









本文对图像语义分割近年来的主要发展做一个综述性的介绍。
翻译了以下两篇博文,并进行了整合。
https://www.jeremyjordan.me/semantic-segmentation/
http://blog.qure.ai/notes/semantic-segmentation-deep-learning-review
转载地址:https://blog.csdn.net/Biyoner/article/details/82591370
- 语义分割的定义
语义分割是计算机视觉中十分重要的领域,它是指像素级地识别图像,即标注出图像中每个像素所属的对象类别。下图为语义分割的一个实例,其目标是预测出图像中每一个像素的类标签。
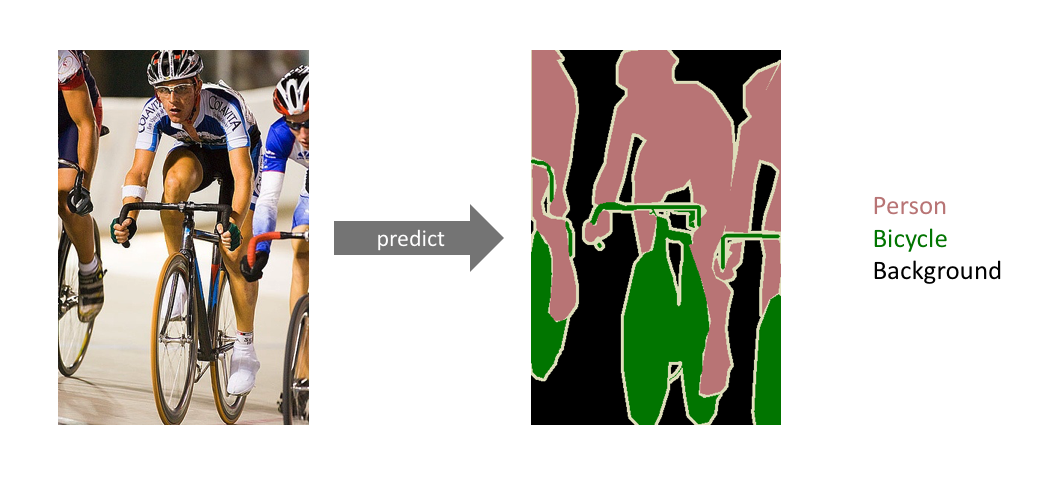
这里需要和实例分割区分开来。它没有分离同一类的实例;我们关心的只是每个像素的类别,如果输入对象中有两个相同类别的对象,则 分割本身不将他们区分为单独的对象。
常见的应用包括:
- 自动驾驶汽车:我们需要为汽车增加必要的感知,以了解他们所处的环境,以便自动驾驶的汽车可以安全行驶;下图为自动驾驶过程中实时分割道路场景;

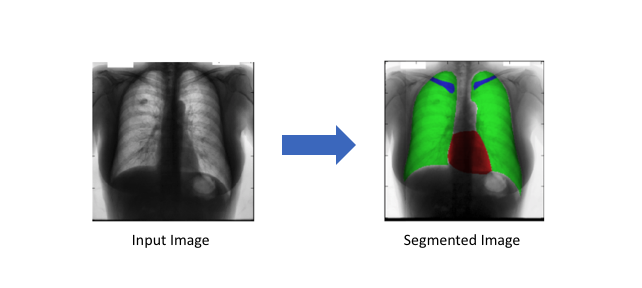
- 医学图像诊断:机器可以增强放射医生进行的分析,大大减少了运行诊断测试所需的时间;下图是胸部X光片的分割,心脏(红色),肺部(绿色以及锁骨(蓝色);
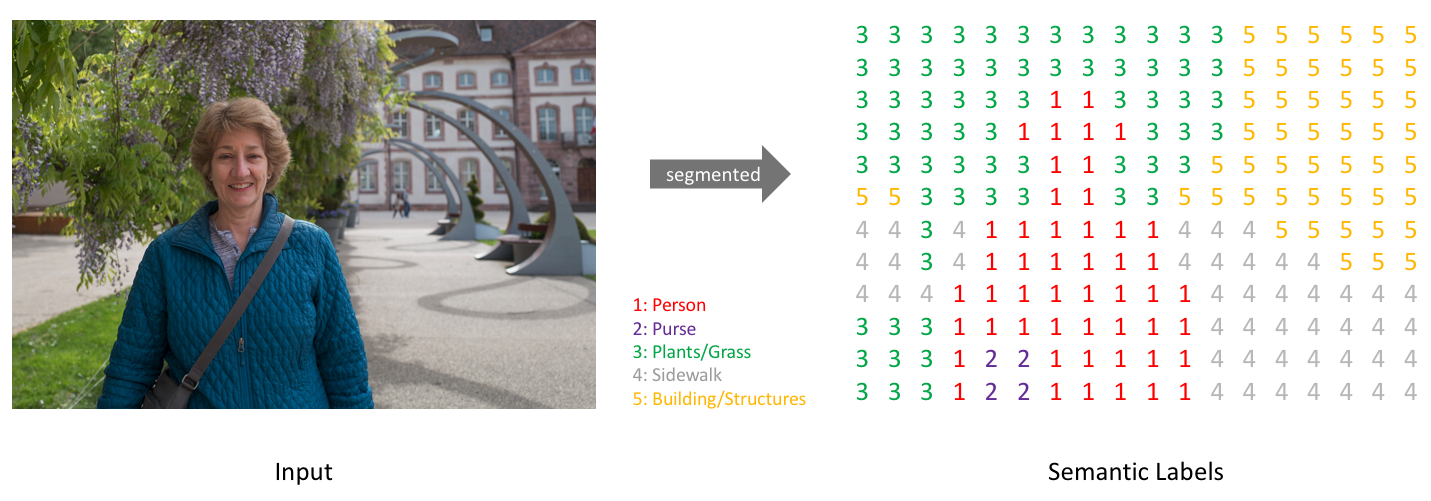
简单来说,分割的目标一般是将一张RGB图像(height*width*3)或是灰度图(height*width*1)作为输入,输出的是分割图,其中每一个像素包含了其类别的标签(height*width*1). 为了清晰起见,使用了低分辨率的预测图,但实际上分割图的分辨率应与原始输入的分辨率相匹配。
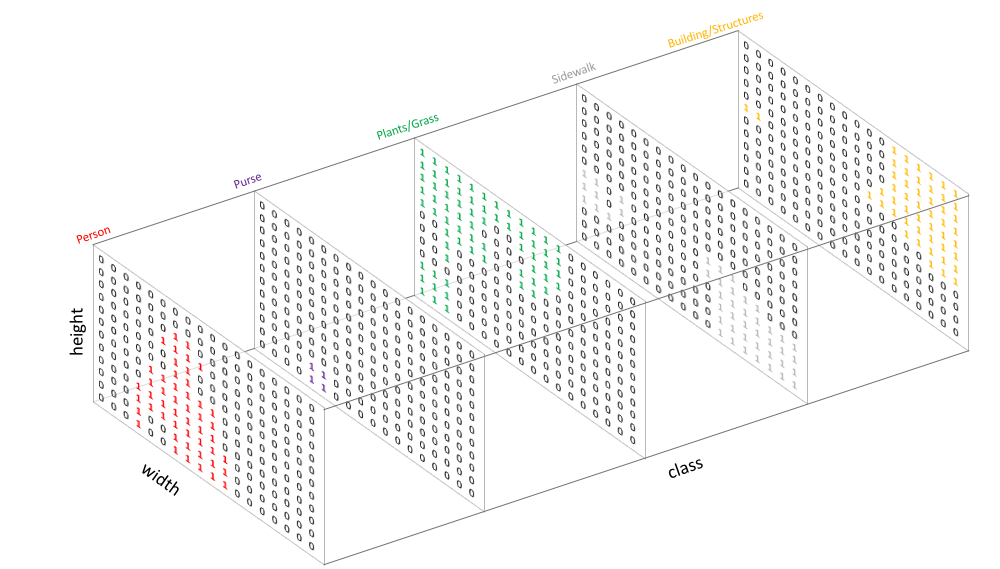
其中,与处理标准分类值的方式类似,我们使用one-hot编码对类标签进行处理,实质上是为每个可能的类创建相应的输出通道。
one-hot 编码可查看https://www.cnblogs.com/daguankele/p/6595470.html, 包括意义及方法。
最后,可以通过argmax将每个深度方向像素矢量折叠成分割图,我们可以通过将它覆盖在原图上,它会照亮图像中存在特定类的区域,以便观测(mask)。

2. 方法综述
在深度学习应用到计算机视觉领域之前,人们使用 TextonForest 和 随机森林分类器进行语义分割。卷积神经网络(CNN)不仅对图像识别有所帮助,也对语义分割领域的发展起到巨大的促进作用。
语义分割任务最初流行的深度学习方法是图像块分类(patch classification),即利用像素周围的图像块对每一个像素进行独立的分类。使用图像块分类的主要原因是分类网络通常是全连接层(full connected layer),且要求固定尺寸的图像。
2014 年,加州大学伯克利分校的 Long等人提出全卷积网络(FCN),这使得卷积神经网络无需全连接层即可进行密集的像素预测,CNN 从而得到普及。使用这种方法可生成任意大小的图像分割图,且该方法比图像块分类法要快上许多。之后,语义分割领域几乎所有先进方法都采用了该模型。
除了全连接层,使用卷积神经网络进行语义分割存在的另一个大问题是池化层。池化层虽然扩大了感受野、聚合语境,但因此造成了位置信息的丢失。但是,语义分割要求类别图完全贴合,因此需要保留位置信息。 有两种不同结构来解决该问题。 第一个是编码器--解码器结构。编码器逐渐减少池化层的空间维度,解码器逐步修复物体的细节和空间维度。编码器和解码器之间通常存在快捷连接,因此能帮助解码器更好地修复目标的细节。U-Net是这种方法中最常用的结构。 第二种方法使用空洞/带孔卷积(dilated/atrous convolutions)结构,来去除池化层。
- encoder-decoder 结构的提出
针对语义分割任务构建神经网络架构的最简单的方法是简单地堆叠多个卷积层(使用same填充以保留需要的维度)并输出最终的分割图。这通过特征映射的连续变换直接学习从输入图像到其对应分割的映射。但在整个网络中保持全分辨率的计算成本非常高。
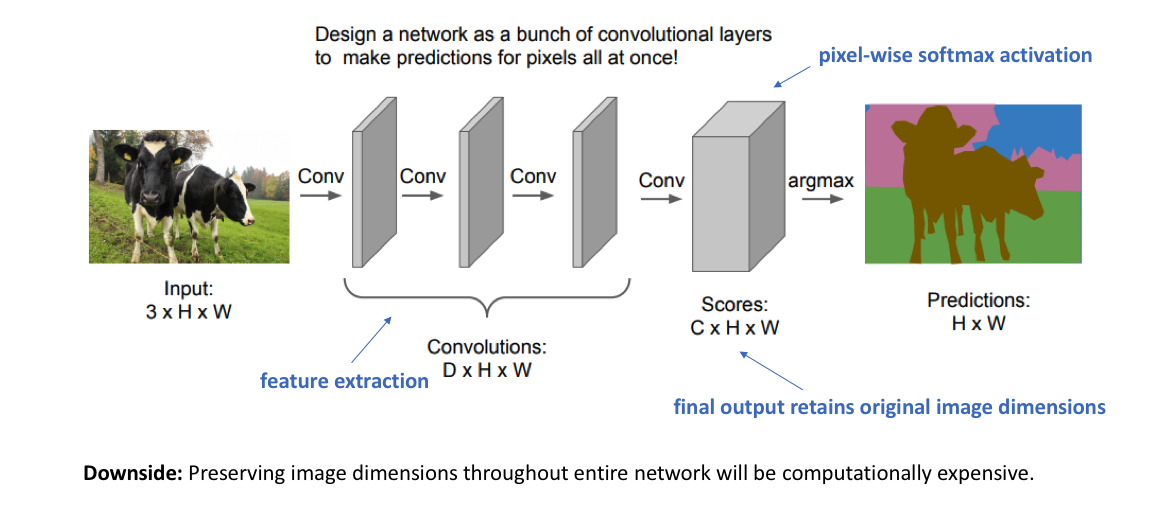
对于深度卷积网络,浅层主要学习低级的信息,随着网络越深,学习到更高级的特征映射。为了保持表达能力,我们通常需要增加特征图的数量(通道数),从而可以得到更深的网络。对于图像分类来说,由于我们只关注图像“是什么”(而不是位置在哪),因而我们可以通过阶段性对特征图降采样(downsampling)或者带步长的卷积(例如,压缩空间分辨率)。然而对于图像分割,我们希望我们的模型产生全分辨率语义预测。
图像分割领域现在较为流行的是编码器/解码器结构,其中我们对输入的空间分辨率进行下采样,生成分辨率较低的特征映射,它能高效地进行分类。随后,上采样可以将特征还原为全分辨率分割图。
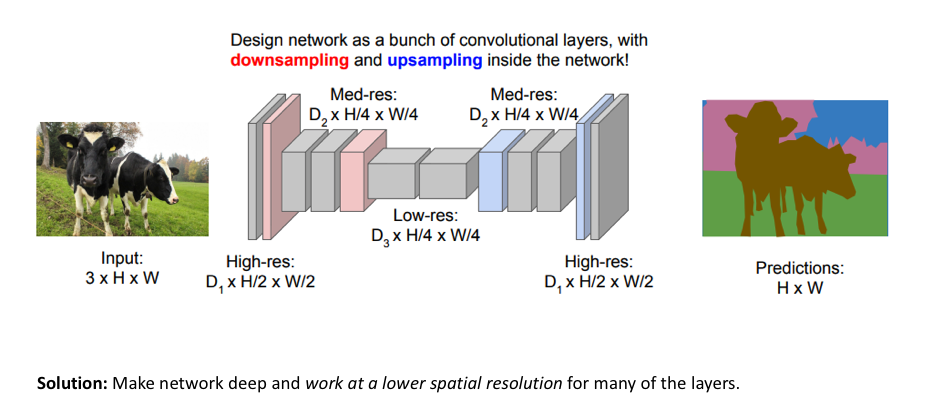
- 上采样的方法
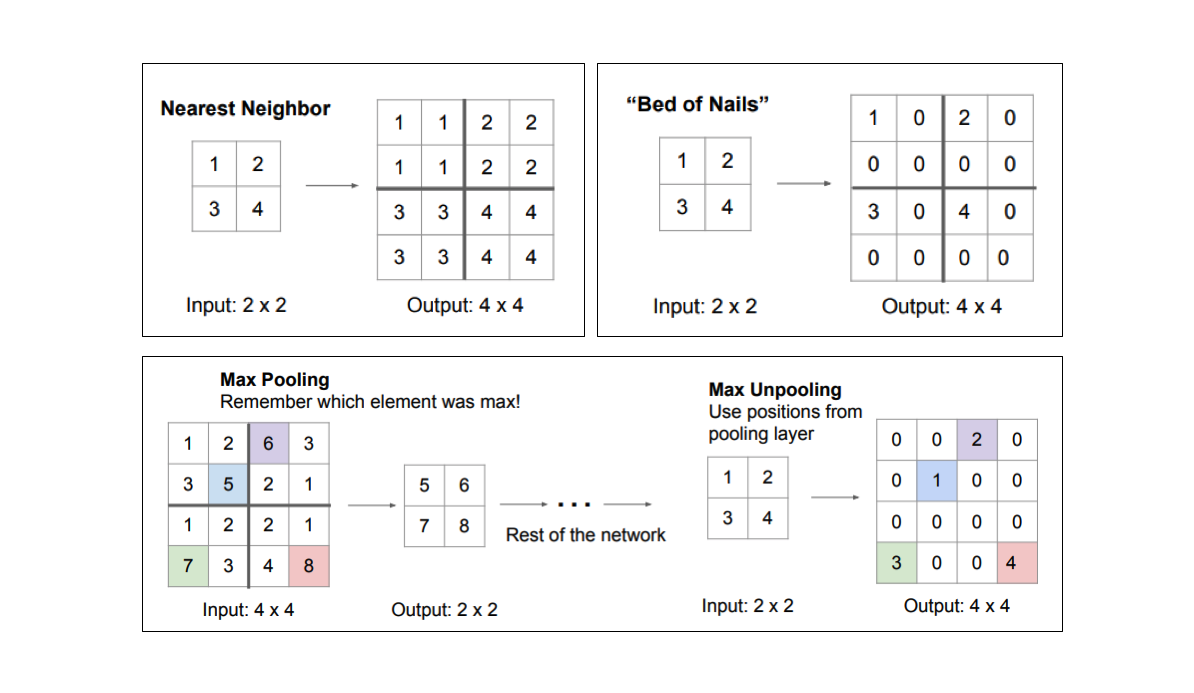
我们有许多方法可以对特征图进行上采样。池化操作通过对将小区域的值取成单一值(例如平均或最大池化)进行下采样,同样的,上池化操作就是将单一值分配到更高的分辨率进行上采样。
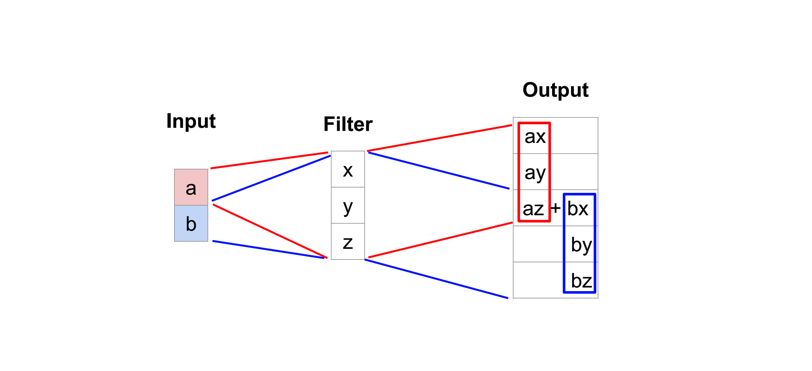
其中,转置卷积是迄今为止最流行的方法,因为它允许我们使用可学习的上采样。
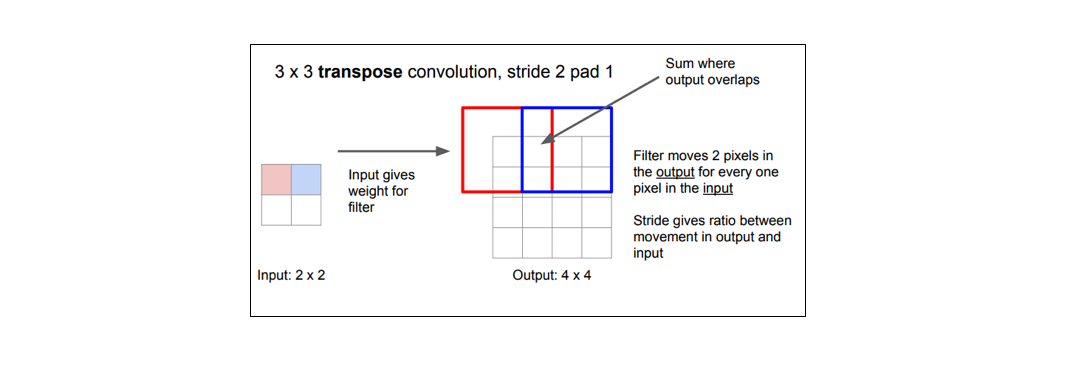
典型的卷积运算将采用滤波器视图中当前值的点积并为相应的输出位置产生单个值,而转置卷积基本上相反。对于转置卷积,我们从低分辨率特征图中获取单个值,并将滤波器中的所有权重乘以该值,将这些加权值投影到输出要素图中。
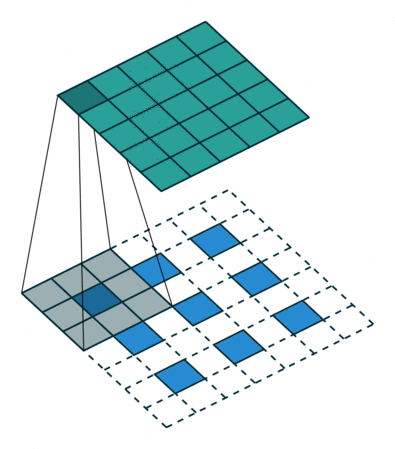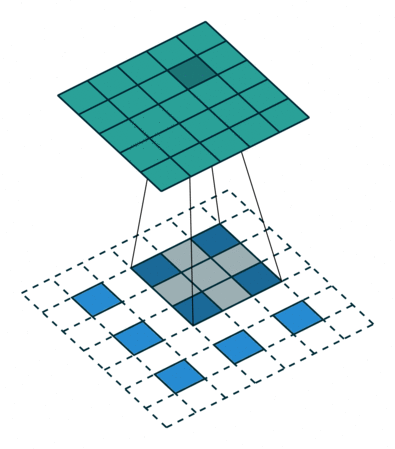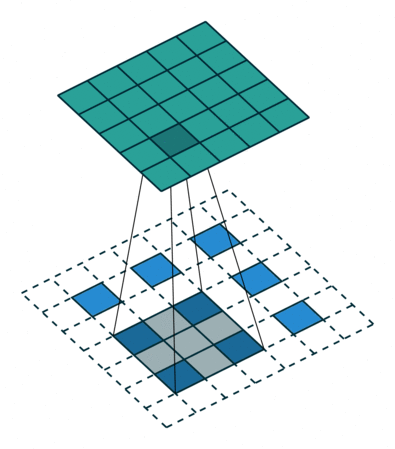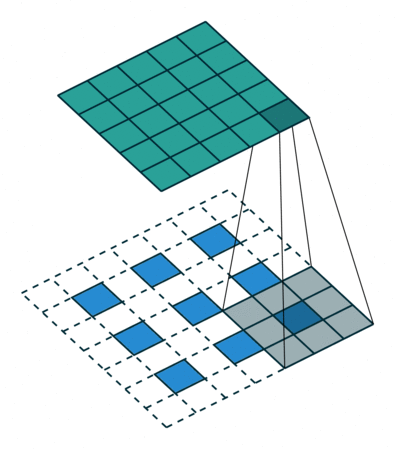
对于某些大小的滤波器会在输出特征映射中产生重叠(例如,具有步幅2的3x3滤波器 - 如下面的示例所示),若将重叠值简单地加在一起,这往往会在输出中产生棋盘格子状的伪影(artifact)。

这并不是我们需要的,因此最好确保您的滤镜大小不会产生重叠。















 1681
1681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









