







版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/stalbo/article/details/79283399 </div>
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/ck_htmledit_views-cd6c485e8b.css">
<div id="content_views" class="markdown_views prism-atom-one-dark">
<!-- flowchart 箭头图标 勿删 -->
<svg xmlns="http://www.w3.org/2000/svg" style="display: none;">
<path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id="raphael-marker-block" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path>
</svg>
<p>参考资料:<a href="http://blog.csdn.net/sallyxyl1993/article/details/64123922" rel="nofollow" target="_blank">http://blog.csdn.net/sallyxyl1993/article/details/64123922</a> <br>
https://baijiahao.baidu.com/s?id=1580024390078548003&wfr=spider&for=pc
https://sherlockliao.github.io/2017/06/20/gan_math/
http://blog.csdn.net/u011534057/article/details/52840788
GAN背后的思想其实非常朴素和直观,就是生成器和判别器两个极大极小的博弈。下面我们进一步了解该理论背后的证明与推导。
一、基本概念
1.1 符号定义
data→真实数据(groundtruth)data→真实数据(groundtruth)
GG 来自真实数据data而不是生成数据的概率。
1.2 目标函数
GAN的目标函数:
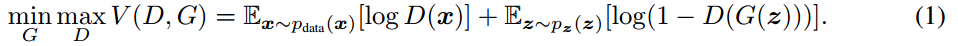
从判别器 DD 尽可能小。两个模型相对抗,最后达到全局最优。
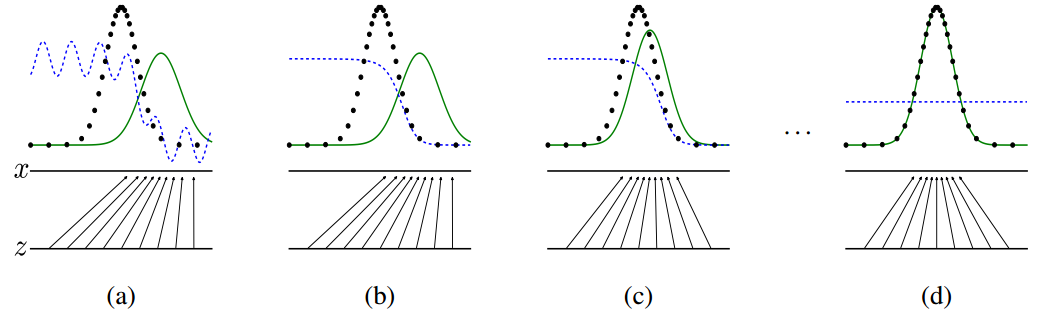
图中,黑色曲线是真实样本的概率分布函数,绿色曲线是虚假样本的概率分布函数,蓝色曲线是判别器D的输出,它的值越大表示这个样本越有可能是真实样本。最下方的平行线是噪声z,它映射到了x。
我们可以看到,一开始, 虽然 G(z)G(z) 虽然也在不断更新,但也已经力不从心了。
最后,黑线和绿线最后几乎重合,模型达到了最优状态,这时 DD。
二、最优化问题表达
定义最优化问题的方法由两部分组成。首先我们需要定义一个判别器 D 以判别样本是不是从 Pdata(x)Pdata(x) 分布中取出来的,因此有:
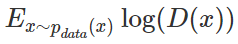
其中 E 指代取期望。这一项是根据「正类」(即辨别出 x 属于真实数据 data)的对数损失函数而构建的。最大化这一项相当于令判别器 D 在 x 服从于 data 的概率密度时能准确地预测 D(x)=1,即:

另外一项是企图欺骗判别器的生成器 G。该项根据「负类」的对数损失函数而构建,即:
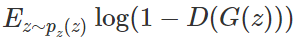
我们定义目标函数为:
对于 D 而言要尽量使公式最大化(识别能力强),而对于 G 又想使之最小(生成的数据接近实际数据)。整个训练是一个迭代过程。其实极小极大化博弈可以分开理解,即在给定 G 的情况下先最大化 V(D,G)V(D,G) 之间的差异或距离。
最后,我们可以将最优化问题表达为:
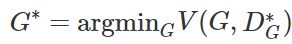
上文给出了 GAN 概念和优化过程的形式化表达。通过这些表达,我们可以理解整个生成对抗网络的基本过程与优化方法。当然,有了这些概念我们完全可以直接在 GitHub 上找一段 GAN 代码稍加修改并很好地运行它。但如果我们希望更加透彻地理解 GAN,更加全面地理解实现代码,那么我们还需要知道很多推导过程。比如什么时候 D 能令价值函数 V(D,G)V(D,G) 取最小值,而 D 和 G 该用什么样的神经网络(或函数),它们的损失函数又需要用什么等等。总之,还有很多理论细节与推导过程需要我们进一步挖掘。
三、理论推导
3.1 知识预备——KL散度
要进行接下来的理论推导,我们首先需要一点预备知识,KL散度(KL divergence),这是统计中的一个概念,是衡量两种概率分布的相似程度,其越小,表示两种概率分布越接近。
对于离散的概率分布,定义如下:
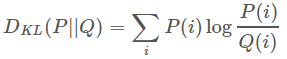
对于连续的概率分布,定义如下:
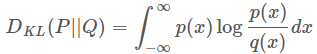
我们想要将一个随机高斯噪声z通过一个生成网络G得到一个和真的数据分布 Pdata(x)Pdata(x) 尽可能接近。
Maximun Likelihood Estimation
我们从真实数据分布 Pdata(x)Pdata(x) 个样本数据的似然(likelihood)就是:
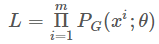
我们想要做的事情就是找到 θ∗θ∗ 来最大化这个似然估计:
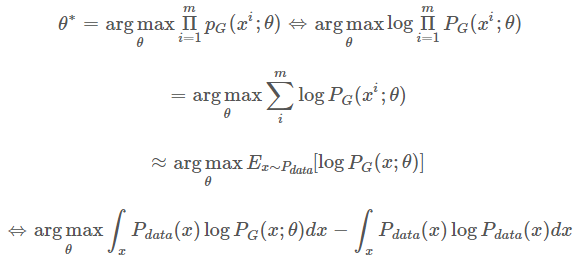
在上面的推导中,我们希望最大化似然函数 LL。
又因为该最优化过程是针对 θθ。添加该积分后,我们可以合并这两个积分并构建类似 KL 散度的形式。该过程如下:
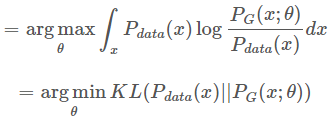
这里在前面添加一个负号,将 log 里面的分数倒一下,就变成了KL 散度:
而 PG(x;θ)PG(x;θ) 如何算出来呢?
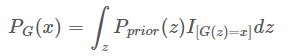
里面的I表示示性函数,也就是:
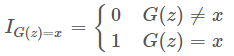
这样我们其实根本没办法求出这个 PG(x)PG(x) 出来,这就是生成模型的基本想法。
3.2 Global Optimality of pg=pdatapg=pdata
下面,我们需要证明:该最优化问题有唯一解 G∗G∗。
Basic Idea of GAN
- 生成器 G:
G 是一个生成器,给定先验分布 Pprior(z)Pprior(z) 之间的差距,这是用来取代极大似然估计
最优判别器
在极小极大博弈的第一步中,给定生成器 G,最大化 V(D,G)V(D,G) 上的积分,即将数学期望展开为积分形式:
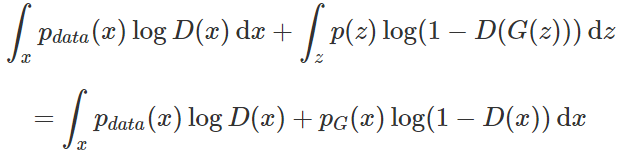
关于上面积分式的证明
在 GAN 原论文中,有一个思想和其它很多方法都不同,即生成器 G 不需要满足可逆条件。Scott Rome 认为这一点非常重要,因为实践中 G 就是不可逆的。而很多证明笔记都忽略了这一点,他们在证明时错误地使用了积分换元公式,而积分换元却又恰好基于 G 的可逆条件。Scott 认为证明只能基于以下等式的成立性:
该等式来源于测度论中的 Radon-Nikodym 定理。
有一些证明过程使用了积分换元公式,但进行积分换元就必须计算 G(−1)G(−1),而 G 的逆却并没有假定为存在。并且在神经网络的实践中,它也并不存在。可能这个方法在机器学习和统计学文献中太常见了,因此我们忽略了它。
在数据给定,G 给定的前提下, Pdata(x)Pdata(x) 来表示他们,这样我们就可以得到如下的式子:
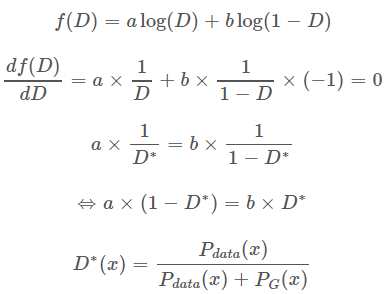
由此,我们得到论文中的第一个推论:
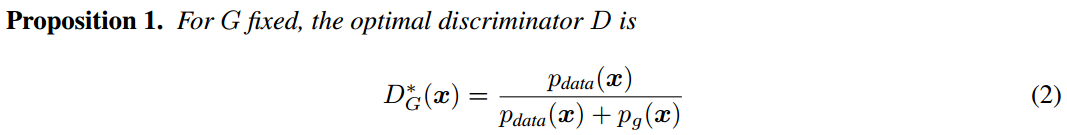
其实该最优的 D 在实践中并不是可计算的,但在数学上十分重要。我们并不知道先验的 Pdata(x)Pdata(x),所以我们在训练中永远不会用到它。另一方面,它的存在令我们可以证明最优的 G 是存在的,并且在训练中我们只需要逼近 D。
最优生成器
当然 GAN 过程的目标是令 PG=PdataPG=Pdata 的表达式中:
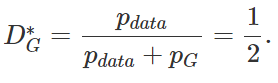
这意味着判别器已经完全困惑了,它完全分辨不出 PdataPdata。基于这一观点,GAN 作者证明了 G 就是极小极大博弈的解。该定理如下:
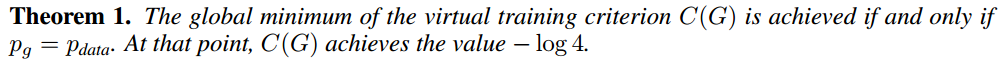
即当且仅当 PG=PdataPG=Pdata 的可以达到全局最优。
以上定理即极大极小博弈的第二步,求令 V(G,D∗)V(G,D∗) 等于零,这一过程的详细解释如下。
原论文中的这一定理是「当且仅当」声明,所以我们需要从两个方向证明。首先我们先从反向逼近并证明














 418
418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









