







 pdist2 是 MATLAB 中用于计算两组观测之间的成对距离的函数。它可以计算欧氏距离、Minkowski 距离等,并支持自定义距离函数。通过设置不同的参数,可以获取最小或最大的成对距离及其对应的观测索引。该函数广泛应用于数据处理和聚类分析中。
pdist2 是 MATLAB 中用于计算两组观测之间的成对距离的函数。它可以计算欧氏距离、Minkowski 距离等,并支持自定义距离函数。通过设置不同的参数,可以获取最小或最大的成对距离及其对应的观测索引。该函数广泛应用于数据处理和聚类分析中。
pdist2
两组观测之间的成对距离
句法
D = pdist2(X,Y,Distance,DistParameter)
[D,I] = pdist2(___,Name,Value)
描述
D = pdist2(X,Y,Distance)X和Y使用Distance.
D = pdist2(X,Y,Distance,DistParameter)Distance和DistParameter。您可以指定DistParameter只有当Distance是'seuclidean', 'minkowski',或'mahalanobis'.
D = pdist2(___,Name,Value)'Smallest'或'Largest'除了以前语法中的任何参数之外。
例如,
-
D = pdist2(X,Y,Distance,'Smallest',K)指定的度量计算距离。Distance并返回K与观测的最小成对距离X中的每一次观察Y按升序排列。 -
D = pdist2(X,Y,Distance,DistParameter,'Largest',K)指定的度量计算距离。Distance和DistParameter并返回K按降序排列的最大成对距离。
[还返回矩阵。D,I] = pdist2(___,Name,Value)I。矩阵I中的观测结果的索引。X对应于D.
实例
计算欧氏距离
用三个观察和两个变量创建两个矩阵。
rng('default') % For reproducibility
X = rand(3,2);
Y = rand(3,2);
计算欧氏距离。输入参数的默认值。Distance是'euclidean'。当不使用名称-值对参数计算欧几里德距离时,不需要指定Distance.
D = pdist2(X,Y)
D = 3×3
0.5387 0.8018 0.1538
0.7100 0.5951 0.3422
0.8805 0.4242 1.2050
D(i,j)对应于观察之间的成对距离i在……里面X和观察j在……里面Y.
计算Minkowski距离
用三个观察和两个变量创建两个矩阵。
rng('default') % For reproducibility
X = rand(3,2);
Y = rand(3,2);
用默认指数2计算Minkowski距离。
D1 = pdist2(X,Y,'minkowski')
D1 = 3×3
0.5387 0.8018 0.1538
0.7100 0.5951 0.3422
0.8805 0.4242 1.2050
计算Minkowski距离,其指数为1,等于城市块距离。
D2 = pdist2(X,Y,'minkowski',1)
D2 = 3×3
0.5877 1.0236 0.2000
0.9598 0.8337 0.3899
1.0189 0.4800 1.7036
D3 = pdist2(X,Y,'cityblock')
D3 = 3×3
0.5877 1.0236 0.2000
0.9598 0.8337 0.3899
1.0189 0.4800 1.7036
找到两个最小的成对距离
用三个观察和两个变量创建两个矩阵。
rng('default') % For reproducibility
X = rand(3,2);
Y = rand(3,2);
找到两个最小的两两欧几里得距离X中的每一次观察Y.
[D,I] = pdist2(X,Y,'euclidean','Smallest',2)
D = 2×3
0.5387 0.4242 0.1538
0.7100 0.5951 0.3422
I = 2×3
1 3 1
2 2 2
中的每一次观察Y, pdist2通过计算并将距离值与X。的每个列中的距离排序。D按升序排列。I中的观测结果的索引。X对应于D.
使用自定义距离函数计算缺少元素的成对距离
定义一个自定义距离函数,该函数忽略NaN值,并使用自定义距离函数计算成对的距离。
用三个观察和三个变量创建两个矩阵。
rng('default') % For reproducibility
X = rand(3,3)
Y = [X(:,1:2) rand(3,1)]
X =
0.8147 0.9134 0.2785
0.9058 0.6324 0.5469
0.1270 0.0975 0.9575
Y =
0.8147 0.9134 0.9649
0.9058 0.6324 0.1576
0.1270 0.0975 0.9706
X和Y的前两列是相同的。假设X(1,1)丢失了。
X(1,1) = NaN
X =
NaN 0.9134 0.2785
0.9058 0.6324 0.5469
0.1270 0.0975 0.9575
计算汉明距离。
D1 = pdist2(X,Y,'hamming')
D1 =
NaN NaN NaN
1.0000 0.3333 1.0000
1.0000 1.0000 0.3333
中频观测i在……里面X或观察j在……里面Y含NaN值,函数pdist2回报NaN对于两两之间的距离i和j。因此,D1(1,1),D1(1,2)和D1(1,3)是NaN价值。
定义自定义距离函数nanhamdist忽略坐标的NaN值并计算Hamming距离。当处理大量的观测时,您可以通过遍历数据的坐标来更快地计算距离。
function D2 = nanhamdist(XI,XJ)
%NANHAMDIST Hamming distance ignoring coordinates with NaNs
[m,p] = size(XJ);
nesum = zeros(m,1);
pstar = zeros(m,1);
for q = 1:p
notnan = ~(isnan(XI(q)) | isnan(XJ(:,q)));
nesum = nesum + ((XI(q) ~= XJ(:,q)) & notnan);
pstar = pstar + notnan;
end
D2 = nesum./pstar;
用nanhamdist的输入参数传递函数句柄。pdist2.
D2 = pdist2(X,Y,@nanhamdist)
D2 =
0.5000 1.0000 1.0000
1.0000 0.3333 1.0000
1.0000 1.0000 0.3333
向现有集群分配新数据并生成C/C++代码
此示例使用:
执行k-均值聚类
使用三个发行版生成培训数据集。
rng('default') % For reproducibility
X = [randn(100,2)*0.75+ones(100,2);
randn(100,2)*0.5-ones(100,2);
randn(100,2)*0.75];
使用kmeans.
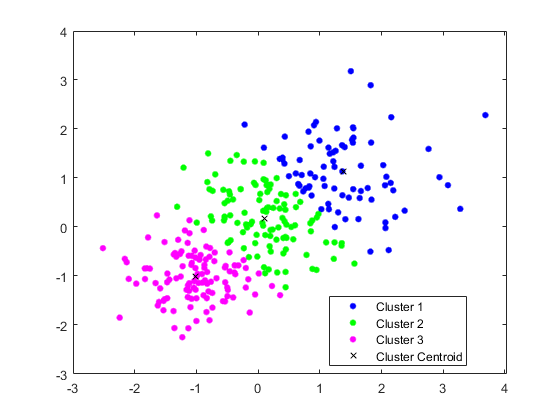
[idx,C] = kmeans(X,3);
绘制星系团和星系团质心图。
figure
gscatter(X(:,1),X(:,2),idx,'bgm')
hold on
plot(C(:,1),C(:,2),'kx')
legend('Cluster 1','Cluster 2','Cluster 3','Cluster Centroid')
将新数据分配给现有集群
生成测试数据集。
Xtest = [randn(10,2)*0.75+ones(10,2);
randn(10,2)*0.5-ones(10,2);
randn(10,2)*0.75];
使用现有集群对测试数据集进行分类。从每个测试数据点查找最近的质心,使用pdist2.
[~,idx_test] = pdist2(C,Xtest,'euclidean','Smallest',1);
绘制测试数据并使用idx_test用gscatter.
gscatter(Xtest(:,1),Xtest(:,2),idx_test,'bgm','ooo')
legend('Cluster 1','Cluster 2','Cluster 3','Cluster Centroid', ...
'Data classified to Cluster 1','Data classified to Cluster 2', ...
'Data classified to Cluster 3')

输入参数
X,Y — 输入数据
数值矩阵
输入数据,指定为数字矩阵。X是MX-按-n矩阵和Y是我的-按-n矩阵。行对应于单独的观察,列对应于单个变量。
数据类型:single | double
Distance — 距离度量
字符向量 | 串标量 | 功能手柄
距离度量,指定为字符向量、字符串标量或函数句柄,如下表所述。
| 价值 | 描述 |
|---|---|
'euclidean' | 欧几里德距离(默认)。 |
'squaredeuclidean' | 平方欧氏距离(本选项仅为提高效率而提供。它不满足三角形不等式。 |
'seuclidean' | 标准化欧氏距离观测值之间的每个坐标差除以标准差的对应元素, |
'mahalanobis' | 使用样本协方差的Mahalanobis距离 |
'cityblock' | 城市街区距离。 |
'minkowski' | 明考斯基距离。默认指数为2。 |
'chebychev' | 切比切夫距离(最大坐标差) |
'cosine' | 1减去点间夹角的余弦(作为向量处理)。 |
'correlation' | 1减去点之间的样本相关性(作为值的序列处理)。 |
'hamming' | Hamming距离,即不同坐标的百分比。 |
'jaccard' | 1减去Jaccard系数,这是不同的非零坐标的百分比。 |
'spearman' | 其中一项减去样本Spearman之间的秩相关性(作为值的序列处理)。 |
@ | 自定义距离函数句柄。距离函数具有以下形式 function D2 = distfun(ZI,ZJ) % calculation of distance ...哪里
如果数据不稀疏,通常可以使用内置距离而不是函数句柄来更快地计算距离。 |
有关定义,请参见距离度量.
当你使用'seuclidean', 'minkowski',或'mahalanobis',您可以指定一个附加的输入参数。DistParameter来控制这些指标。您还可以使用这些指标的方式与默认值为DistParameter.
例子: 'minkowski'
DistParameter — 距离度量参数值
正标量 | 数值向量 | 数值矩阵
距离度量参数值,指定为正标量、数字向量或数字矩阵。此参数仅在您指定Distance如'seuclidean', 'minkowski',或'mahalanobis'.
-
如果
Distance是'seuclidean',DistParameter是每个维度的缩放因子的向量,指定为正向量。默认值是nanstd(.X) -
如果
Distance是'minkowski',DistParameter是Minkowski距离的指数,表示为正标量。默认值为2。 -
如果
Distance是'mahalanobis',DistParameter是一个协方差矩阵,指定为数字矩阵。默认值是nancov(X).DistParameter必须是对称的和正定的。
例子: 'minkowski',3
数据类型:single | double
名称值对参数
指定可选的逗号分隔对Name,Value争论。Name是参数名和Value对应的值。Name必须出现在引号中。可以将多个名称和值对参数按任何顺序指定为Name1,Value1,...,NameN,ValueN.
例子:任一'Smallest',K或'Largest',K。你不能同时使用'Smallest'和'Largest'.
'Smallest' — 要查找的最小距离数
正整数
要查找的最小距离数,指定为由'Smallest'以及一个正整数。如果您指定'Smallest',然后pdist2的每一列中的距离排序。D按升序排列。
例子:'Smallest',3
数据类型:single | double
'Largest' — 要查找的最大距离数
正整数
要查找的最大距离数,指定为由'Largest'以及一个正整数。如果您指定'Largest',然后pdist2的每一列中的距离排序。D按降序排列。
例子:'Largest',3
数据类型:single | double
D-成对距离
数值矩阵
成对距离,返回为数字矩阵。
如果您没有指定'Smallest'或'Largest',然后D是MX-按-我的矩阵,其中MX和我的中的观察数X和Y分别。D(i,j)是观察之间的距离i在……里面X和观察j在……里面Y。中频观测i在……里面X或观察j在……里面Y含NaN,然后D(i,j)是NaN内建距离函数。
如果您指定'Smallest'或'Largest'如K,然后D是K-按-我的矩阵。D包含K最小的或最小的K与观测的最大成对距离X中的每一次观察Y。中的每一次观察Y, pdist2发现K的最小或最大距离,通过计算和比较的距离值与所有的观测X。如果K大于MX, pdist2返回MX-按-我的矩阵。
I-排序索引
正整数矩阵
排序索引,作为正整数矩阵返回。I是和D. I中的观测结果的索引。X对应于D.

















 981
981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









