







一、前言
2013年,Bengio等人发表了关于表示学习的综述。最近拜读了一下,要读懂这篇论文还有很多文献需要阅读。组会上正好报了这篇,所以在此做一个总结。
鉴于大家都想要我的汇报PPT,那我就分享给大家,希望能对大家有所帮助。
链接:https://pan.baidu.com/s/1agzlbWy5RLf1zZ7Ojduvvg
提取码:196p
二、表示学习发展由来
当我们学习一个复杂概念时,总想有一条捷径可以化繁为简。机器学习模型也不例外,如果有经过提炼的对于原始数据的更好表达,往往可以使得后续任务事倍功半。这也是表示学习的基本思路,即找到对于原始数据更好的表达,以方便后续任务(比如分类)。人工智能——>机器学习——>深度学习发展经历了一个波折上升的过程,越来越多的模型被发明出来,但想要好的表示效果,还得看数据,数据质量好,数据特征好才是王道。
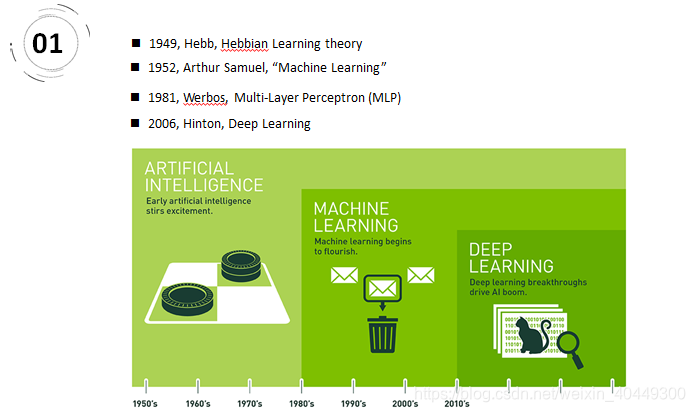
- 赫布于1949年基于神经心理的提出了一种学习方式,该方法被称之为赫布学习理论。2、1952,IBM科学家亚瑟·塞缪尔开发了一个跳棋程序。该程序能够通过观察当前位置,并学习一个隐含的模型,从而为后续动作提供更好的指导。提出机器学习。3、伟博斯在1981年的神经网络反向传播(BP)算法中具体提出多层感知机模型。重新点燃机器学习之火。4、神经网络研究领域领军者Hinton在2006年提出了神经网络Deep Learning算法,使神经网络的能力大大提高,向支持向量机发出挑战。
“数据决定了机器学习的上限,而算法只是尽可能逼近这个上限”,这里的数据指的就是经过特征工程得到的数据。特征工程就是一个把原始数据转变成特征的过程,这些特征可以很好的描述这些数据,并且利用它们建立的模型在未知数据上的表现性能可以达到最优(或者接近最佳性能)。从数学的角度来看,特征工程就是去设计输入变量X。
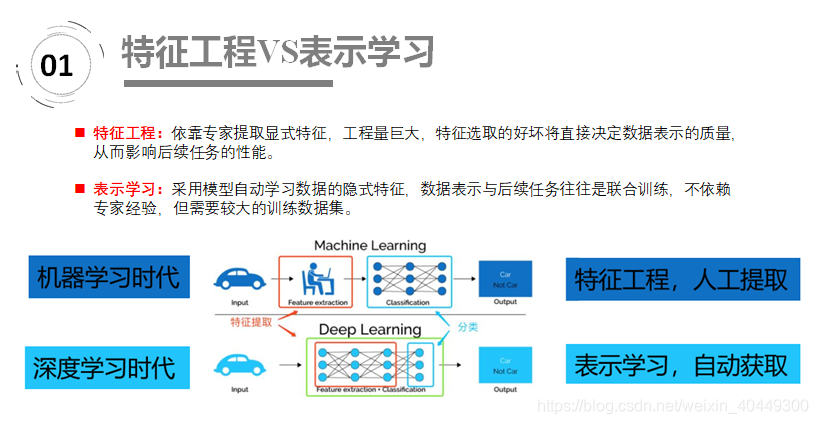
在机器学习时代,我们如果需要对汽车进行表示,往往依靠的是领域专家手工提取特征并表示;在深度学习时代,我们直接将汽车输入模型,汽车将自动转换成高效有意义的表示。
2019年3月27日 ——ACM宣布,深度学习的三位创造者Yoshua Bengio, Yann LeCun, 以及Geoffrey Hinton获得了2019年的图灵奖。
三、论文结构
本文回顾非监督特征学习和深度学习领域的一些近期工作,包括概率模型的发展、自动编码机、流行学习和深度网络。
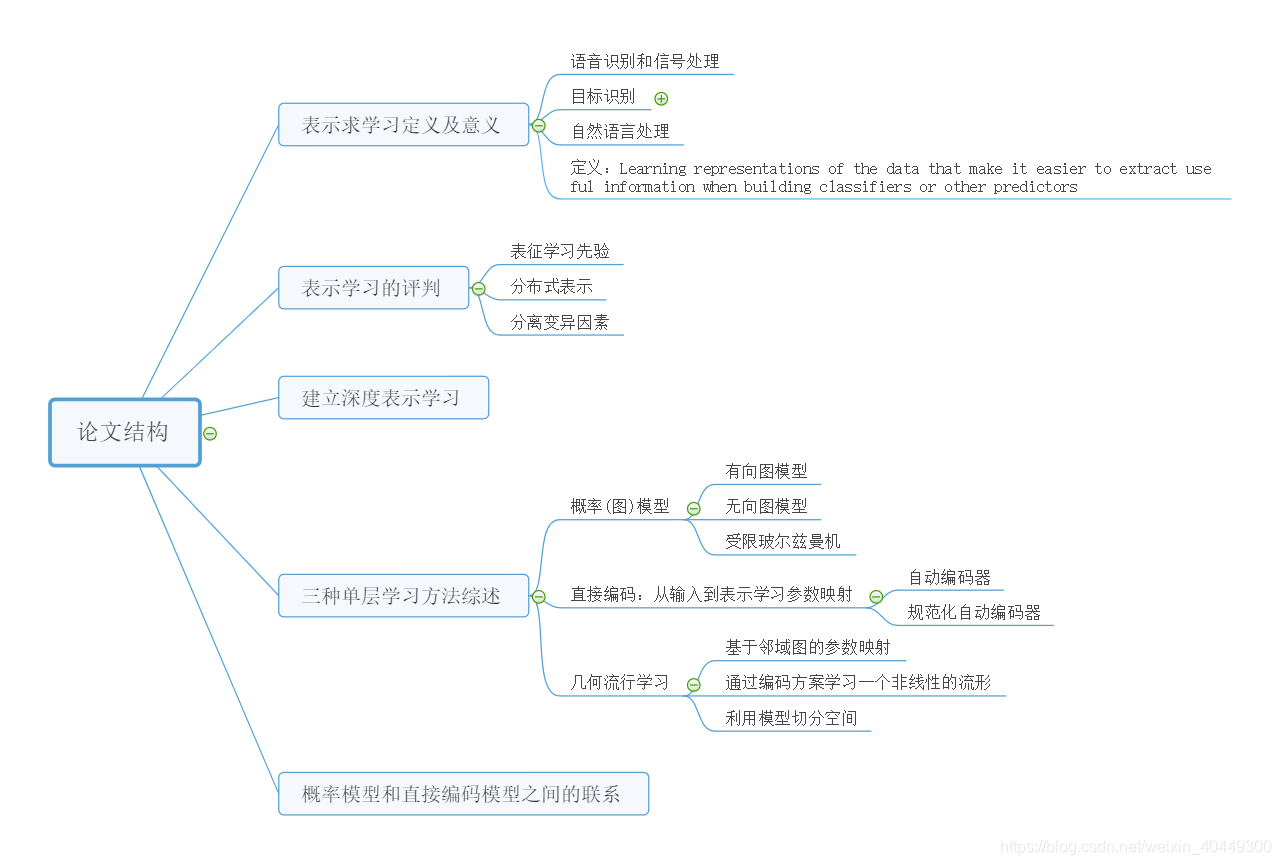
定义:Learning representations of the data that make it easier to extract useful information when building classifiers or other predictors。翻译:表示学习以便在构建分类器或其他预测器时更容易提取有用的信息。
分布式表示(distributed representation). 这是深度学习最重要的性质。举一个非常简单的例子,假设我们的词典上有16个词,如果用传统的bag-of-words 的表示方法,我们可以用16维的向量来表示每个词,向量的每一位代表某个词的出现与否。然而,如果我们用分布式表示的思想,我们也可以用四维的向量来代表每一个词,例如(0,0,0,1), (0,0,1,0),..., (1,1,1,1) 。 这个简单的例子其实用来说明:对同一个输入,我们可以有不同的配置(configuration)。
四、三种单层表示学习方法
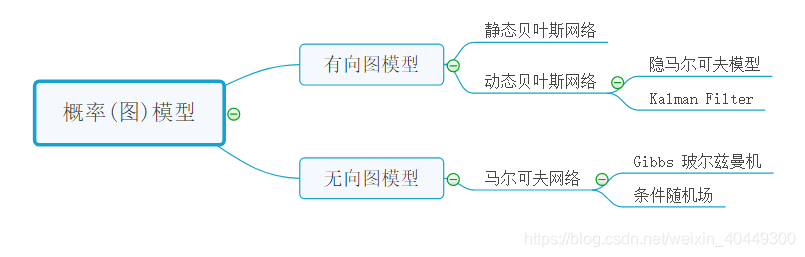
概率图模型中的术语图指的是图论,也就是带有边和点的数学对象。确切地说,概率图模型(Probabilistic Graphical Models,PGM)是指:你想描述不同变量之间的关系,但是,你又对这些变量不太确定,只有一定程度的相信或者一些不确定的知识。
贝叶斯概率图模型是有向图,因此可以解决有明确单向依赖的建模问题,而马尔可夫概率图模型是无向图,可以适用于实体之间相互依赖的建模问题。这两种模型以及两者的混合模型应用都非常广泛。条件随机场(CRF)广泛应用于自然语言处理(如词性标注,命名实体识别)。
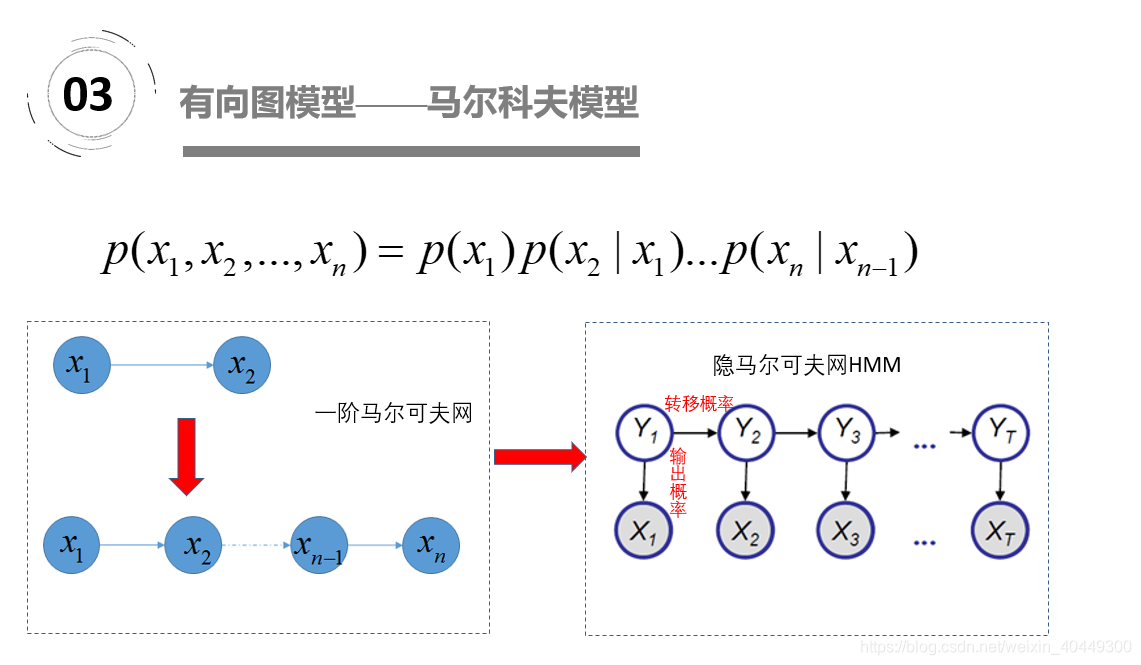
在马尔科夫链中,每一个圆圈代表相应时刻的状态,有向边代表了可能的状态转移,权值表示状态转移概率。 HMM,隐马尔可夫模型,是一种有向图模型。由1阶马尔可夫模型演变而来,不同之处在于我们能够观测到的量不是过程本身,而是与其有一定关系的另一些量。那HMM中的隐体现在哪呢?这里“隐”指的是马尔科夫链中任意时刻的状态变量不可见,也就是说状态序列Y1,Y2,...,,...,Yt无法直接观测到。但是HMM中每时刻有一个可见的观测值Xt与之对应.隐马尔可夫模型(HMM)是语音识别的支柱模型.
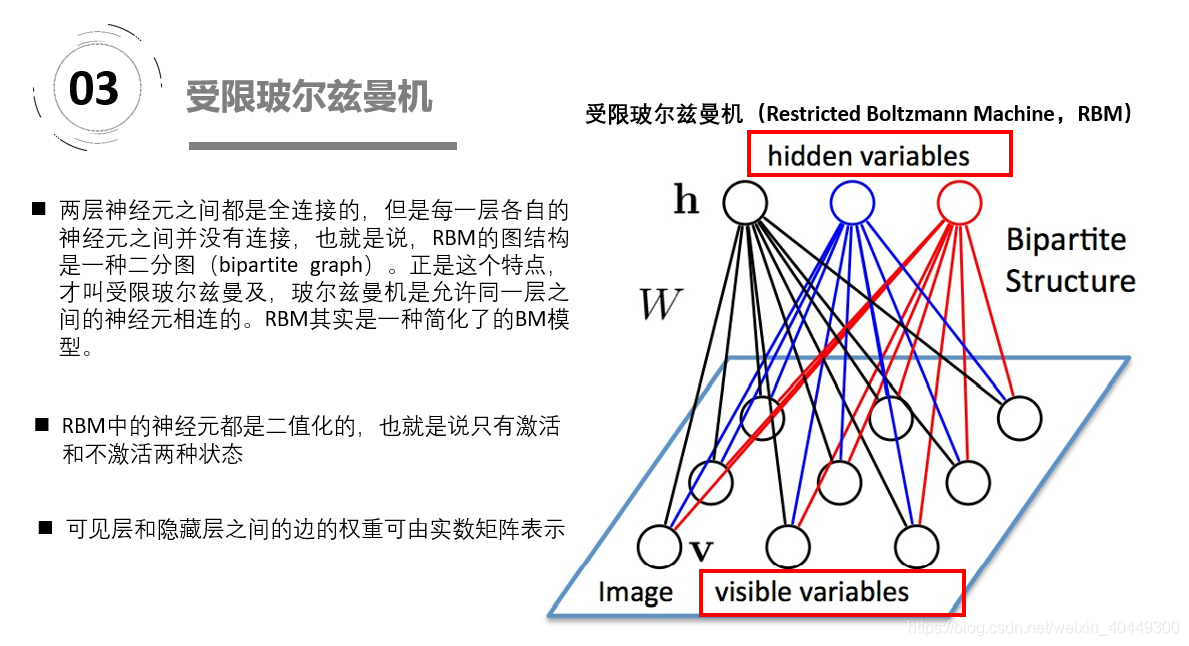
玻尔兹曼机是一大类的神经网络模型,但是在实际应用中使用最多的则是受限玻尔兹曼机(RBM)。受限玻尔兹曼机(RBM)能学习并发现数据的复杂规则分布,将多个RBM堆叠就构成了深度置信网络(deep belief network, DBN),从而可以从更加复杂的高维输入数据中抽取维数更低、区别度较高的特征。https://blog.csdn.net/u013631121/article/details/76652647

自动编码器文章:https://blog.csdn.net/u011584941/article/details/72673260
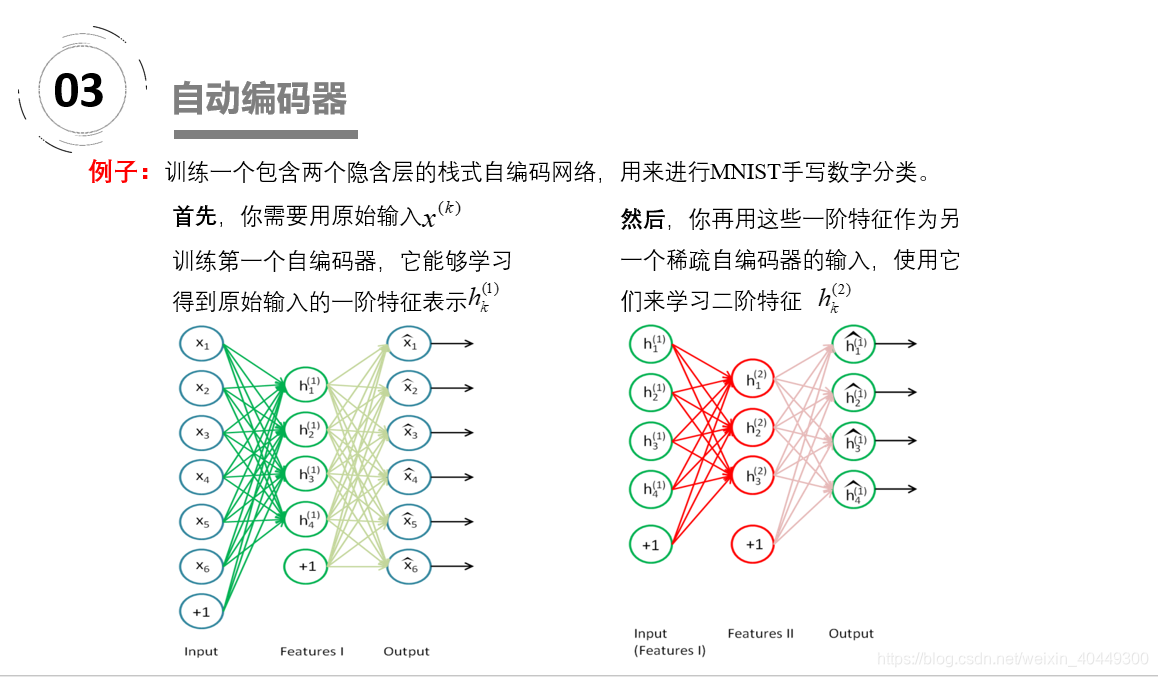
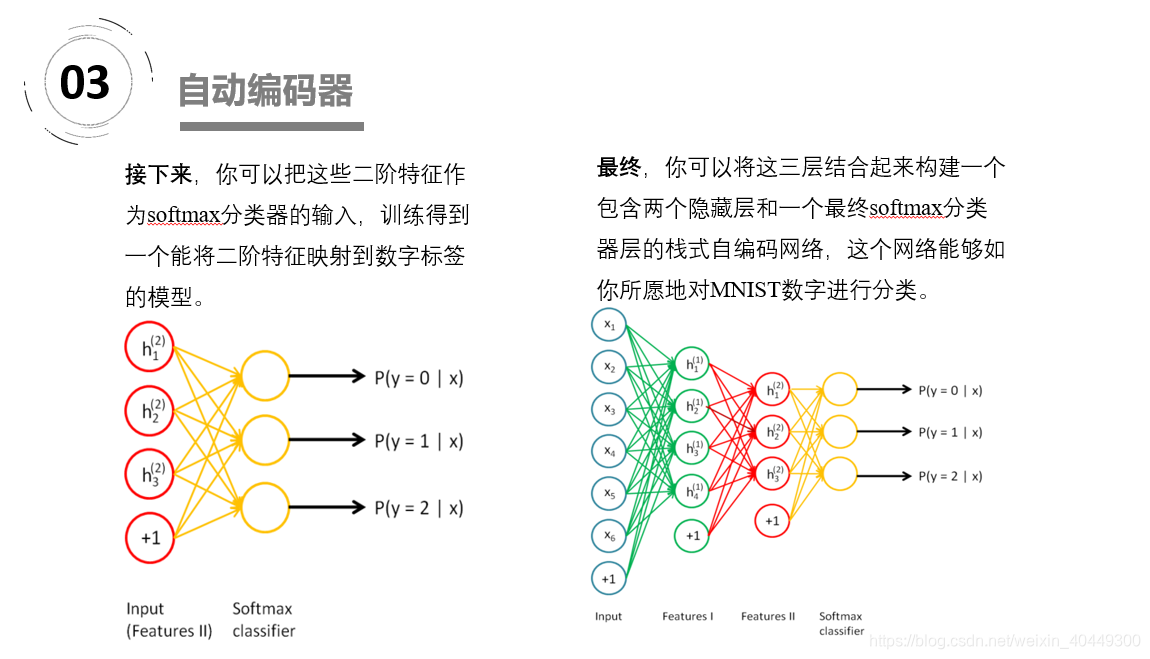
如上图,我们将input输入一个encoder编码器,就会得到一个code,这个code也就是输入的一个表示,那么我们怎么知道这个code表示的就是input呢?我们加一个decoder解码器,这时候decoder就会输出一个信息,那么如果输出的这个信息和一开始的输入信号input是很像的(理想情况下就是一样的),那很明显,我们就有理由相信这个code是靠谱的。所以,我们就通过调整encoder和decoder的参数,使得重构误差最小,这时候我们就得到了输入input信号的第一个表示了,也就是编码code了。因为是无标签数据,所以误差的来源就是直接重构后与原输入相比得到。
1、稀疏自编码:减小编码后隐藏层神经元个数。2、栈式自编码神经网络是一个由多层稀疏自编码器组成的神经网络,其前一层自编码器的输出作为其后一层自编码器的输入。采用逐层贪婪训练法进行训练,获取栈式自编码神经网络参数。3、去噪自动编码器DA是在自动编码器的基础上,训练数据加入噪声,所以自动编码器必须学习去去除这种噪声而获得真正的没有被噪声污染过的输入。所以他的泛化能力强。4、DAE是通过对输入添加随机噪声,经过编码解码来获得健壮的重构;而CAE对扰动的健壮性是通过惩罚 雅克比矩阵F范数各元素的和得到。CAE抓住内部因素提高特征提取健壮性,DAE通过外部因素提高特征提取健壮性。
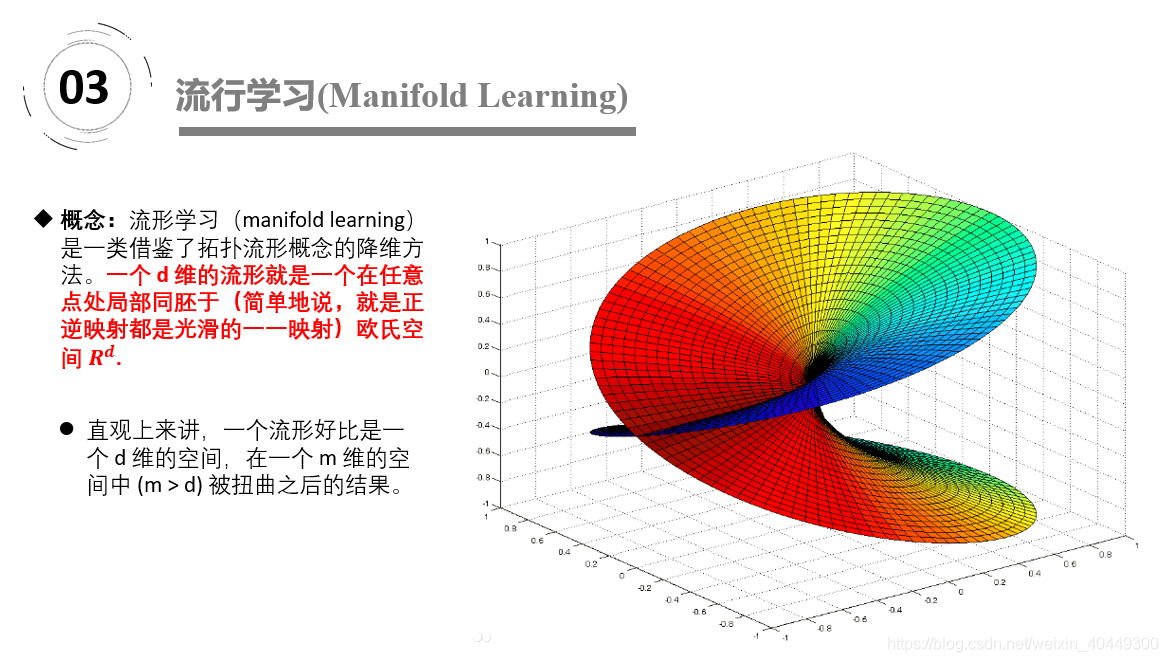
“流形”是在局部与欧式空间同胚的空间,换言之,它在局部具有欧式空间的性质,能用欧氏距离来进行距离计算。这给降维方法带来了很大的启发:若低维流形嵌入到高维空间中,则数据样本在高维空间的分布虽然看上去非常复杂,但是在局部上仍具有欧式空间的性质,因此,可以容易地在局部建立姜维映射关系,然后在设法将局部映射关系推广到全局。当维数被将至二维或三维时,能对数据进行可视化展示,因此流行学习也可以被用于可视化。直观上来讲,一个流形好比是一个 d 维的空间,在一个 m 维的空间中 (m > d) 被扭曲之后的结果。广义相对论似乎就是把我们的时空当作一个四维流(空间三维加上时间一维)形来研究的,引力就是这个流形扭曲的结果。
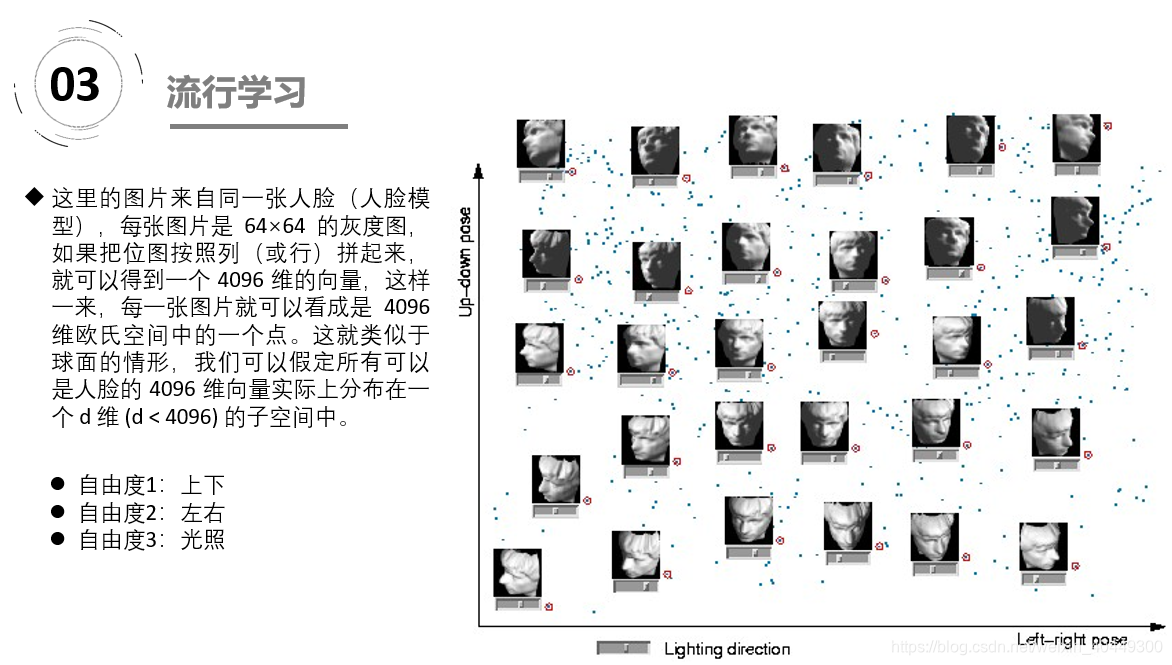
不过是在不同的 pose 和光照下拍摄的,如果把 pose (上下和左右)当作两个自由度,而光照当作一个自由度,那么这些图片实际只有三个自由度,换句话说,存在一个类似于球面一样的参数方程(当然,解析式是没法写出来的),给定一组参数(也就是上下、左右的 pose 和光照这三个值),就可以生成出对应的 4096 维的坐标来。换句话说,这是一个嵌入在 4096 维欧氏空间中的一个 3 维流形。

















 506
506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









