







 本文详细介绍了梯度提升树(GBDT)算法,从基础的决策树开始,深入到提升树(Boosting Tree)概念,然后重点讲解了GBDT在回归和分类问题上的应用,包括残差近似和负梯度作为残差的计算方法。GBDT作为一种强大的机器学习方法,既能处理分类任务也能处理回归任务,但训练过程难以并行化。
本文详细介绍了梯度提升树(GBDT)算法,从基础的决策树开始,深入到提升树(Boosting Tree)概念,然后重点讲解了GBDT在回归和分类问题上的应用,包括残差近似和负梯度作为残差的计算方法。GBDT作为一种强大的机器学习方法,既能处理分类任务也能处理回归任务,但训练过程难以并行化。
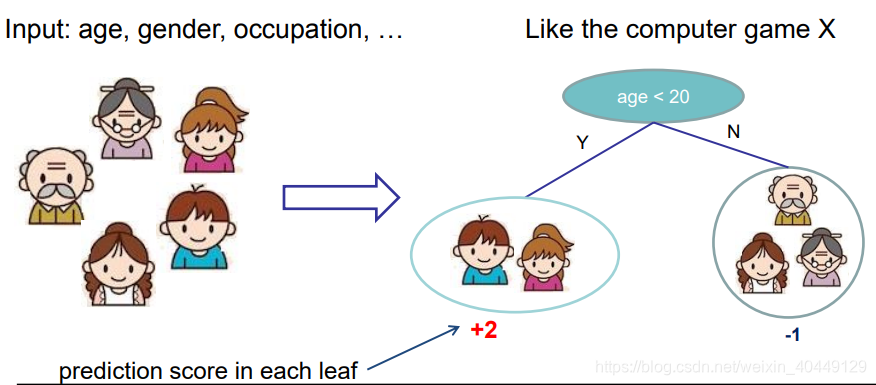
上篇我们对boosting家族中的Adaboost算法进行了总结,本篇我们来探讨传统的梯度提升树(Gradient Boosting Decison Tree)算法。梯度提升树被认为是统计学习中性能最好的方法之一。
梯度提升树(GBDT)全称为Gradient Boosting Decison Tree,顾名思义,包含两部分内容:Gradient Boosting和Decison Tree。本篇我们首先Decison Tree进行简要回顾;然后探讨提升树算法;再重点探讨回归与分类问题对应的GBDT算法;最后对梯度提升树算法优缺点进行简单的总结。
1)Decision Tree
在决策树(Decision Tree)算法原理总结中我们了解到,决策树的基本结构(如下图),决策树由节点和有向的边组成,节点按所处在决策树的位置可以分为根节点,中间节点和叶子节点。其中每个节点代表一个属性,每个分支代表一个决策(规则),每个叶子代表一个结果(分类值或连续值)。
决策树根据选择最优特征的标准不同,可以分为ID3,C4.5,CART决策树,其中CART决策树是前面两种算法的改进。CART决策树既可以处理分类任务,又可以处理回归任务,但决策树存在容易过拟合的缺点。因此,有了提升模型的泛化能力的随机森林算法。
那么,有没有其他的一种方法,在不改变原有模型的参数结构基础上提升模型的泛化能力呢?
既然不能更改原来模型的参数,那么意味着必须在原来模型的基础之上做改善,正好可以利用boosting的思想对决策树进行提升。这就是我们下面要探讨的提升树算法(Boosting Tree)。
2)Decision Tree Ensemble——提升树(Boosting Tree)
如果我们选择以决策树为boosting框架的基学习器,那么这便是提升树(boosting tree)。对于分类问题决策树是二叉分类树,对于回归问题决策树是二叉回归树。
在AdaBoost算法原理详细总结我们解释了,boosting方法采用加法模型与前向分布算法。因此,提升树模型可以表示:
f M ( x ) = ∑ m = 1 M g m ( x ) f_M(x)=\sum_{m=1}^Mg_m(x) fM(x)=m=1∑Mgm(x)
其中, g m ( x ) g_m(x) gm(x)表示第 m m m颗决策树, M M M表示为决策树的颗数。
对于数据集 D = { ( x i , y i ) } i = 1 n D=\left\{ (x_i,y_i) \right\}^n_{i=1} D={
(xi,yi)}i=1n, x i ∈ R d x_i\in R^d xi∈Rd,提升树训练的目标就是最小化损失 ∑ i = 1 n L ( y i , f M ( x i ) ) \sum_{i=1}^n L(y_i,f_M(x_i)) ∑i=1nL(yi,fM(xi)),即
a r g m i n ∑ i = 1 n L ( y i , f M ( x i ) ) = a r g m i n ∑ i = 1 n L ( y i , ∑ m = 1 M g m ( x ) ) argmin\sum_{i=1}^n L(y_i,f_M(x_i))=argmin\sum_{i=1}^nL(y_i,\sum_{m=1}^Mg_m(x)) argmini=1∑nL(yi,fM(xi))=argmini=1∑nL(yi,m=1∑Mgm(x))
对于不同问题的提升树算法,主要区别在于使用的损失函数不同。对于分类问题,损失函数一般有对数损失和指数损失;对于回归问题,损失函数一般有平方误差损失,绝对值损失,Huber损失。
对于二元分类情况下,采用指数损失时,提升树变成基学习器为分类树的Adaboost算法,可参考上篇AdaBoost算法原理详细总结第4部分。
下面我们探讨回归问题提升算法。
首先确定初始提升树 f 0 ( x ) = 0 f_0(x)=0 f0(x)=0
根据前向分步算法,第 m m m步的模型为:
f m ( x ) = f m − 1 ( x ) + g m ( x ) f_m(x) = f_{m-1}(x) + g_m(x) fm(x)=fm−1(x)+gm(x)
在 m m m次迭代中,算法的目标是找到一个基学习器 g m ( x ) g_{m}(x) gm(x)使得损失最小,即:
a r g m i n ∑ i = 1 n L ( y i , f m − 1 ( x i ) + g m ( x ) ) argmin\sum_{i=1}^n L(y_i,f_{m-1}(x_i)+g_m(x)) argmini=1∑nL(yi,fm−1(xi)+gm(x))
生成第 m m m颗决策树 g m ( x ) g_m(x) gm(x)。
当采用平方误差损失时,决策树拟合的就是残差。
L ( y , f m − 1 ( x ) + g m ( x ) ) L(y,f_{m-1}(x)+g_m(x)) L(y,fm−1(x)+gm(x))
= ( y − f m − 1 ( x ) − g m ( x ) ) 2 =(y - f_{m-1}(x)-g_m(x))^2 =(y−fm−1(x)−gm(x))2
= ( r − g m ( x ) ) 2 =(r-g_m(x))^2 =(r−gm(x))2
其中, r = y − f m − 1 ( x ) r=y-f_{m-1}(x) r=y−fm−1(x)为模型拟合数据的残差。所以,对于回归问题的提升树算法,只需要拟合当前模型的残差,即 { ( x 1 , y 1 − f m − 1 ( x 1 ) ) , ( x 2 , y 2 − f m − 1 ( x 2 ) ) , . . . ( x n , y n − f m − 1 ( x n ) } \left\{(x_1,y_1-f_{m-1}(x_1)), (x_2,y_2-f_{m-1}(x_2)),...(x_n,y_n-f_{m-1}(x_n)\right\} {
(x1,y1−fm−1(x1)),(x2,y2−fm−1(x2)),...(xn,yn−fm−1(xn)}。
下面对回归问题提升树算法过程进行总结:
输入: 训练数据集 D = { ( x i , y i ) } i = 1 n D=\left\{ (x_i,y_i) \right\}^n_{i=1} D={
(xi,yi)}i=1n, x i ∈ R d x_i\in R^d xi∈Rd
输出:回归提升树 h M ( x ) h_M(x) hM(x)
- 初始化 f 0 ( x ) = 0 f_0(x)=0 f0(x)=0;
- f o r m = 1 , 2... M : for \ m =1,2...M: for m=1,2...M:
- 对于每一个样本 ( x i , y i ) (x_i,y_i) (xi,yi),计算残差 :
r m , i = y i − f m − 1 ( x i ) , i = 1 , 2... n r_{m,i}=y_i-f_{m-1}(x_i),i=1,2...n rm,i=yi−fm−1(xi
- 对于每一个样本 ( x i , y i ) (x_i,y_i) (xi,yi),计算残差 :
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 647
647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









