拼接不出一张。
又有了新的ByteTrack,检测器需要一个yolov或者ssd之类,然后再进行ByTrack,详见我的另一篇文章。
















 2360
2360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









